이 논문 리뷰는 혼자 공부하면서 빠르게 본 내용인데 흥미로워서 중요한 부분만 블로그에 남긴다.
요약
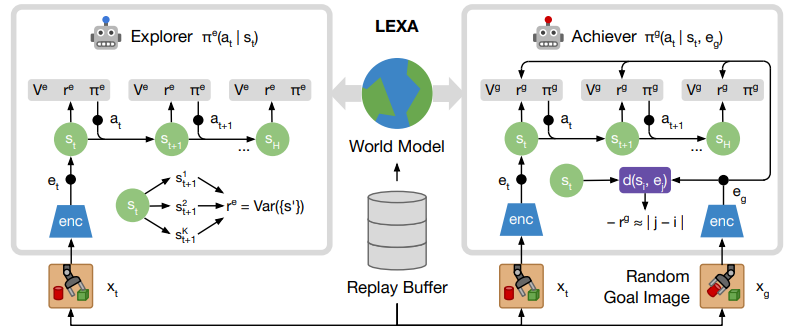
앙상블을 통해 var을 증가시키게 학습해서 더 많은 탐색을 하게하는 explorer(rnd와 비슷)와
특정 sample된 image를 goal로 설정하고 goal을 achieve하기 위해서 학습하는 achiver을 학습한다.
이 논문을 보면서 사진을 goal로 학습하는 것을 처음 보았다.
2개의 policy를 바탕으로 dreamer와 같이 학습하는 구조가 흥미로웠다.
Abstract
인공지능 agent가 supervision 없이 문제를 푸는 방법이 무엇일까?
이 논문은 2단계로 agent가 새로운 goal을 찾고 이를 안정적으로 achieve하는 방법을 찾기 때문이라고 봄.
위 가설을 바탕으로 Latent Explorer Achiever(LEXA)를 제시하는데 각 문제를 world model을 학습하고 이를 통해서 explorer과 achiever를 학습해서 해결하였다고 함.
1 Introduction
rl agent는 explorer를 통해서 새로운 goal을 찾고싶은데 보통 이전의 방법은 replay buffer를 사용하기 때문에 sampled된 goal은 agent의 경험의 근처에 있다.
그러면 경험하지 않은 goal은 어떻게 찾을 수 있을까?
이는 rl뿐만 아니라 인지과학에서도 매우 어렵고 마주하고있는 큰 질문이다.
이 논문은 학습된 world model을 explorer과 achiever policy 2개를 사용해서 imagination을 진행한다.
- explorer은 imagination 속에서 high expected information gain을 얻을 수 있는 state를 찾게 학습이 된다. 이후 실제 world에서 적용이 되어 현재 찾지 못한 goal을 찾도록 학습
- achiever은 이렇게 explorer가 찾아온 goal을 target으로 학습을 한다.
이러한 방법으로 매우 높은 성능을 얻었다고 함.
2 Latent Explorer Achiever (LEXA)
world model은 dreamer에서 다룬 world model과 구조가 동일하다(RSSM).
2.2 Explorer
world model은 unseen situation 등 replay buffer의 내용보다 더 많은 state를 예측할 수 있기에 replay buffer만 보는 model free 모델들 보디 imagined trajectory는 더 많은 novel goal을 담을 수 있다.
위는 explorer의 구성.
가장 informative state를 탐색하기 위해서 transition function을 앙상블로 학습해서 disagreement를 측정한다.
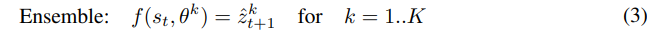 이때 앙상블은 학습되지 않은 transition에 대해서는 각각 다른 답을 내기 때문에 disagree가 커지게 된다.
이때 앙상블은 학습되지 않은 transition에 대해서는 각각 다른 답을 내기 때문에 disagree가 커지게 된다.
이 내용은 다른 강화학습 논문에서 본 적이 있는데
Exploration by Random Network Distillation (RND)이라는 논문이다.
간단하게 random 초기화된 network를 2개를 각각 만들고 점점 학습을 통해 둘의 출력을 비슷하게 만든다.
둘의 차이가 클수록 안가본 곳이기에 탐색할만하고 둘의 차이가 작을수록 가본 곳이기 때문에 탐색할 필요가 없다.
이제 이렇게 측정한 disagree를 reward로 explorer가 다양한 탐색을 하도록 만든다.
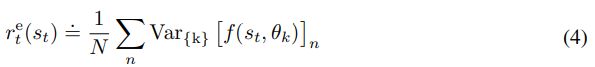 reward는 앙상블 예측으로 나온 model state의 dim에서 분산의 평균이다.
reward는 앙상블 예측으로 나온 model state의 dim에서 분산의 평균이다.
explorer은 이렇게 information gain을 위주로 학습을 하면서 다양한 탐색을 시도한다.
2.3 Achiever
explore를 통해서 얻은 정보를 활용해서 goal achiever policy를 학습한다.
데이터를 효율적으로 활용해서 general agent를 학습하기 위해서는 1개의 goal을 바탕으로 한 trajectory를 재활용해서 다른 goal을 얻을 방법을 학습하는게 중요한데 기존의 방법은 relabeling을 통해서 활용하였기에 off-policy로 진행이 되었다고 한다.
