요약
기존 강화학습이 temporal bootstrap을 통해서 자신의 value를 토대로 섞어서 학습을 하는 것처럼
MCTS를 통해서 자신의 현재 policy보다 더 나은 action 분포를 찾아낸 다음 이를 학습하는 식으로 스스로 학습하는 방법이다.
알파고에서 사람의 knowledge를 지우고 MCTS만 가지고 스스로 학습을 하였을 때 더욱 좋은 성능이 나왔음을 보여준다.
이는 supervised learning이 결국 사람의 지식을 토대로 학습이 되었기에 어느정도의 bound가 존재함을 보여주고 사람을 뛰어넘을 수 있는 강화학습의 장점을 보여준다고 생각한다.
추가로 신의한수 라는 바둑 영화에서 마지막 장면에 어린아이가 바둑을 배우면 수의 방법이 자유로워서 상대하기 몹시 힘들고 기묘하게 잘한다는 이야기가 나오는데
아무런 지식이 없는 상태에서 학습하는 알파고 제로와 비슷하다고 생각한다.
실제로 알파고 제로도 사람이 모르는 더 나은 수를 발견하였다고 한다.
Abstract
인공지능의 오래된 목표는 사람의 지식 없이 스스로 처음부터 학습해서 사람을 뛰어넘는 것이다.
최근 알파고는 바둑에서 Tree search를 이용해서 사람을 뛰어 넘었는데 이때 SL policy는 사람의 바둑 기보를 통해서 학습이 되었다.
이 논문은 사람의 데이터, 지도, 도메인 지식 없이 강화학습 만을 사용해서 학습하는 알고리즘을 제시한다.
알파고를 스스로 학습하게 만드는 것이다.
스스로 move을 고르도록 하고 게임의 승자를 예측하도록 학습하게 된다.
이러한 결과로 알파고 제로는 알파고를 100대 0으로 이길 수 있었다.
Introduction
superviesd learning은 좋은 성능을 보이지만 데이터를 구하기 비싸고 학습되는 데이터가 ceiling 즉 오히려 천장이 될 수 있다.
그러나 최근 강화학습으로 사람을 뛰어넘는 deep neural network가 나오고 있다.
이 논문은 강화학습 만으로 사람을 이기는 알파고 제로를 제시한다.
기존 알파고와 차이점은 다음과 같다.
- 강화학습 만을 이용
- 기존에는 사람이 정제한 feature이 들어갔지만 오로지 흑돌, 백돌만 들어간다.
- 기존의 policy와 value 대신에 single neural network만 사용
- single neural network를 사용하기에 monte carlo rollout을 하지 않고 간단한 tree search를 사용해서 position을 evaluate하고 move를 sampling
1 Reinforcement Learning in AlphaGo Zero
network는 로 표현이 되고 input state 를 받고 move probability와 value를 반환한다.
p는 move 할 확률이고 v는 현재 player가 이길 확률이다.
즉 policy와 value를 통합한 것.
학습 방식은 간단하다. MCTS를 이용한 후의 move probability와 value가 기존의 probability와 value보다 더 정확해진다는 사실을 이용한다.
위 network를 이용해서 self-play를 하는데 각 position s에서 MCTS를 진행한다.
그러면 policy 즉 더 정확해진 policy가 나오게 되는데 이를 이용해서 policy iteration을 진행한다.
policy iteration은 policy의 evaluation, policy train을 반복하는 것.
value는 마지막 결과를 가지고 학습을 진행한다.
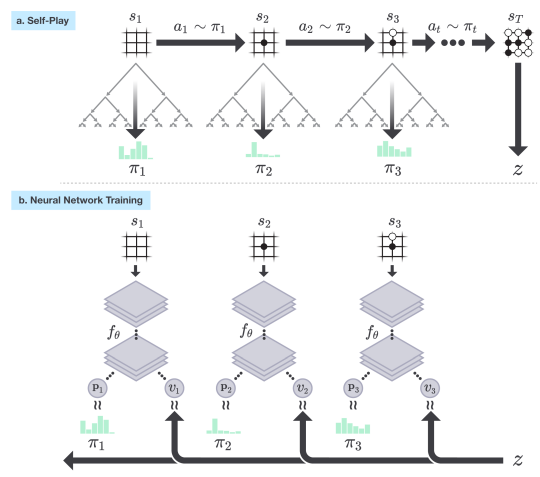 그림으로 보면 위 그림과 같다. MCTS로 를 구하고 이를 학습다. value는 결과 z를 가지고 학습.
