[논문 리뷰]UNITABE: A UNIVERSAL PRETRAINING PROTOCOL FOR TABULAR FOUNDATION MODEL IN DATA SCIENCE - ICLR 2024
paper
요약
사실상 TransTab의 내용을 많이 이어받은 것으로 보인다.
유동적인 table들의 pretraining과 tansferability를 중요하게 생각하는 model이다.
table을 preprocessing하는 TabUnit이 제일 중요한데
우선 각 cell의 value와 feature name을 word embedding으로 처리해서 embedding을 만들고 data Type과도 섞어서 cell을 preprocessing한다.
이때 fuse layer, linking layer은 그냥 gate layer이다.
이후는 encoder은 그냥 transformer encoder이고
shallow decoder은 LSTM으로 initial state로 word embedding + cell의 값으로 cross attention 처리된 prompt의 weighted 평균과 preprocessed feature의 cls token의 concat + linear layer 통과를 받고
각 이전 token을 받고 정답 token을 생성한다.
ABSTRACT
NLP에서 pretrained model의 효과는 매우 컸다.
이 논문은 pretraining 방법론을 활용해서 data science의 table의 prediction에 활용하는 방법을 찾는다.
이를 위해서 다양한 구조에서 table domain을 위한 generalizability와 transferability를 지키는 pretraining 방법을 설립하는 것이다.
이 논문은 specific한 table의 구조에 제한이 되지 않고 table을 동등하게 학습할 수 있는 UbiTabE를 소개한다.
기본적인 컨셉은 basic table element를 각각 module 즉 TabUnit으로 표현하는 것이다.
UniTabE은 다른 baseline보다 뛰어난 성능을 보였다고 한다.
1 INTRODUCTION
tabular domain의 현재 문제점은 다음과 같다.
- model architecture의 개선에만 모든 노력이 집중되어 있다. 이런 접근은 특정 맥락에서는 effective할 수 있지만 tabular data의 본질 특히 numerical value의 중요성을 무시할 수 있다.
- 최근 접근법은 NLP로 pretrain된 LLM을 finetuning하는 것이다. 하지만 LLM은 tabular data를 다루기에 근본적으로 다른 접근법을 가지고 있다. 게다가 이런 방법들은 보통 간단한 textualization이 적용되었기에 성능을 제한할 수 있다.
- 이전 논문들은 large-scale tabular data의 학습에만 다루고 있고 transferability는 제대로 다루지 않고 있다.
- 현존하는 neural network 방법들은 XGBoost와 비교해서 크게 차이가 나지 않는다.
- 많은 기존의 방법들은 training과 test에서 사용되는 table 구조의 제한이 존재한다. 학습하는 table과 test하는 table의 column이 다를 수가 있기 때문
이런 문제들을 해결하기 위해 이 논문은 UniTabE를 제시한다.
이는 flexible하고 uniform하게 table 구조를 처리하기 위한 효과적인 framework라고 한다.
우선 pretrain을 위해서 13 billion sample을 kaggle에서 수집하였고 이를 통해 pretraining을 진행하는데 다양한 task의 pretraining과 finetune을 unified framework에서 처리하기 위해서 이 논문은 universal training protocol을 제시한다.
이 protocol은 auto-regressive decoder과 free-form prompt를 조합해서 사용한다.
decoder은 encoder에 의해서 만들어진 representation을 추론하고 task-specific prompt를 통해서 task-specific adaptable module의 기능을 하게 된다.
이때 encoder에 pretranining으로 학습된 정보를 보존하기 위해서 decoder은 얕게 사용한다.
3 UNITABE ARCHITECTURE
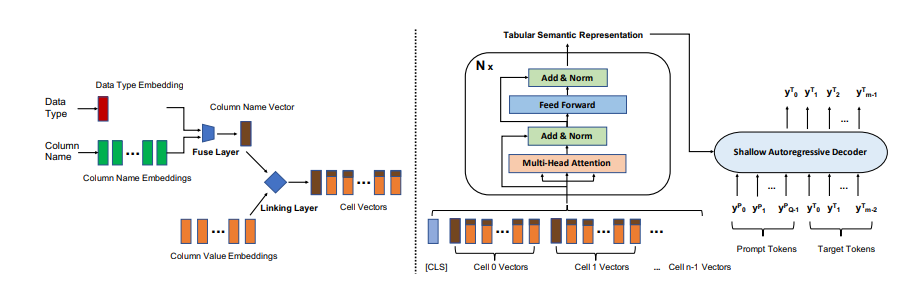 (표의 cell은 1개 feature이다.)