이 논문에서 achiver는 과거의 trajectory를 활용하는 것이 아니라 이를 학습한 world model을 활용해서 generation 방식으로 제한 없이 새로운 trajectory를 그때그때 생성해서 학습하기에 on-policy로 학습이 진행이 된다.
achiever는 state만을 받는 explorer와는 다르게 model state와 goal image의 embedding을 input으로 받는다.
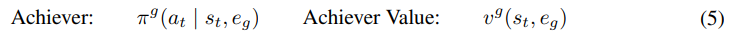
achiver는 goal reaching reward (아래에서 설명)를 최대화 하는 것을 목표로 학습한다. dreamer 알고리즘을 바탕으로 학습이 진행된다.
policy와 value가 goal을 받는데 이를 통해서 실제 environment의 goal trajectory에서 inaccuracy가 발생할 수 있는데 이를 agent가 바로잡을 수 있다고 한다.
2.4 Latent Distances
achiver를 학습하기 위해서는 latent state 가 goal 랑 얼마나 가까운지 measure가 되어야 한다.
간단한 방법은 goal image의 embedding을 world model에 넣어서 만든 latent state의 cosine sim인데 이는 문제가 시간적으로 멀리 있는 state도 시각적으로 유사하면 묶일 수가 있다.
이런 편향은 대부분의 pixel이 직접 제어가능한 상황에서만 유효하게 작동하게 만든다.
cosine distance는 단순하게 화면에 큰 로봇과 작은 물체가 있을 때 전체 goal image와 유사하게 match하려고 하기 때문에 큰 로봇에만 집중을 하고 작은 물체는 무시할 수도 있다.
이 논문은 그래서 cosine distance 대신 한 이미지가 다른 이미지로 이동하는데 필요한 시간 단계 수를 거리로 사용한다.
그렇게 된다면 큰 로봇이 있어도 time distance가 멀기 때문에 작은 object에 좀 더 집중할 수 있다.
이런 temporal cost는 imagination rollout으로부터 학습이 된다고 한다.
Cosine Distance
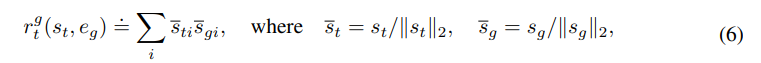 위와 같은데 latent state 와 inference network q에 image embedding 를 넣어서 나온 를 이용해서 진행한다고 하는데 inference network를 어떻게 구성했는지는 나오지 않는다.
위와 같은데 latent state 와 inference network q에 image embedding 를 넣어서 나온 를 이용해서 진행한다고 하는데 inference network를 어떻게 구성했는지는 나오지 않는다.
Temporal Distance
time step netword 를 2개의 embedding 사이의 time step을 예측하도록 학습한다. 이때 학습은 achiever의 imagined rollout에서 sampling된 pair 와 의 거리를 예측하는 식으로 진행된다. 이때 recurrent한 정보의 영향을 지우기 위해서 predicted 된 embedding을 통해서 학습이 진행된다.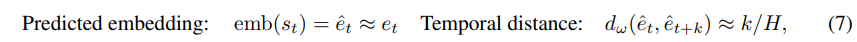 H는 imagination horizon의 maximum distance이다.
H는 imagination horizon의 maximum distance이다.
이때 주의해야할 부분이 imagination data로부터만 distance를 학습하게 된다면 접근 가능한 trajectory만 학습하기 때문에 다른 trajectory에서 오는 state는 예측을 제대로 못하게 된다.
멀리있는 goal의 signal도 통합하기 위해서 다른 trajectory의 image를 가져와서 negative sample로 사용한다.
그리고 이러한 negative sample은 maximum distance로 표시한다.
- distance의 음수가 reward이기 때문에 maximum이면 최소 reward
- reward를 최대화 하기에 거리를 줄이도록 agent는 학습한다.
그래서 agent가 항상 동일한 trajectory에서 본 이미지를 선호하게 만들어서 경로를 벗어나지 않게 만든다.
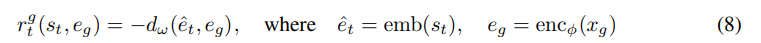
Lexa는 on-policy이기에 점점 정확하게 되고 빠르게 수렴하게 된다고 한다.
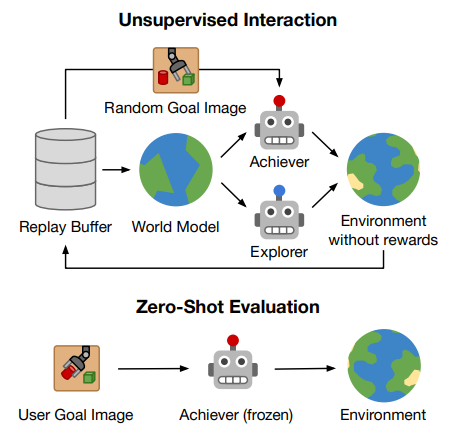
전체 구조

위 내용을 바탕으로 그린 그림이다.
explorer은 앙상블을 바탕으로 var을 크게하도록 진행해서 다양한 탐색을 하고
achiever는 distance metric을 바탕으로 goal으로 가기 위해서 학습한다.
 위 내용은 LEXA의 알고리즘이다.
위 내용은 LEXA의 알고리즘이다.
Experience
요점만 다룰 예정인 post이기에 생략한다.
