[논문 리뷰]DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
paper
재밌는 내용이 많아서 다른 사람도 봤으면 좋겠어서 블로그에 올린다.
deepseek r1이 o1과 비교될만큼 뛰어난 성능을 얻었는데 어떻게 했는지 중점으로 다뤄보겠다.
우선 논문의 제목만 봐도 pure reinforcement learning으로 높은 성능을 얻었기에 r1-zero가 논문의 내용에서 제일 중요한 부분이기에 이를 중점으로 다루겠다.
Introduction
최근 test-time computation 등을 활용한 reasoning model이 뛰어난 성능을 얻고 SOTA의 성능을 보이는데
이 논문에서 보여주는 r1은 매우 재밌게도 pure reinforcement learning 만으로도 엄청나게 뛰어난 성능을 얻었다.
강화학습의 진행은 간단하게
수학 문제를 예시로 들자면
data 의 pair에서 를 주고 모델보고 알아서 를 생성하라고 하는 것이다.
그러면 생각의 prompt 형식만 맞춰주면 최종 답이 맞는지를 확인할수 있기에 이를 토대로 답이 맞으면 1점 틀리면 0점과 같은 식으로 강화학습을 진행할 수 있다.
뒤에 따로 자세하게 다루겠다.
개인적으로 STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning 논문과 되게 결이 비슷하다고 느꼈다.
star 논문은 의 데이터가 있으면 모델보고 만 보고 를 예측하라고 시키고 만약 가 틀리면 를 보여주고 를 생성하게 시켜서
그렇게 구축한 데이터로 supervised lenaring을 진행하였을 때 성능이 상승되었다는 이야기이다.
즉 스스로의 reasoning 성능을 토대로 점점 성장하는 것이다.
학습 방법이 강화학습이냐, supervised learning이냐의 차이일 뿐이지 결국 하는 내용은 비슷하다고 생각한다.
그러나 pure 강화학습을 진행하면 language mixing(중국어 영어 섞여서 나옴), readability(가독성) 저하 등의 문제로 cold start(fine tune data 추가) 등 따로 처리가 필요하다.
method(rl)
방법론
우선 강화학습 방법론은 GPPO를 활용했다고 한다.
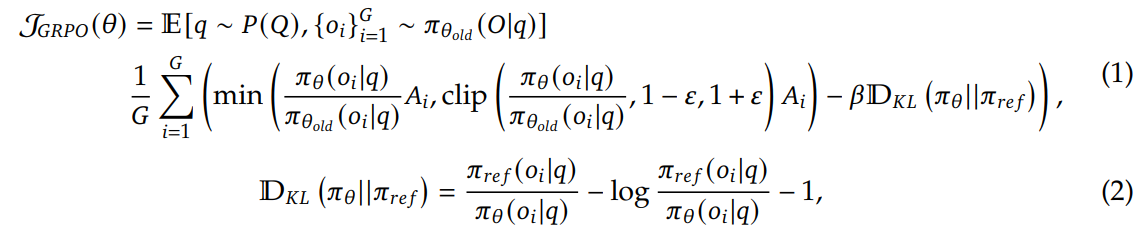 수식은 위 그림과 같은데
수식은 위 그림과 같은데
PPO와 거의 비슷한데 group이 들어간 모습이다.
우선 reward에 대해서는 나중에 이야기하고 advantage는 다음과 같다.
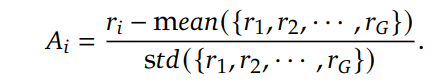 advantage는 group 전체의 reward를 가지고 normalization을 한 것이다.
advantage는 group 전체의 reward를 가지고 normalization을 한 것이다.
GPPO 수식은 critic model을 진행하지 않고 ppo를 진행하는 것으로 생각되는데
prompt를 sampling을 진행한 다음 각 group의 model을 가지고 output을 만든다.
이후 계산한 advantage를 가지고 각 model에 대해서 PPO를 진행하는 것으로 생각하면 편할 것 같다.
reward
 reasoning prompt template는 위와 같다.
reasoning prompt template는 위와 같다.
<think>가 각각 들어가서 생각을 나타내고 <answer>로 결과를 나타내게 하는 prompt이다.
reward는 크게 2가지로 구성이 되는데
우선 짚고 넘어가야할게 reinforcement leanring은 reasoning에 중점을 두기 때문에 수학, 코딩, 추론 등의 분야로 구성이 되어서 답이 딱딱 정해져 있다. 그렇기에 rule-based로 답을 알 수 있다.