(표의 cell은 1개 feature이다.)
3개의 구성요소로 만들어진다.
- TabUnit: 다양한 data type를 처리하기 위한 foundational feature processing unit이며 transformer의 encoder 전에 활용(위 그림의 왼쪽)
- Encoding Layer
- Shallow Decoder
TabUnit Module
위 그림 왼쪽 부분이고 tabular data의 basic element를 modeling한다.
그러니까 TransTab에서 각 feature를 column과 결합해서 의미의 embedding을 만드는 부분과 동일하게 생각하면 될 것 같다.
이 논문에서는 column name의 vector와 cell value의 vector를 concat한다.
보통 원래 column에는 value가 1개인데 이 논문의 그림을 보면 value embedding이 여러개다. 이는 아마 preprocessing을 하지 않고 TransTab에서 column의 이름을 tokenizing해서 embedding을 만든 것처럼 value 자체의 이름을 가지고 tokenize해서 만든 embedding이라고 생각한다.
column name vector를 만들기 위해서 colunn name token 을 embedding module을 통과한다.
위 수식처럼 Embedding layer를 통과하는데 Embedding layer는 word embedding과 positional embedding이 포함이 되어있다. 이후 average pooling을 통과한다.
는 data type이다. 논문에서는 이를 int 값으로 mapping을 하였는데(numerical ->0, categorical ->1, textual ->2)
여기에도 embedding module이 있고 동일하게 Avg를 해주는데 근데 data type은 1개라서 Avg는 의미가 없을 것 같다.
이렇게 해줌으로써 동일한 feature name "salary"를 가졌을 때 그게 numerical인지 categorical인지 textual인지 구별해서 정확한 의미를 얻을 수 있다.
이렇게 각각 구성한 과 를 fusion layer를 통해 합쳐준다.
위와 같은데 은 학습 가능한 param이다.
그냥 dt를 얼마나 섞을지 결정하는 gate의 효과라고 생각하면 될 것 같다. 를 만으로 결정하는 이유는 이론적으로 동일한 data type을 가지면 동일한 비율의 data type 정보를 가지는 것이 좋고 에 의해서 영향을 받아 다양하게 구성되면 안좋기 때문.
이후 위처럼 column value의 각 token을 embedding으로 만든다.
이후 단순히 feature name과 concat하면 transformer는 순서가 없기에 열 이름과 값 사이의 관계성을 파악하기 힘들기에 linking layer를 통과시킨다.
역시 는 학습 가능한 param이며 이렇게 구성한 gate layer의 비율만큼 의미를 더해준다. 이때 더해주는 비율은 모두 동일하다. 이렇게 해줌으로써 다른 column들이 있어도 각 value가 어느 column의 값인지 모델이 알 수 있다.
결국 TabUnit은 다음과 같이 표현이 가능하다.
Encoding Layer
앞서 TabUnit으로 모든 column들을 embedding으로 바꾸고 앞에 cls를 붙인다.
이후 transformer encoder를 통과시킨다.
Shallow Decoder
pretraining에서 encoder가 학습한 knowledge를 저장할 수 있게 LSTM을 decoder로 사용한다.
왜 이런지는 솔직히 잘 모르겠다. 아마 LSTM이 기억을 잘하고 weight가 다른 decoder에 비해서 적어서 그런 것 같다.
decoder의 구조는 되게 신기한데
특이한 부분이 우선 prompt가 존재한다.
예를 들어서 "이 학생의 age는 뭘까?"등의 prompt를 tokenize하고 encoder와 공유하는 embedding layer로 embedding 한 다음 wieght로 바꾸고 이전의 TabUnit으로 바꾼 값들을 weight를 통과시키고 attention을 진행한다.
아마 prompt를 query, TabUnit이 key, value로 query를 중심으로 dot product attention이 진행되는 것으로 보인다.
이때 prompt state를 weighted average 해주는데 아래에서 은 학습가능한 param이다. 즉 을 중심으로 average sum 해주는 것
이후 decoder의 초기 state를 다음과 같이 정한다.
이렇게 초기 state를 주는 것은 결국 pretraining 된 knowledge를 초기 state에 담기 위함이다.
