요약
transformer의 attention을 틀어서 latent를 중심으로 attention을 하는 방법을 제시한 논문.
Abstract
머신러닝에서 중요한 목표는 다양한 도메인의 다양한 문제를 풀 수 있는 system을 만드는 것이다.
그러나 현재의 architecture은 작은 domain, task에서도 적은 setting에서만 적용이 가능하다.
이 논문은 Perceiver IO를 제시하는데 이는 general-purpose architecture이고 arbitrary setting의 data를 handling이 가능하고 input, output에 따라서 scaling 역시 가능하다.
Perceiver은 유동적인 querying 방식을 통해서 various output이 가능하고 task-specific engineering이 더이상 필요가 없다.
동일한 구조로 다양한 분야에서 뛰어난 성능을 보임.
심지어 GLUE 언어 벤치마크에서 transfomer based의 모델 BERT를 이겼다.
1 INTRODUCTION
사람은 다양한 source의 데이터로부터 다양한 정보를 통합하고 처리할 수 있다.
그러나 대부분의 머신러닝은 특정 task를 위해서 구조가 정해져 있음.
이는 multi modal을 하는 모델도 마찬가지로 보통 각각의 domain을 처리하는 architecture를 각각 구성해서 붙이는 식으로 진행이 된다.
이런 구조는 input과 output이 복잡해질수록 모델이 점점 복잡해지게 된다.
그리고 task에서 input과 output의 구조가 data의 처리 방법을 엄청나게 제한하게 된다.
vision-language multi modal의 경우 잘은 모르지만 LLAVA의 경우에서
image를 patach를 encoder를 이용해서 잘라서 각각 encoding한 다음 그 뒤에 글자의 token을 붙여서 처리를 하는 것으로 알고 있다.
이러한 구조의 한계점을 지적.
이 논문은 1개의 모델로 여러개의 modality를 처리할 수 있는 구조를 제시함.
기존에 다양한 modal을 처리할 수 있음을 보여준 Perceiver를 업그레이드한 Perceiver IO인데 기존의 Perceiver는 간단한 output 즉 classifiaction만 가능했던 반면에 다양한 domain의 task를 처리할 수 있는 domain agnostic한 Perceiver IO를 제시함.
Perceiver IO는 attention으로 구성이 된 read-process-write의 구조를 가짐.
input이 latent space로 encoding(read)되고 latent representation이 refine(process)되고 decoder(write)가 output을 만드는 구조이다.
3 THE PERCEIVER IO ARCHITECTURE
사실 transformer와 비슷한데
- model은 정보를 embedding 단위의 feature vector로 구성된 것을 input으로 받는다. 이를 latent array를 이용해서 encoding하고
- latent에서 self-attention을 수행하고
- output도 굉장히 독특한데 input과 동일하게 output vector를 활용해서 attention을 적용해서 결과를 얻는다.
그림으로 보면 이해가 쉽다.
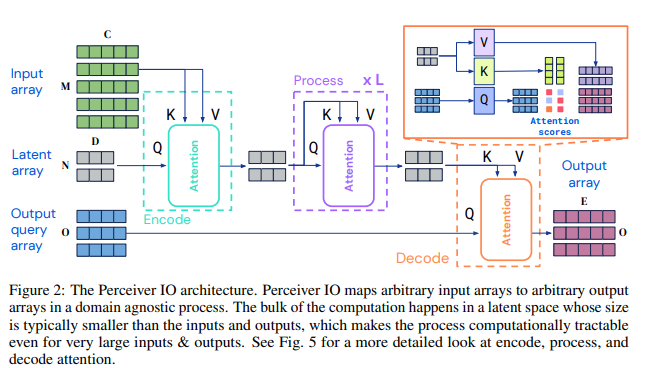 input에 우리가 넣는 embedding이 들어가고
input에 우리가 넣는 embedding이 들어가고
latent array와 output query array에는 학습 가능한 embedding이 들어가서 위와 같이 구성이 된다.
3.1 ENCODING, PROCESSING, AND DECODING
input array 를 로 attention을 활용해서 mapping하는 식으로 encoding한다.
(위 그림의 encoding 과정)
그다음 latent 를 self-attention을 통해서 처리한다.
마지막으로 로 mapping을 해서 decode한다.
- 위의 는 task마다 다르고 매우 클 수도 있다.
- 는 hyperparam으로 구성
각 attention module은 Global Query-Key-Value와 MLP로 구성이 된다.
encoder와 decoder이 신기한데 각각 encoder은 latent를 query로, 나머지는 key-value로 받아서 query를 중심으로 통합한다.
decoder은 output query latent를 중심으로 latent를 key-value로 통합한다.