그림으로 보면 위 그림과 같다. MCTS로 를 구하고 이를 학습다. value는 결과 z를 가지고 학습.
MCTS는 이전과 비슷한데 를 통해서 진행이 된다.
나머지는 이전과 동일한게 각 edge (s,a)는 prior probability 와 visit count 그리고 action value 를 가지고 있다.
이후 가 최대인 것으로 이동하는데 이때 이다.
이렇게 leaf node에 가면 을 구해서 계속 붙이고 다시 root로 돌아오면서 action value와 visit count를 더해주는 식으로 진행
자세한건 이전에 쓴 알파고 논문 리뷰 참조.
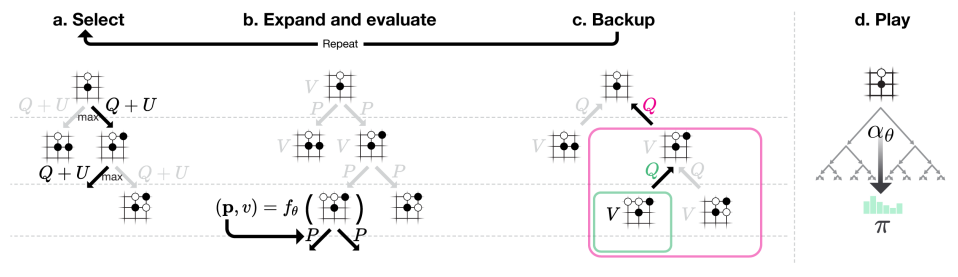 위 그림인데 사실 알파고와 동일한데 rollout이 없다.
위 그림인데 사실 알파고와 동일한데 rollout이 없다.
rollout이 없어도 어느정도의 성능은 나올 것 같긴하다. 이전에 알파고 실험에서 나오기도 했지만 점점 후반으로 갈수록 value가 정확해지기 때문에 MCTS로 후반의 상황을 미리 생각해보고 이를 앞으로 가져오는 식으로 진행이 되면 지금 상황의 value보다 더 정확해질 것이기 때문.
행동의 분포 와 같이 표현이 되는데 간단하게 이전 알파고 처럼 visit한 count의 비율에 비례해서 확률이 증가하게 된다.
하지만 이제 Simclr 등에서 학습할 때와 마찬가지로 너무 확률이 비슷비슷하면 성능이 떨어질 수 있기에 temparature를 주어서 확률의 차이를 조금 더 벌려준다.
결국 학습을 정리하면 다음과 같다.
- neural network를 random inint으로 초기화 한다.
- 각 step마다 MCTS로 확률 분포를 만드는데 로 이전 iteration의 neural net을 통해서 분포를 만든다.
- 게임은 두 player 모두 search value가 특정 threshold보다 낮아서 pass하게 되거나 게임이 너무 길어지면 종료. 게임 score는 -1이나 +1
- 각 데이터는 로 저장. 는 AI 입장을 기준으로 선택
- last iteration의 data 에서 uniform하게 뽑아서 를 학습.
학습 loss는 다음과 같다.
으로 value는 MSE, policy는 cross entropy 뒤는 L2 norm이다.
개인적으로는 알파고 제로는 기존 강화학습의 temporal diffrence와 같이 bootstrap인데 bootstrap방법이 MCTS인 것으로 생각된다.
2 Empirical Analysis of AlphaGo Zero Training
위 학습을 3일동안 해봤는데 490만 game이 진행이 되었고 각 step마다 1600 iteration MCTS가 진행이 되어 0.4s가 걸렸고 700000 mini batch에 2048 position이 들어가서 업데이트가 되었다고 한다.