그런데 LSTM은 initial state가 cell과 hidden 2개인데...? 어떻게 처리한거지
decoder은 이렇게 구성한 초기 state와 이전 token들을 가지고 다음 token을 예측한다.
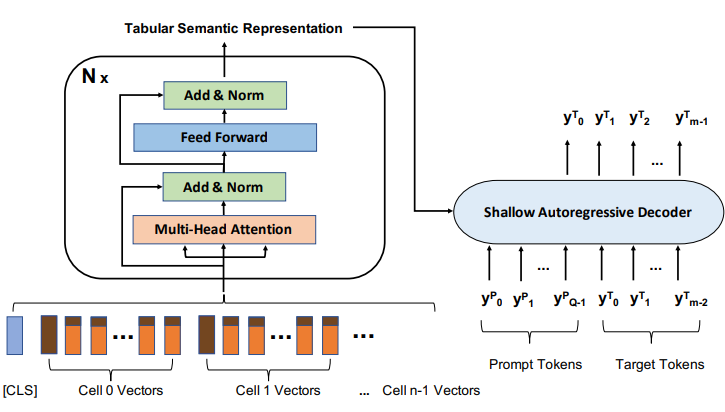
4 PRETRAINING & FINETUNING
4.1 PRETRAINING OBJECTIVE
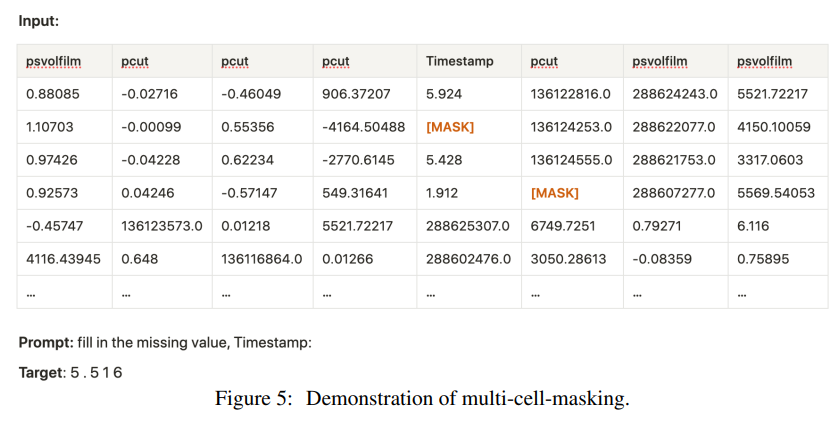
Multi-Cell-Masking.
이는 NLP의 self-supervised task이다. 이 논문에서도 이를 채택.
NLP에서는 token 수준의 masking이 이루어지지만 여기에서는 cell 수준의 masking이 진행됨
masked cell의 내용물을 와 같은 임의의 special token으로 채운다. 추가로 null cell도 동일하게 로 채운다.
pretraining에서는 임의로 특정 column을 masking하고 model이 그 내용을 예측하게 한다.
prompt는 동일하게
"fill in missing value, <column name> :"로 template가 통일이 되었다.
학습은 maximum log likelihood를 목표로 진행
Contrastive Learning.
masking된 값을 예측하는 것은 table의 global information에 집중한 전략이다.
contrastive learning으로 local property에 집중하게 만들 수 있다.
subtab과 같이 table을 쪼개고 이를 가지고 같은 sample이면 positive, 다른 sample이면 negative로 구성
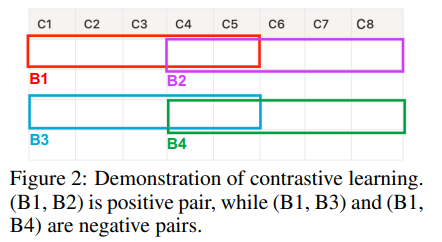 cosine sim으로 가까운 block을 활용
cosine sim으로 가까운 block을 활용
학습 목표는 positive끼리는 가깝게하고 negative와는 멀게 한다.
contrastive learning을 정확히 어떻게 하는지는 언급이 없다.
아마 decoder을 사용하기는 어려울 것 같고 cls token으로 유사도를 측정해서 진행하지 않을까? 추측한다.
4.2 FINETUNING FORMULATION
Filling in Missing Value as Prediction.
finetune할때 target을 table의 additional column으로 본다.
모델은 pretraining과 동일하게 target column의 masked value를 예측하는 것이다.
이때 decoder가 있기에 regression과 classifiaction 모두 잘 학습할 수 있다.
