사실 1~2년 전에 예전에 혼자 생각해본 구조인데 새롭게 논문으로 나왔길래 신기하기도 하고 재밌는 내용이 많아서 간단하게 블로그에 작성한다.
Introduction
논문을 다시 보기 힘들어서 간단하게 요약하자면 기존의 transformer 등의 아키텍쳐는 고정된 layer를 forward로 한번만 통과시킨다.
그런데 이 논문은 굳이 그럴 필요 있냐 이전에 RNN처럼 같은 layer를 여러번 통과시키는 구조가 있는데 그걸 쓰면 사람이 여러번 생각하는 것처럼 test time computation이 가능하지 않겠냐고 제시
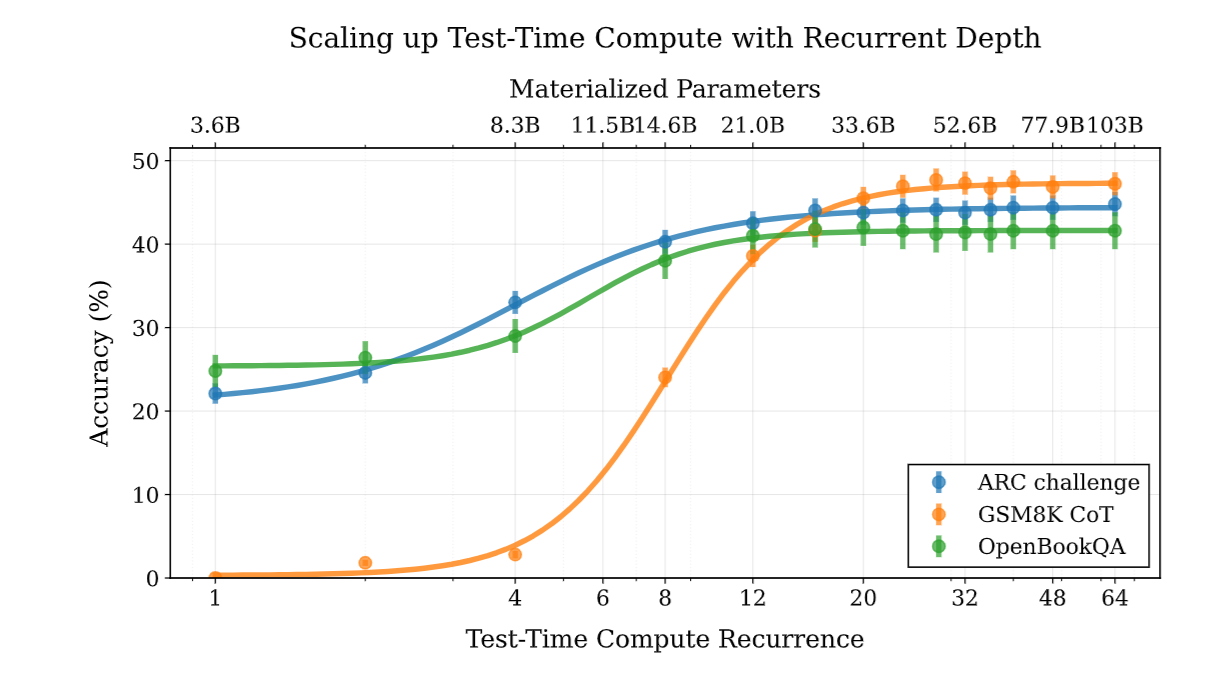 실제로 test time에 동일한 layer를 여러번 통과시켜서 computational cost를 많이 넣으면 성능이 매우 상승한다.
실제로 test time에 동일한 layer를 여러번 통과시켜서 computational cost를 많이 넣으면 성능이 매우 상승한다.
3. A scalable recurrent architecture
바로 구조 설명으로 들어가겠다.
사실 대부분 비슷한 내용이고 recurrent depth가 핵심인데
전체 구조는 다음과 같다.