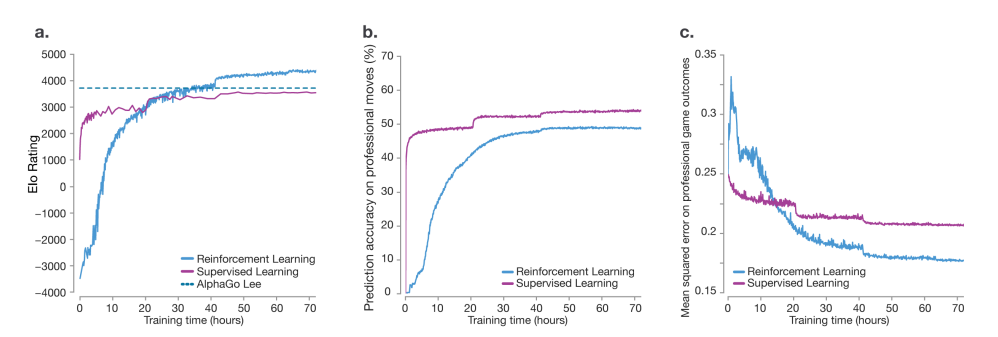 재밌는건 초반에는 supervised learning이 이기지만 학습이 진행이 되면서 기존의 알고리즘을싹다 이긴다.
재밌는건 초반에는 supervised learning이 이기지만 학습이 진행이 되면서 기존의 알고리즘을싹다 이긴다.
그리고 2번째 사진을 보면 professional move prediction과 다른 결과를 보인다.
이는 사람이 하는 것과 다르게 하지만 더 좋은 결과를 보이는 것으로 사람의 수가 최고의 수가 아니라는 것을 보여주고 알파고 제로는 사람과 다르게 플레이 하지만 더 뛰어난 성능을 보여주는 것을 의미한다.
아키텍쳐에 따른 성능도 비교를 진행하였는데
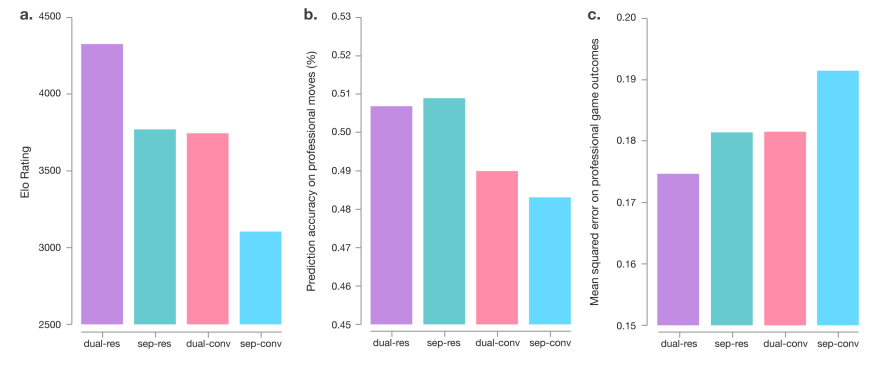 우선 residual을 사용한것이 CNN만 사용한 것보다 더 좋은 성능을 보였다.
우선 residual을 사용한것이 CNN만 사용한 것보다 더 좋은 성능을 보였다.
그리고 policy와 value를 분리한 것보다 합친 것이 더 뛰어난 성능을 보였는데 생각보다 ELO 차이가 매우 크다.
policy와 value를 합쳤을 때 move prediction 성능이 떨어졌지만 value MSE loss는 더욱 줄었다.
이는 합치는 것이 computational efficiency 뿐만 아니라 dual objective 규제가 좀더 general한 representation을 얻을 수 있게 함을 보여준다.
3 Knowledge Learned by AlphaGo Zero
알파고 제로는 바둑에 대한 기존의 지식을 뛰어넘는 놀랄만한 지식도 가지고 있음을 보였다.
코너 케이스에서 새로운 방법을 보였다는데 내가 바둑을 잘 몰라서 이해하기 힘들었다. 그렇기에 넘어간다.