논문에서 constrained generation을 support 하였다고 하는데 이를 통해 classification에 만약 10개 class라면 10개의 token으로 generation을 제한하고 이를 토대로 학습이 이루어졌을 것이라고 생각한다.
Finetuning with Task-specific Prompt.
target을 masked column으로 보는 것에서 벗어나 model이 table과 다른 input에 대한 reasoning이 필요한 task도 있다.
예를 들어서 Question answering task(QA)등.
model은 table과 question에 대해서 answer를 만들어야 한다.
아마 이는 gpt와 동일한 방법으로 token 예측으로 학습이 이루어지지 않았을까 생각한다.
5 EXPERIMENTS AND ANALYSES
5.1 PRETRAINING DATASET
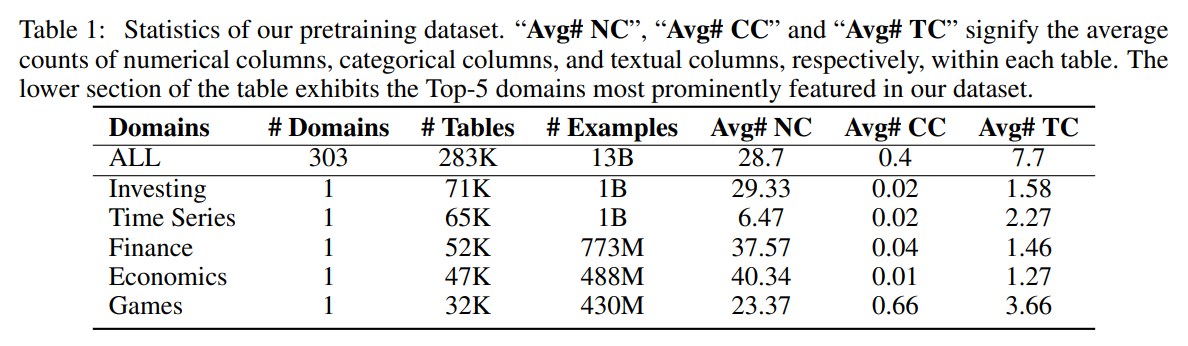
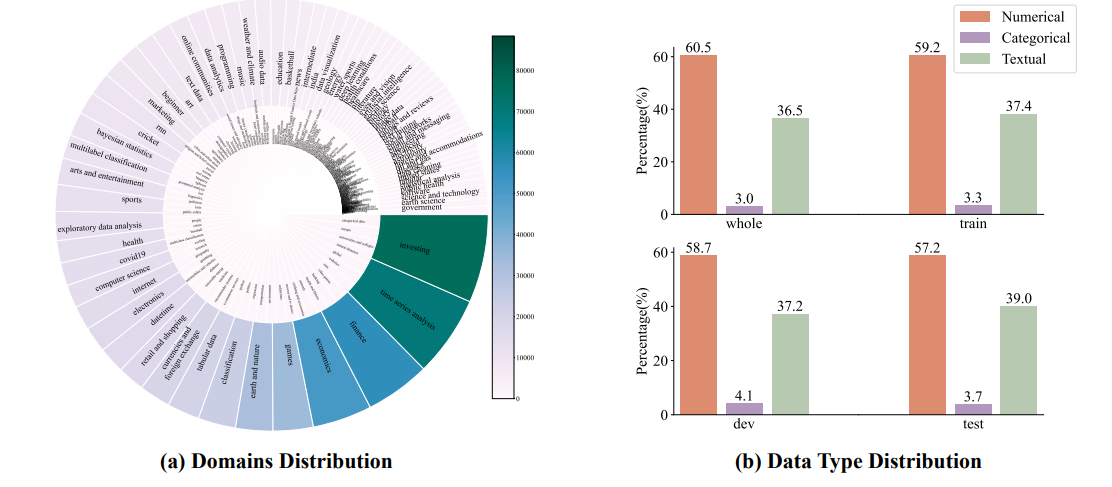
기존에 large-scale high quality dataset이 없었는데 이를 kaggle을 크롤링해서 만들었다.
각 domain의 key word를 정하고 WordNet을 이용해서 같은 topic의 유사한 단어를 점점 확장해가는 식으로 진행
동일한 dataset에서 온 table은 primary key와 foreign key를 join하는 식으로 합침.