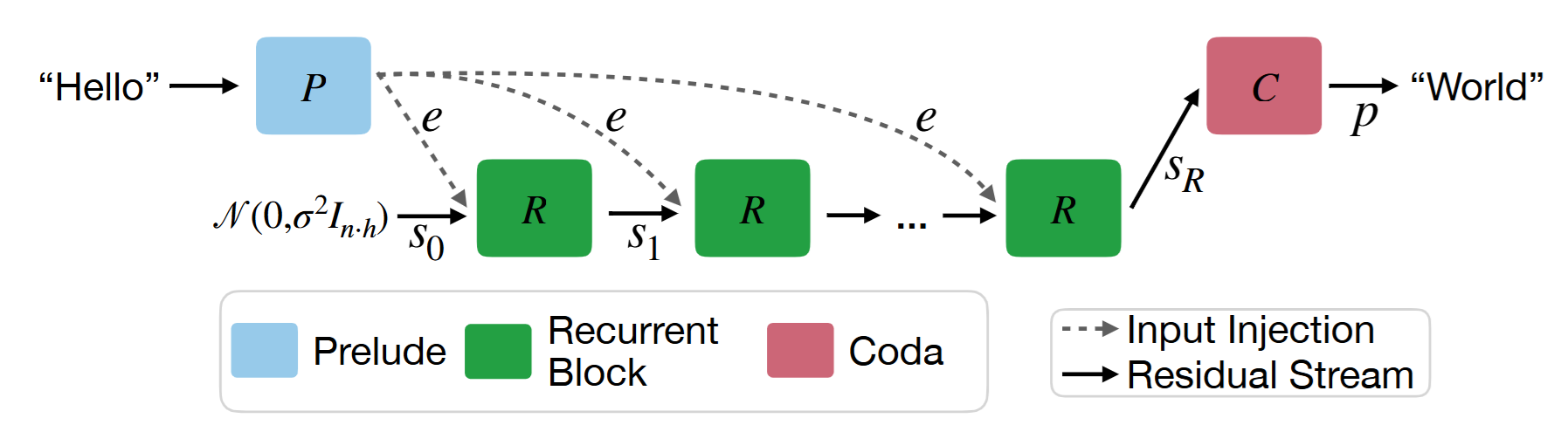 위 그림에서 P는 nn.embedding으로 token embedding 만들고 transformer layer를 몇번 통과시킨 것이고
위 그림에서 P는 nn.embedding으로 token embedding 만들고 transformer layer를 몇번 통과시킨 것이고
R은 recurrent layer'들' 이다.
C는 recurrent 통과시키고 transformer layer 몇개 통과하고 projection 해서 token 예측하는 부분이다.
사실상 R이 핵심이다.
수식으로 보면 이해가 더 쉬울 것 같은데
위와 같이 구성이 된다.
재밌는건 latent 를 normal 분포에서 뽑는데 이게 문제가 되지 않을까? 생각이 들었는데 이러한 구조가 path independent라는 성질을 만족해서
위처럼 다른 경로로 시작해도 도달하는 점은 일정하다고 한다.
이때 각 transformer layer는
처럼 normalization으로 감싸주는데 이렇게 해야 큰 모델의 recurrent 과정에서 학습이 잘 이루어진다고 한다.
기본적인 구조는 transformer에 RoPE를 사용하고 ,gated SiLU MLP, RMSNorm을 사용했다고 한다.
또한 처음 input을 embedding으로 만드는 과정에서 embedding layer도 처럼 학습가능한 param gamma를 붙여줘야 하고
그리고 Recurrent의
에서 은 더하는게 아니라 concat을 한 다음 adaptor를 통과해서
로 mapping을 해준다고 한다.
학습
학습은
로 임의의 recurrent number를 포아송 분포에서 뽑고 이를 토대로 예측한 값으로
autoregressive 하게 다음 token을 예측하는 식으로 진행된다.
