Abstract
supervision 없이 유용한 representation을 학습하는 것은 key challenge이다.
이 논문은 discrete representation을 학습하는 generative model VQ-VAE를 소개한다.
VAE와는 2가지로 다른데
- encoder의 output이 continuous가 아니라 discrete한 code이다.
- prior이 static하지 않고 학습된다.
discrete한 quantised vector으로부터 시작되는 과정에서 posterior collapse를 막을 수 있다.
posterior collapse는 autoregressive decoder가 너무 강력해서 latent를 무시하는 것
즉 autoregressive 상황에서 latent에 상관 없이 이전에 생성된 데이터만 가지고 생성하는 것...
1 Introduction
기존은 maximum likelihood와 reconstruction error를 학습하는 것이 unsupervised의 목표였는데 이러한 방법은 특정 application feature에 제한이 된다.
이 논문은 maximum likelihood를 최적화 하는 동시에 data의 중요한 feature를 최대한 보존하는 것이 주요 목표인데 동시에 discrete하고 useful한 latent를 학습하는 것이다.
discrete한 representation은 다양하게 사용될 수 있기에 중요하다.
nlp의 tokenizer와 같은 기능을 이미지에도 사용할 수 있기 때문.
vector quantisation을 이용하지만 VAE와 비슷한 성능을 내는 VQ-VAE를 소개한다.
VQ-VAE는 Noise에 신경을 쓰지 않고 중요한 feature에 집중을 할 수 있다. (가장 많이 나타나는 feature 등)
vector quantisation이 되기 때문에 unsupervised learning으로 latent structure를 발견할 수 있다.
speech의 경우 word, 형태소 등의 정보 없이 latent structure를 발견할 수 있다.
그렇기에 말하는 content를 바꾸지 않고 목소리를 바꿀 수 있다고 한다.
3 VQ-VAE
이 논문의 내용은 VAE와 가장 연관이 있는데 encoder network는 posterior distibution 을 parameterise하는데 는 latent variable, 는 input data이다.
prior distribution은 이고
decoder은 이다.
prior과 posterior은 prior은 사전 분포, 그냥 그 확률 그대로이고 posterior은 사후분포이다. x가 주어졌을 때의 z확률 분포.
3.1 Discrete Latent variables
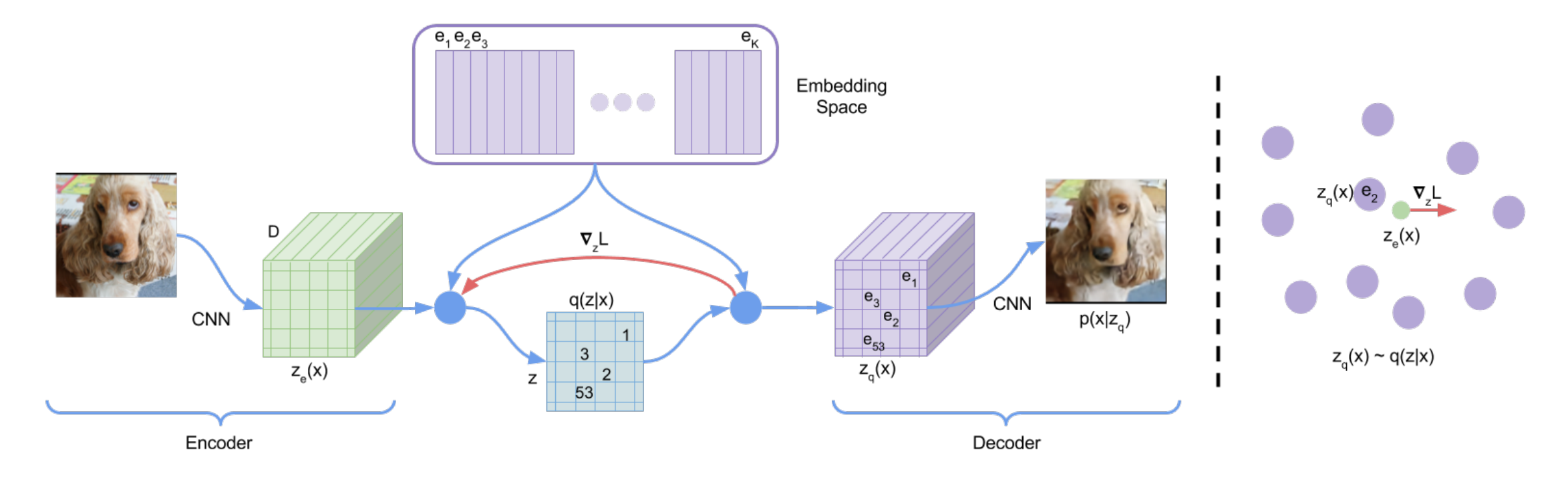 위 그림처럼 진행이 되는데
위 그림처럼 진행이 되는데
우선 latent embedding space 의 code를 정의한다.
K는 code의 크기이고 D는 embedding의 크기.
encoder는 로 input을 받고 output을 받는데
위와 같이 squared error가 가장 작은 code를 index를 one-hot으로 고른다.