결국 7TB, 12billion table dataset을 구축하는데 성공
5.2 IMPLEMENTATION DETAILS
32 A100 gpu로 학습 진행 모델을 pytorch 1.12로 구현이 됨
transformer backbone은 huggingface transformers에서 가져옴
- lr: 1e-5
- batch: 64
- Adam,
UniTabE base는 embedding, hidden dim 768, 12 attention layer, 12 head
large는 embedding, hidden dim 1024, 24 attention layer 16 head
xlaerge는 large에서 48 attention layer
5.3 RESULTS & ANALYSES
Kaggle Benchmarks.
pretrain한 dataset에서 제외한 6개의 data를 가지고 benchmark 진행
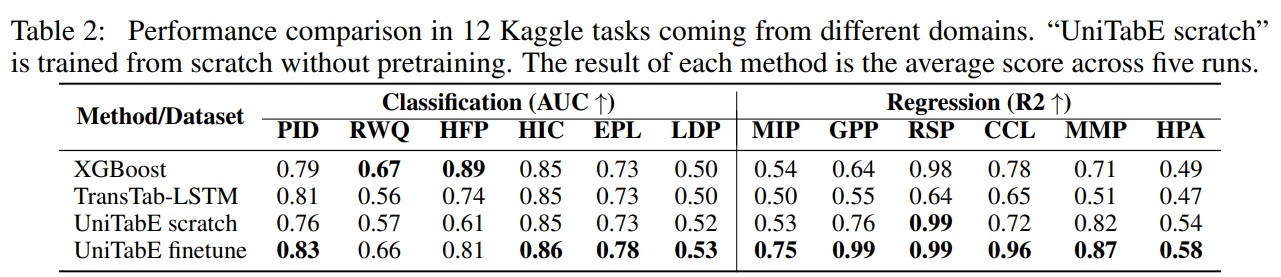
TransTab-LSTM은 transtab에 unitabe의 decoder를 장착한 것 UniTabE와의 차이점은 feature processing이랑 transformer에 gate가 들어간것.
대부분의 상황 특히 regression에서 unitabe가 성능이 잘나온다.
Public Benchmarks.
kaggle은 pretrain에 있기 떄문에 오염될 가능성이 있다. 그렇기에 다른 benchmark로도 진행
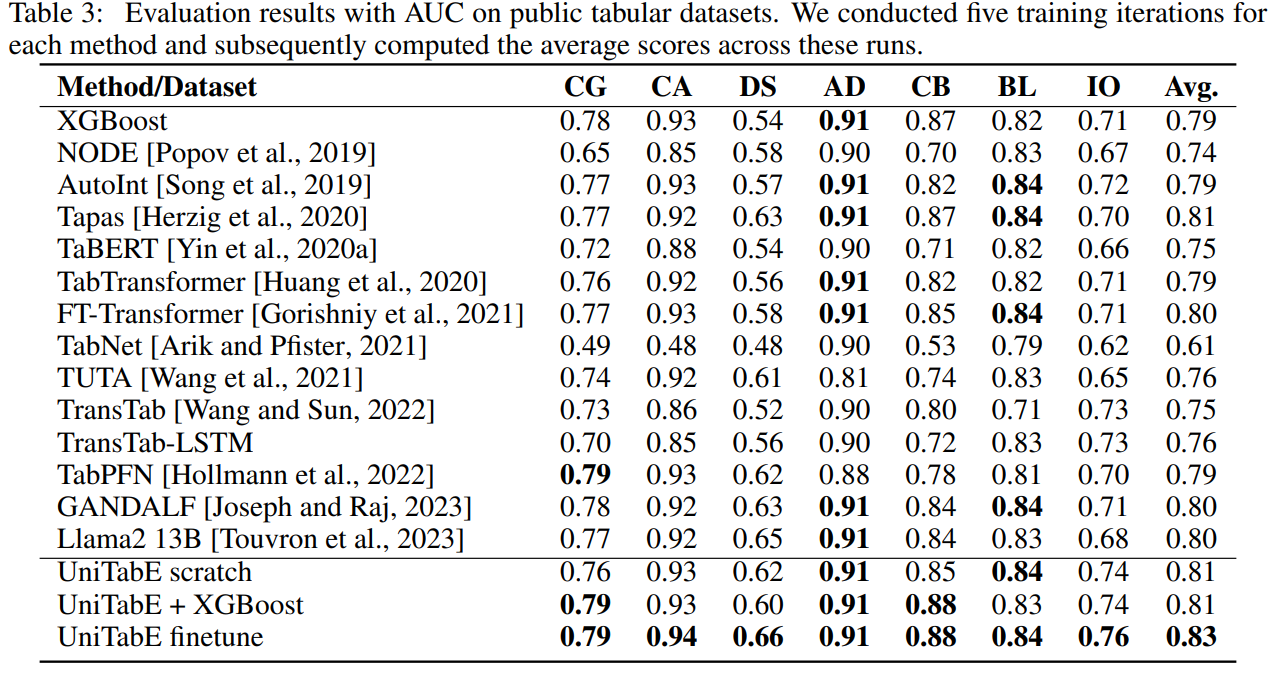
여전히 뛰어난 성능을 보여줌
Zero-shot Prediction.
