이 논문도 읽고 난 뒤에 정리하는 용도로 작성
주관이 들어갈 수 있음.
Abstract
offline RL은 environment와 직접적인 상호작용 없이 dataset을 통해서 강화학습을 진행하는 것이다.
이때 offline RL에 skill을 이용하는 경우가 있는데 action-state를 continuous embedding space로 추상화한 skill을 조합해서 진행하는 것이다.
이때 discrete skill은 아직 연구되지 않았다.
이 논문은 discrete skill을 이용해서 offline RL을 진행하는 방법을 제안하고 뛰어난 성능을 보임을 증명한다.
Introduction
- 핵심만 쓰겠다.
offline RL에서 사람이 복잡한 문제를 기존에 가지고 있는 skill(지식)을 조합해서 해결하는 것처럼 model이 continuous skill set을 조합해서 문제를 해결할 수 있도록 RL에 활용하는 시도가 있었다.
이때 skill은 VAE와 비슷한 구조로 dataset을 embedding 형식으로 만들고 이를 decoder로 state-action 들을 복구하는 low-level policy를 학습할 수 있다.
이제 RL dataset은 skill들로 바뀌었기에
이러면 high-level policy를 skill을 예측하게 학습할 수 있다. inference에서는 high-level policy가 skill을 고르고 low-level policy가 action을 진행하는 형식.
이때 기존에는 continuous embedding이었기에 gaussian N(0,1)이라는 constraint도 존재하고 skill set의 space가 무한하기에 내용을 이해하기 힘들었는데
이 논문은 discrete skill set을 활용하는 방법을 제시한다.
discrete skill set에서
encoder은 transformer encoder를 활용하고
decoder은 diffusion을 이용한다.
encoder이 어떻게 압축하는지는 논문을 봐도 모르겠다. BERT처럼 전체 sequence에 CLS token을 붙여서 진행하는건지...
decoder은 diffusion처럼 code, state를 받고 action을 생성한다.
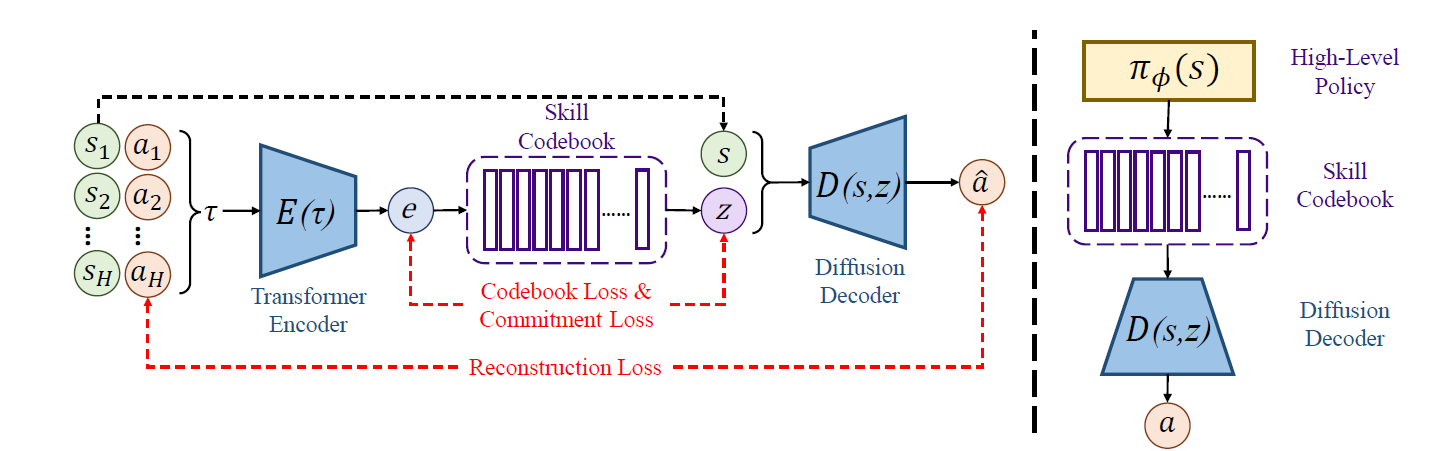
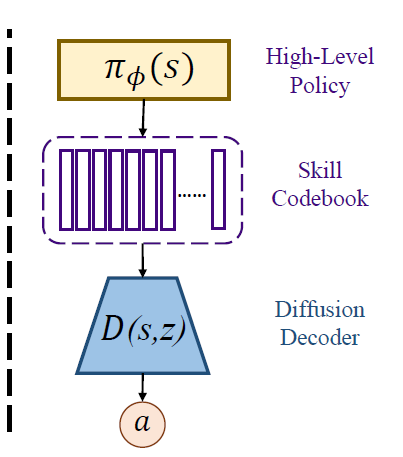
4. Discrete Diffusion Skills
4.1. Self-Supervised Skill Learning in Discrete Skill Space
위 그림을 보면 이해가 쉽다.
skill을 VQ-VAE 구조로 만든다.
encoder은 transformer encoder 구조를 활용하고 decoder은 diffusion인데 MLP의 구조를 활용해서 진행한다.
VQ-VAE를 알면 더 알 내용은 없는 것 같다.
이때 그림에서 이상한 부분은 수식에서는 가 주어지면 를 학습하게 하는데 위 그림에서는 이 주어지고 를 예측하는 이상하게 되어있다.
4.2. Relabel Offline Datasets with Learned Skills
앞에서 학습한 encoder를 활용해서 RL dataset을 H 길이만큼 sequence를 잘라서 skill set으로 만든다.
이때 sequence의 길이는 이고
로 H가 skill로 매핑된다.
는 다음 skill의 시작 state로 활용한다.
4.3. IQL for Offline Q-learning on Relabeled Datasets
그러면 앞에서 RL dataset이 으로 구성이 되는데
이 skill set sequence data로 high level policy를 학습한다.
state를 받아서 skillset을 예측하는 것이다.
4.4. Online Inference with Discrete Skills
inference에는 H step마다 skillset을 예측하고
각 action은 decoder가 현재의 skillset, state를 받아서 만든 action을 진행한다.