결국
위와 같이 바뀐다.
이때 중요한 부분이 논문에서는 자연스럽게 넘어가는데
이미지가 만약 128x128x3을 encoder로 32x32xd로 바꿨다고 하자 그럼 32x32xd를 바로 code로 바꾸는 것이 아니라
로 flatten한 다음 각 d에 대해서 가까운 code를 찾아서 바꿔주는 것이다.
즉 전체를 code로 바꾸는 것이 아니라 부분부분 나눠서 code로 바꿔주는 것.
이렇기 때문에 그 code들의 순서, 분포를 pixelCNN으로 학습해서 code를 생성해서 decoder에 넣고 이미지를 생성하는 것이 가능하다.
실제 코드 구현에서는 다음과 같이 구현이 된다.
"""
quantization pipeline:
1. get encoder input (B,C,H,W)
2. flatten input to (B*H*W,C)
"""
# reshape z -> (batch, height, width, channel) and flatten
z = z.permute(0, 2, 3, 1).contiguous()
z_flattened = z.view(-1, self.e_dim)
# distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
d = torch.sum(z_flattened ** 2, dim=1, keepdim=True) + \
torch.sum(self.embedding.weight**2, dim=1) - 2 * \
torch.matmul(z_flattened, self.embedding.weight.t())3.2 Learning
위에서 gradient는 straight-forward로 진행
gradient는 흐르면서 decoder에서 encoder로 전달이 되는 과정에서 reconstruction을 진행하기 위해서 유용한 정보를 담고 있음.
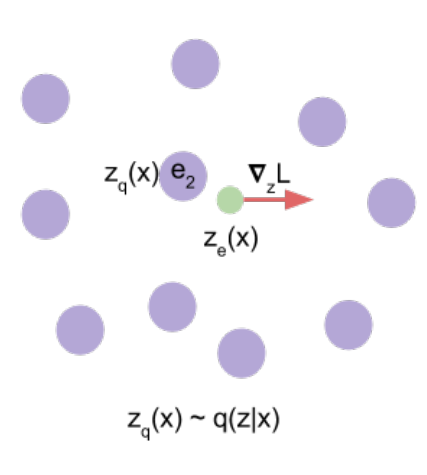 위 그림처럼 gradient를 낮추기 위해서 encoder의 output vector를 낮추는 방향으로 이동.
위 그림처럼 gradient를 낮추기 위해서 encoder의 output vector를 낮추는 방향으로 이동.
위처럼 loss가 구성이 되는데
- 첫번째 항: reconstruction loss. decoder와 encoder를 최적화
- 두번째 항: 위 loss로는 에 gradient가 흐르지 않기에 Vector Quantisation term으로 embedding vector 를 로 이동
- 세번째 항: embedding space가 엄청 크기 때문에 가 encoder param만큼 빨리 학습이 안될 수 있기 때문에 encoder의 속도를 조절해주기 위한 term을 마지막에 두었다.
decoder은 첫번째 term만 최적화하고
encoder은 첫번째와 3번째 term만 최적화
embedding은 두번째 term만 최적화
는 robust해서 0.1에서 2.0까지 바꿔도 크게 바뀌지 않는데
논문에서는 로 설정해서 진행.
log-lokelihood는
로 볼 수 있는데
decoder 가 로만 학습이 되기 때문에 는 확률을 하나도 할당할 필요가 없다.
그렇기 때문에
로 근사할 수 있다.
3.3 Prior
discrete latent 의 prior distribution은 categorical distribution이다.
이를 다른 z들에 대해서 autoregressive하게 만들 수 있는데
auto regressive하게 만드는 것은 과 같이 여러개의 확률 곱으로 만드는 것을 의미
학습 시에는 constant, uniform하게 prior을 구성하고 이후에는 auto regressive distribution에 fit하게 학습을 하면
학습된 embedding을 활용해서 를 생성할 수 있다.
이때 prior과 codebook은 다른 개념이기에 prior을 고정한다는 것은 codebook을 고정하는 것과는 다르다. codebook의 embedding은 학습될 수 있다.
어떤 code가 뽑힐지를 균등하게 유지하는 것.
이렇게 학습된 code를 가지고 autoregressive하게 학습을 진행하는 것
4 Experiments
4.2 Images
이고 로 진행
 위 그림의 오른쪽이 32x32x1에서 복구한 것인데 생각보다 매우 잘된다. 그러나 약간 뿌옇게 보인다.
위 그림의 오른쪽이 32x32x1에서 복구한 것인데 생각보다 매우 잘된다. 그러나 약간 뿌옇게 보인다.
pixelCNN과 code들의 분포로 생성하는 것이 있는데
PixelCNN은 CNN을 이용해서 1pixel씩 auto regressive하게 생성하는 것이고
수많은 이미지를 encoding하면 32x32x1로 구성된 code들을 얻을 수 있는데 pixelCNN을 이용해서 code들의 분포를 학습한 다음 VQ-VAE의 decoder를 이용해서 복구하는 식으로 생성한다.
