Abstract
vision transformer에 conditional positional encoding을 제시한 논문
기존의 방법은 fixed나 learnable한 positional embedding을 정해두고 사용을 하였는데
이 논문은 간단한 CNN을 통해서 유동적으로 positional embedding을 이미지에 따라 모델이 학습해서 적용할 수 있게 만들어주었다.
input size에 유동적인 CNN의 구조 덕분에 학습한 이미지 크기보다 더 큰 이미지에도 자연스럽게 일반화해서 positional embedding을 적용할 수 있다.
Introduction
최근 cnn대신 ViT와 같이 transformer기반 아키텍쳐가 더 좋은 성능을 보여주는데
순서에 관계 없이 처리하는 self-attention의 구조상 positional embedding이 필수이다.
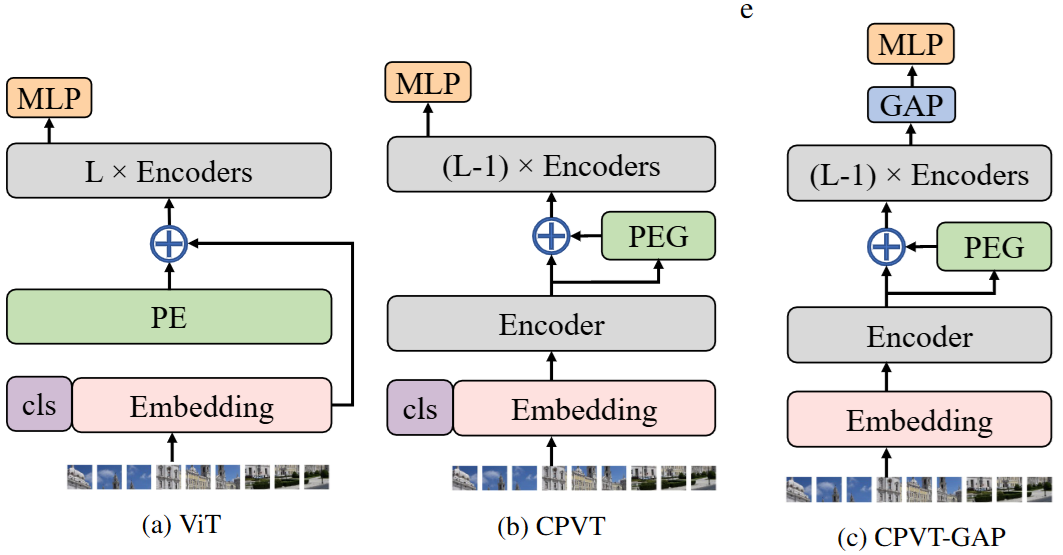 이전에는 위 그림처럼 absolute positional embedding을 각 token에 더해주고 encoder를 통과시켰는데
이전에는 위 그림처럼 absolute positional embedding을 각 token에 더해주고 encoder를 통과시켰는데
이 논문은 각 token에 따라 유동적으로 positional embedding을 생성해서 더해주는
Positional Embedding Generator(PEG)를 제시한다.
이렇게 학습함으로써 positional embedding에 유동성을 주고 학습한 이미지와 inference하는 이미지의 크기가 달라도 유동적으로 진행할 수 있다.
conditional positional embedding이 제공해야하는 기능은 다음과 같다.
- 유동적인 input size 처리가 가능하고
- 입력 token에 따라서 값이 바뀐다.
- 절대적인 position의 표현이 된다.
앞의 2개는 CNN의 기본 특징이고
뒤의 1개는 How much position information do convolutional neural networks encode?
이 논문에서 나왔다는데 대강 보니 CNN이 zero padding을 통해서 absolute position에 대한 정보도 학습을 한다는 것 같다.
3 VISION TRANSFORMER WITH CONDITIONAL POSITION ENCODINGS
3.1 MOTIVATION
motivation은 간단하다. 기존 positional embedding은 학습 가능하게 각 patch에 absolute position에 대한 정보를 주는데 여기에서 2가지 문제점을 제시한다.
- 학습한 length보다 더 길게 inference를 못한다.
- translation equivalence를 만족하지 않는다. 즉, input이 바뀌어도 똑같은 positional embedding이 더해진다.
translation equivalence가 중요한 이유는 equivalence가 성립하지 않으면 classification에서 object가 움직여도 정보를 주지 못한다고 한다.
이 부분은 잘 모르겠는게 position에 대한 정보랑 image에 있는 object의 정보는 어느정도 독립적으로 볼 수도 있지 않나?
간단하게 object의 위치에 대한 정보가 주어지면 좋겠지만
object가 뭔지에 대한 정보와 그 absolute에 대한 정보가 주어지면 이를 조합해서 얻을 수 있지 않나?
 위 표에서 첫번째는 positional embedding을 뺀 것이고 (첫번째 문제 해결...)
위 표에서 첫번째는 positional embedding을 뺀 것이고 (첫번째 문제 해결...)
두번째, 세번째는 absolute position에 대한 정보를 주는 것이다.
세번째는 relative position 정보를 주는 것인데 absolute 정보의 중요성을 보여준다.