그래서 다음과 같이 reward가 구성이 된다.
- accuracy rewards: 특정 specified format에 있는 final answer의 정답이 맞냐 틀리냐
- format rewards: 답변의 format이 위에서 말한 <think>, <answer>등의 format을 만족하냐.
간단하게 출력한 format이 맞으며 최종 정답이 맞냐 틀리냐? 만가지고 강화학습을 진행한 것이다.
어떻게 답을 만드는지는 모델의 선택이다.
성능
사실 진짜 재밌는 부분인데
저렇게 답이 맞냐 틀리냐? 를 가지고 강화학습을 진행하였을 때
성능이 매우 뛰어나게 향상이 되었다.
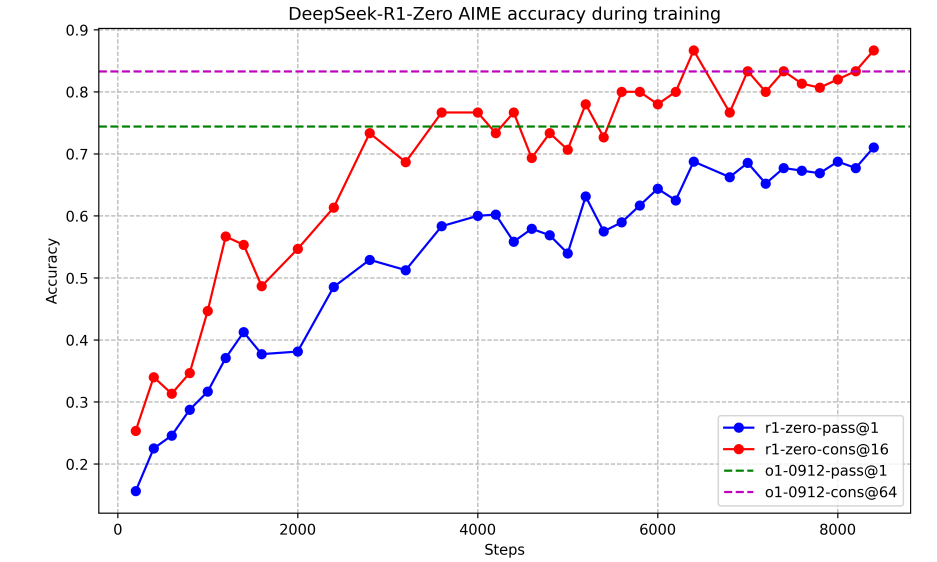
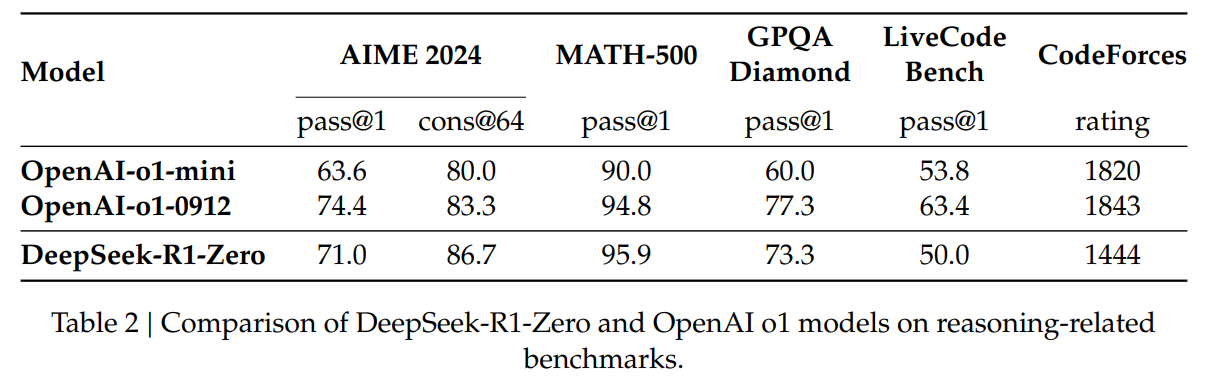
AIME 2024 즉,수학에서 기존 15.6%에서 71.0%가 되었고 o1과 비슷한 성능을 내었다.