는 token을 왼쪽으로 1번씩 당긴 것이다.(autoregressive 학습을 위해)
Trunacted backpropagation
학습 과정에서 recurrent 횟수마다 gradient가 계속 저장이 될건데 만약 계속 축적을 한다면 memory와 computation이 부담이 되기 때문에 최대 개수를 정해둔다
으로 설정하면 마지막 8번 반복의 gradient만 저장을 한다.
그럼 memory의 사용량을 일정하게 유지할 수 있다.
실제로 RNN 등의 학습에서 자주 사용한다고 한다.
학습 문제
학습 과정에서 그냥 기존 transformer처럼 쓰는데 특정 블록만 Recurrent처럼 다시 input을 넣어서 진행하면 되지 않나? 생각이 드는데
논문에서 아무렇게나 설정하면 학습이 제대로 되지 않는다고 한다.
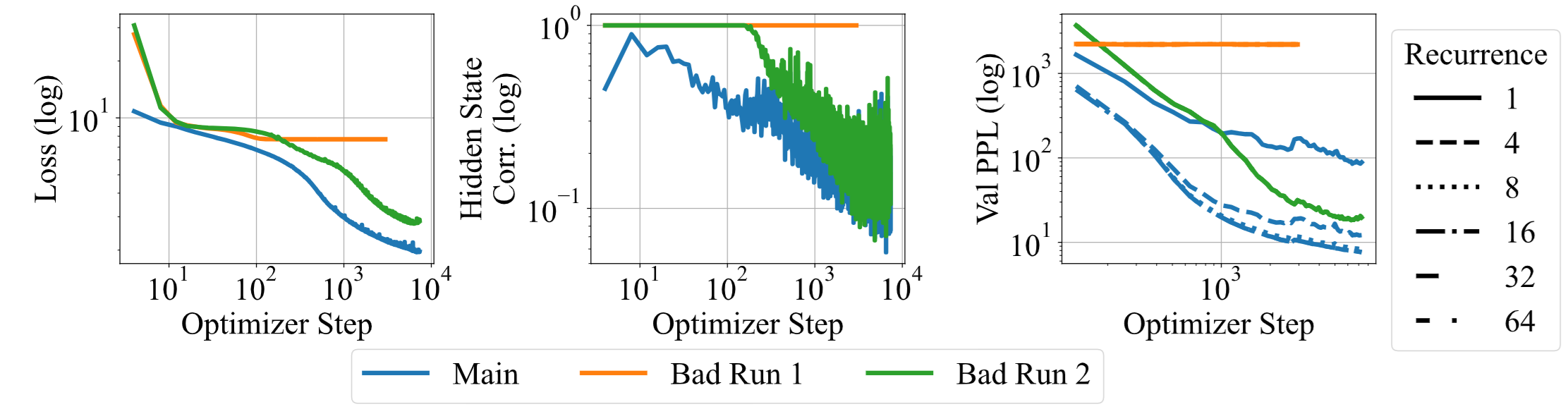 위 그림이 bad run1이 바로 그런 경우로
위 그림이 bad run1이 바로 그런 경우로
block 내부에 norm을 샌드위치처럼 하긴 했지만 RMSNorm layer을 param-free로 진행했고 embedding layer 를 넣지 않았고
adapter도 로 param을 주지 않았다고 한다.
그러면 위 그림에서 보다시피 loss가 직선으로 간다.
bad run2는 위 내용을 고치기 위해서 adapter를 학습 가능하게, embedding scaling factor를 넣었는데 Norm layer는 기존의 transformer처럼 pre-normalization만 넣었다고 한다.
그러면 학습은 이루어지는데 오른쪽 그림을 보면 Recurrence를 늘려도 성능 향상이 이루어지지 않는다.
마지막 Main은 다시 샌드위치 구조로 Norm을 복구하고 lr을 로 매우 낮게 주고 학습을 하니 정상적으로 진행이 되었다고 한다.