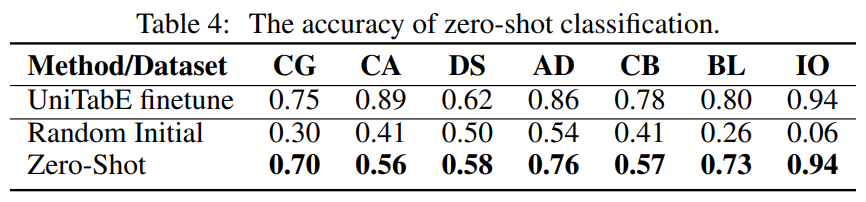
Adaption of Incremental Columns.
training set에서 k개의 column을 지우고 학습하고 test에는 전체를 가지고 test
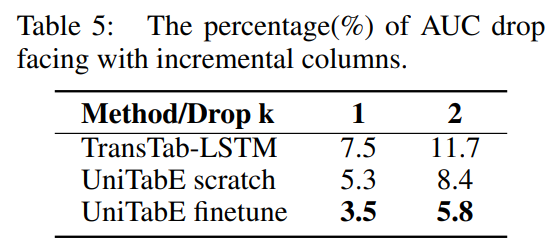
새로운 column을 봐도 생각보다 성능저하가 일어나지 않는다.
이는 일반화 성능의 좋음을 의미
Model Size Analysis.
모델 사이즈가 크고 데이터도 크면 좋은 성능을 보임
small은 2000이하
medium은 2000~20000
large는 20000보다 큼
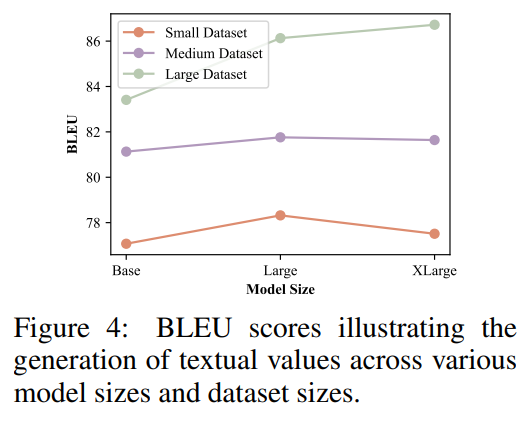
이때 dataset이 작으면 large가 좋은 성능을 보임
Ablation Analysis.
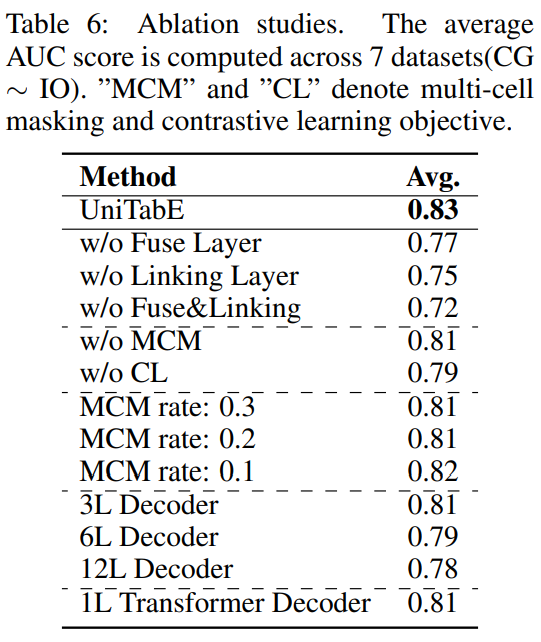
Learned Feature + XGBoost.
학습한 representation과 XGBoost를 결합한 것