COT
진짜 재밌는 부분은 rl을 진행하면 할수록 성능이 계속 상승하였고
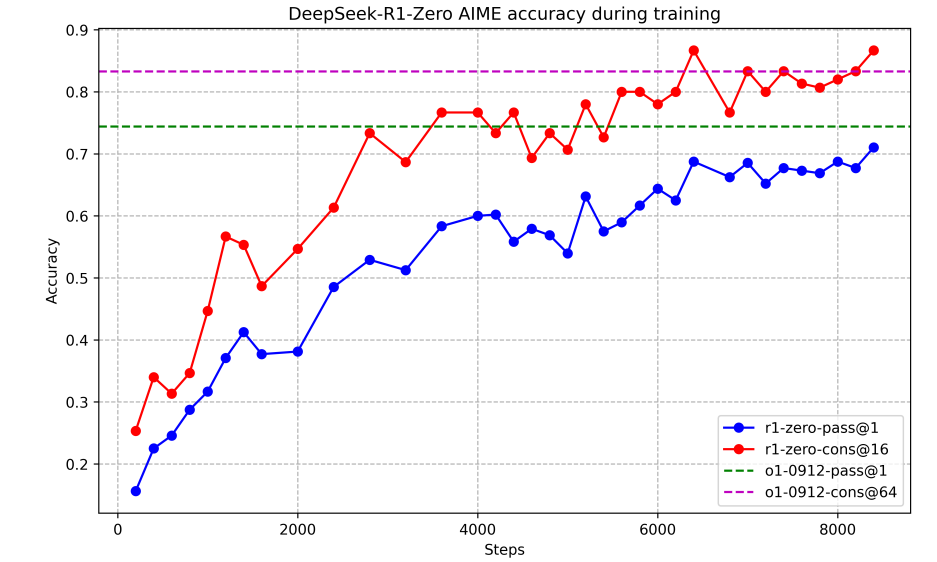
아래 그림과 같이 점점 생각에 많은 토큰을 사용하기 시작한다.
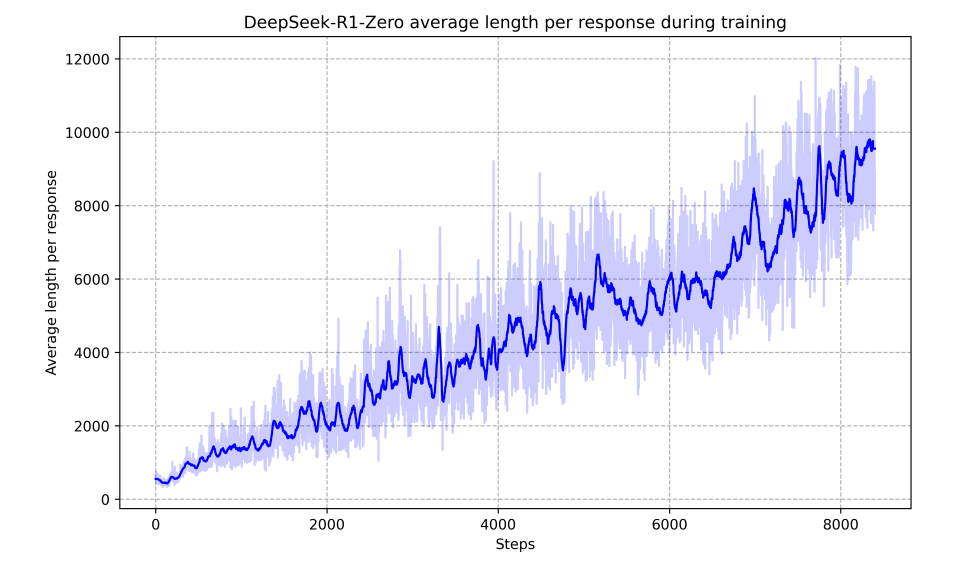
이는 사람이 기존에 COT와 같이 supervised learning으로 추론의 길이를 늘리는 것이 사실 자연스러운 흐름이라는 것을 보여주기도 한다.
reward is enough 논문의 내용이 생각난다.
문제의 정답을 맞추려고 하다보니 자연스럽게 생각을 많이하게 되는 것이다.
Aha moment
또 재밌는건 아하 모멘트라고 모델이 현재 진행하고 있는 내용이 잘못되었다는 것을 깨다는 것을 보였다는 것이다.