결과
 ARC 같은 reasoning에서 특히 비슷한 param model에 비해서 압도적인 점수를 보여준다.
ARC 같은 reasoning에서 특히 비슷한 param model에 비해서 압도적인 점수를 보여준다.
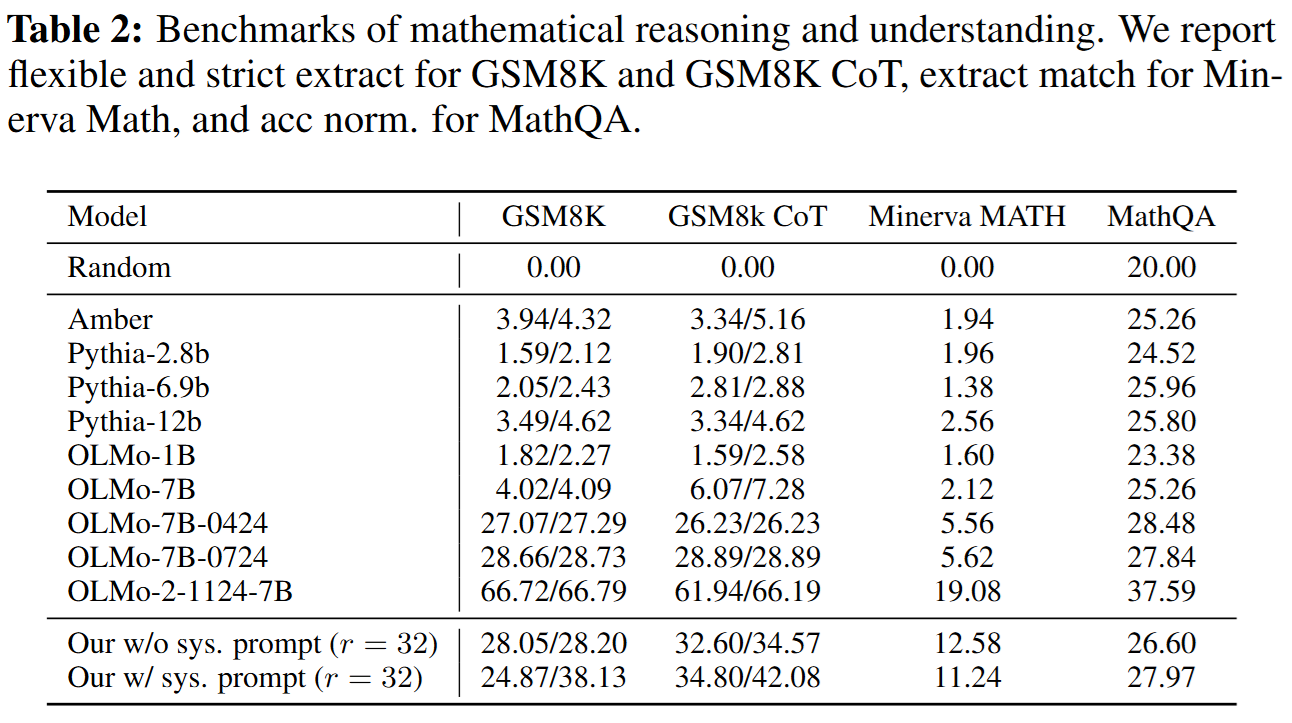 특히 재밌는건 reasoning 분야에서 비슷한 param의 model보다 훨씬 뛰어난 점수를 보여준다는 것이다.
특히 재밌는건 reasoning 분야에서 비슷한 param의 model보다 훨씬 뛰어난 점수를 보여준다는 것이다.
후기
조금 바빠서 핵심만 쓰다보니 너무 짧게 작성한 것 같은데
recurrent를 진행하면서 embedding이 움직이는 것을 보여주는 등의 다른 재밌는 부분도 많으니까 혹시 블로그 글을 보는 사람이 있고 관심이 있다면 논문의 내용을 읽어보길 바란다.