3.2 CONDITIONAL POSITIONAL ENCODINGS
3가지 조건
- permutation variant, translation equivalence를 준다.
- 학습보다 긴 sequence를 다룰 수 있어야 한다.
- absolute position에 대한 정보를 줄 수 있어야 한다.
이 논문은 심플하게 3x3 CNN으로 해결한다.
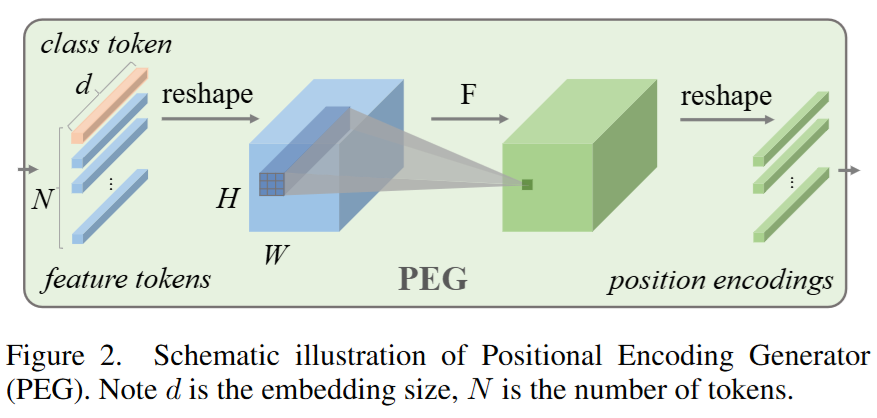 위와 같은 구조인데
위와 같은 구조인데
첫번째, 두번째는 cnn의 기본 특징이고 세번째는 zero padding으로부터 absolute position에 대한 정보를 학습한다는 이전 논문이 있다고 한다.
구현은 simple하게 다음과 같이 가능하다.
class PEG(nn.Module):
def __init__(
self,
dim
):
super().__init__()
self.ds_conv = nn.Conv2d(dim, dim, 3, padding = 1, groups = dim)
def forward(self, x):
b, n, d = x.shape
hw = int(math.sqrt(n))
x = rearrange(x, 'b (h w) d -> b d h w', h = hw)
x = self.ds_conv(x)
x = rearrange(x, 'b d h w -> b (h w) d')
return x
patch = patch + PEG(patch)설명하자면 (batch, seq, dim)으로 구성된 token을 다시 (batch, dim, patch_size, patch_size)로 바꾸고 dim to dim channel 3x3 cnn을 통과시킨 다음 다시 (batch, seq, dim)으로 돌리면 된다.
3.3 CONDITIONAL POSITIONAL ENCODING VISION TRANSFORMERS
위 그림처럼 positional embedding generator를 encoder에 붙이는 구조의 vision transformer를 제시한다.
GAP는 cls token을 안쓰고 GAP로 mlp 통과시키는 것.
Expreiments
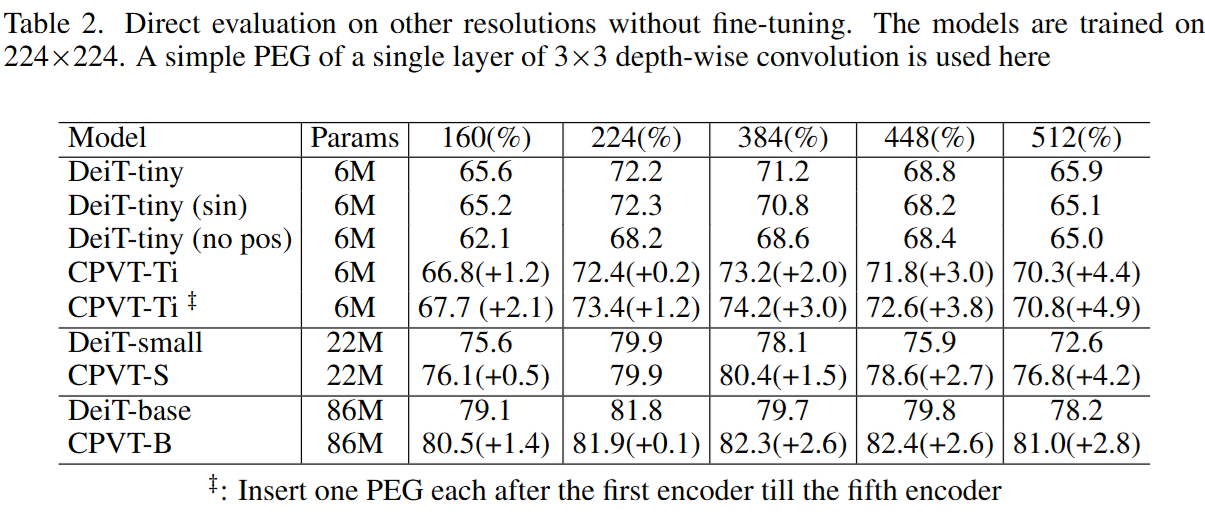 기존 방법과 비교해서 좋은 성능을 보여준다.
기존 방법과 비교해서 좋은 성능을 보여준다.