이것도 사실 진짜 신기한 부분인데
 위 그림과 같이 문제를 푸는 도중에 처음 생각했던 접근법이 잘못되었다는 것을 깨닫고 다시 시도하는건데 이러한 부분은 기존의 이전의 context에서 다음 token을 예측하는 autoregressive model이 보여주기 힘든 내용이다.
위 그림과 같이 문제를 푸는 도중에 처음 생각했던 접근법이 잘못되었다는 것을 깨닫고 다시 시도하는건데 이러한 부분은 기존의 이전의 context에서 다음 token을 예측하는 autoregressive model이 보여주기 힘든 내용이다.
왜냐하면 autoregressive model은 SFT로 학습하게 된다면 이전의 sequence가 무조건적으로 맞을 거라고 생각을 하고 next token을 predict하게 학습하기에 이렇게 이전의 sequence가 틀릴 것이라고 생각하기 어렵다.
문제점
그러나 강화학습을 하였을 때 문제점이
- language mixing: 이 부분은 답 부분만 체킹이 되기에 중간에 어떻게 생성할지는 전적으로 model에게 있기에 아무렇게나 언어를 섞었는 문제가 발생
- readability: 위와 같은 내용과 비슷하게 reasoning process를 제대로 읽을 수 없다.
method(R1)
이 부분은 강화학습의 단점을 어떻게 보완해서 R1 model을 구축할지 설명하는 부분이다.
사실 중요하진 않아보여서 간단하게 다루겠다.
cold start
간단하게 기존에는 바로 RL을 돌렸는데 이번에는 COT format을 맞춰서 fine-tune을 하고 RL을 진행하는 것이다.
이를 통해서 COT의 readability를 늘릴 수 있을거라고 기대.
- 또한 이후 RL 진행할때 target language의 비율 등으로 reward를 조정해서 COT 과정에서 language mixing을 막기 위한 조치를 함.
rejection sampling
RL 학습한 모델이 reasoning이 증가하였을 테니 이를 가지고 단점을 완전히 없앤 뛰어난 모델을 만들기 위해서 SFT data를 모은다.
- reasoning data: reasoning data는 rejection sampling을 진행. 그러니까 안좋은 데이터는 버리고 좋은 데이터만 골라서 SFT에 사용하기 위해서 저장 이때 좋고 안좋고는 reward를 생성하는 모델을 따로 활용하였다고 함.
reasoning 과정에서 language mixing 등 오류가 나면 제거 이를 통해서 60만개 데이터 모으기 성공 - Non-reasoning data: 글쓰기, 역할극 등 일반적인 데이터는 Deepseek v3의 sft 데이터 일부를 다시 사용했다고 함. 이때 v3의 pipe line을 재활용 했다는데 이건 잘 모르겠고 RL model은 현재 reasoning 특화라서 그런지 이 데이터는 v3로 cot prompt를주고 생성하게 만들어서 구축한 것으로 보인다. 이를 통해 20만개 데이터 모으기 성공
총 80만개 데이터 구축 성공
다시 rl
위에서 구축한 80만개의 데이터로 다시 base model을 SFT 학습을 진행하고 rl을 진행한다. 이때에는 reasoning의 초점이 아니라 helpfulness, harmlessness가 중점이다.
llama2의 학습 내용이 생각난다.
reward signal은 다양한 내용을 섞어서 진행하고 prompt를 다양하게 진행.
- reasoning data의 경우 처음 RL reward로 진행
- general data의 경우 human preference를 학습한 reward model로 진행하였다고 함.
helpfulness의 경우 final summary에 중점을 둬서 진행했다고 하며 harmlessness의 경우 전체 답변을 평가해서 문제가 있는지 중점을 두고 평가했다고 함.
아마 llama2 처럼 reward model을 위 helpfulness와 harmlessness로 학습해서 평가한 것으로 보임.
distillation
앞에서 구축한 80만개 데이터로 작은 모델 학습해도 좋은 성능 나왔다고 한다.