이러한 구조는 transformer와 매우 비슷한데 왜 이걸 사용할 이유가 있을까?
transformer는 모든 모듈이 동일하게 구성이 되는데 full input을 사용해서 query, key, value를 만들고 진행하기 때문에 각 layer는 제곱으로 memory, compute 요구치가 증가한다.
이러한 단점 때문에 preprocessing 없이는 transformer를 high-dim data에서 사용할 수 없다.
심지어 NLP에서도 transformer는 tokenizer등을 통해서 적은 dim으로 많은 정보를 담게 preprocessing이 필요하다.반면에 Perceive IO는 latent에 input을 담고 latent 위주로 attention이 진행이 되기 때문에 input, output의 제곱이 아니라 latent size의 제곱으로 고정이 된다.
이러한 장점으로 Perceive IO는 high-dim의 domain에 좋은 결과를 보였다고 한다.
이러한 구조로 Perceive IO는 input과 output이 다른 shape를 가지는 구조에 활용할 수 있다.(sound or video)
3.2 DECODING THE LATENT REPRESENTATION WITH A QUERY ARRAY
목표는 의 구조로 구성된 latent representation으로부터 로 구성된 output array를 만드는 것이다.
task에서 각 출력이 특별한 의미를 가질 수 있기에 이러한 정보를 query에 담을 수 있게 만들어줘야 한다.
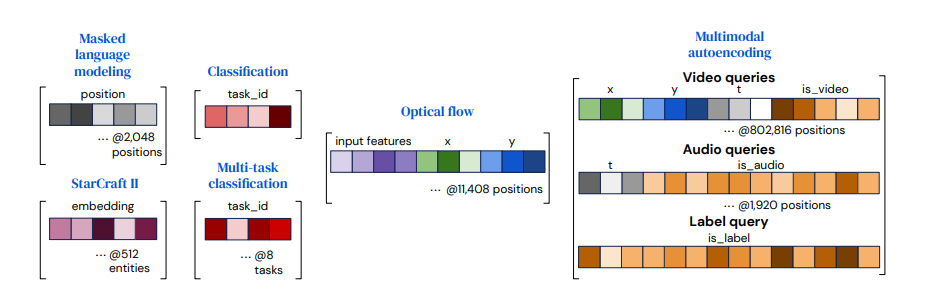
- output query는 각 output에 적절한 정보를 가져야 한다.
- 직접 디자인 될 수도 있고 학습된 embedding이 될 수도 있고 간단한 함수의 형태가 될수도 있다.
- vector들을 결합(concat or add)해서 output과 관련된 정보를 포함하게 함.
Query의 구조는
- task마다 다른데 classification과 같이 간단한 경우 쿼리는 모든 example마다 재사용이 가능하고 처음부터 학습될 수 있다.
- spatial or sequence 구조라면 position encoding을 추가한다.(learned positional encoding or Fourier feature)이를 통해 구조를 표현
- multi modal의 구조라면 각 task, modal에 필요한 query를 학습한다. 이를 이용해서 positional embedding처럼 network가 task나 modality를 구별할 수 있다.
- 다른 task의 경우 output이 input의 내용을 반영해야 한다. flow의 경우 input feature을 output query에 포함하는 것이 좋았다고 함.
4 EXPERIMENTS
다양한 분야에서 실험(nlp, visual, multi-modal 등등)
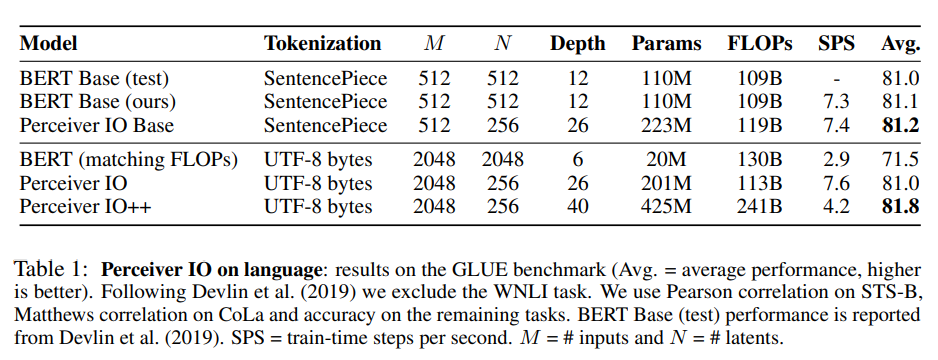 language 분야에서는 GLUE 점수 기준 BERT보다도 좋았다고 함.
language 분야에서는 GLUE 점수 기준 BERT보다도 좋았다고 함.
근데 사실 perceiver는 더 많은 param을 사용해서 100% 정량적인 비교는 힘들고 language도 잘한다고 생각하면 좋을 것 같다.
pretraining은 MLM으로 영어 위키, C4 학습으로 진행했다고 함.
나머지는 생략