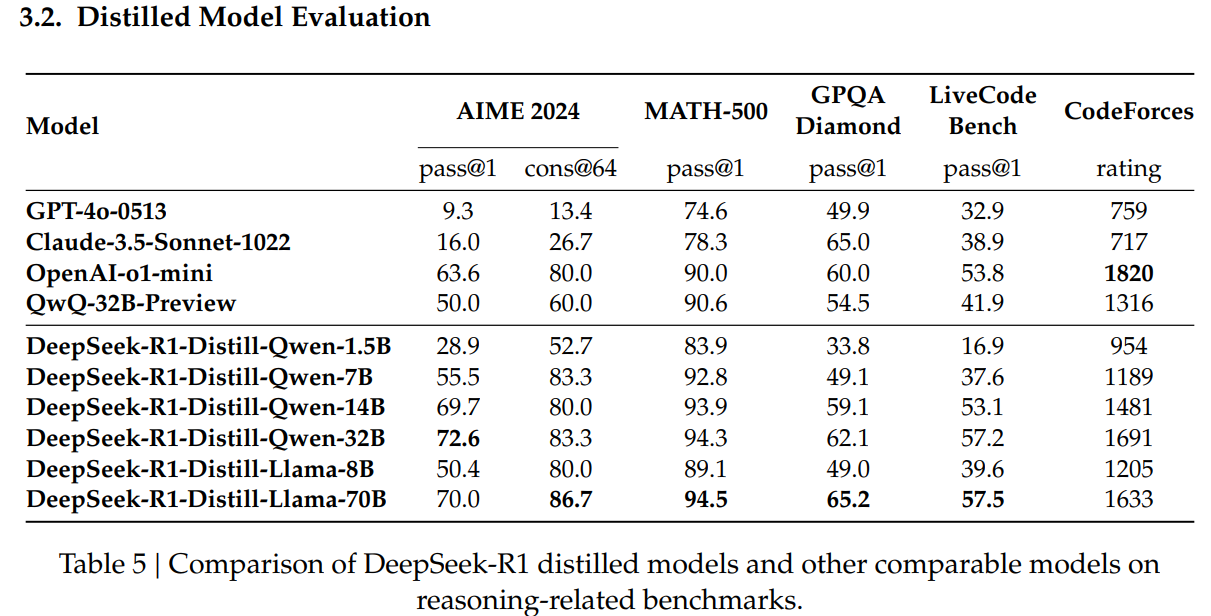
결과
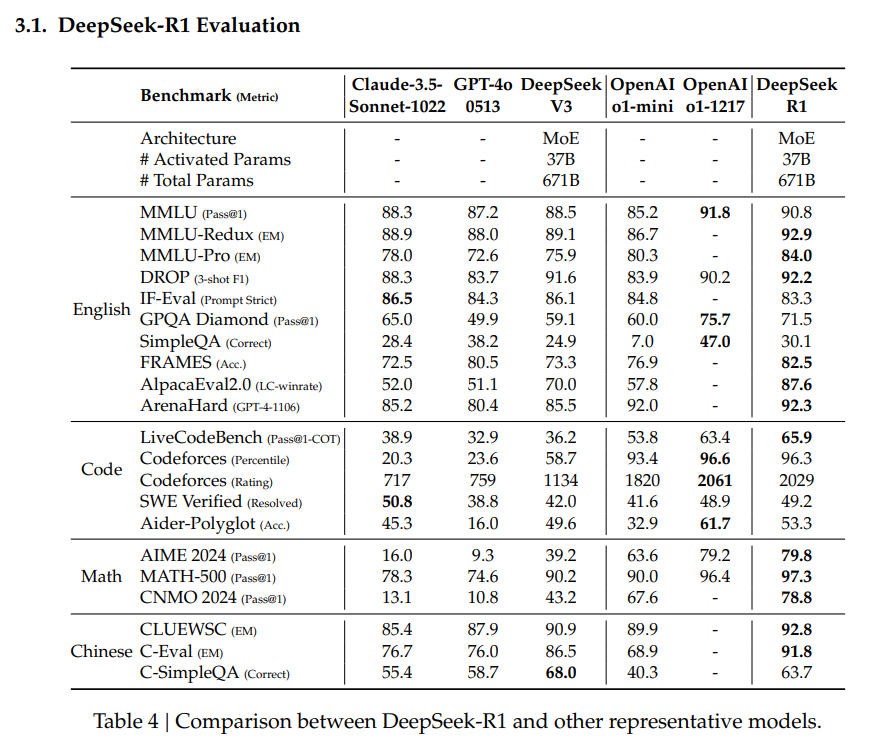 o1 모델과도 비슷한 성능을 보이며 매우 뛰어난 모습을 보임.
o1 모델과도 비슷한 성능을 보이며 매우 뛰어난 모습을 보임.
