Abstract
기존의 tabular self-supervised learning은 multiple data table들이 공유하는 정보들과 새로운 table이 주어질 때 일반화를 하지 못한다.
이 논문은 XTab을 제시하는데 various domain의 tabular transformer cross-table pretraining framework이다.
이 논문은 inconsistent column type과 table의 quantities에 대한 문제를 독립적인 featurizer과 연합 학습을 이용해서 pretraining을 진행한다.
1. Introduction
tabular deep learning model은 실제로 tree based model만큼 사용이 되지 않는다.
tabular deep model의 문제점은 tabular task의 diversity이다. 즉 table마다 row, column의 개수, 내용 등등 특징이 매우 다르기 때문이다. 이 때문에 knowledge transfer 등도 어렵고 일반화 성능도 떨어진다.
이 논문은 XTab을 소개하는데 cross-table pretraining of tabular transformer framework를 제시한다.
table의 column의 type과 개수가 다른 것의 문제를 해결하기 위해서 XTab는 tabular transformer를 2개의 component로 나눈다.
- table의 특성을 담는 data-specific featurization and projection layer
- 공통된 knowledge를 저장하는 cross-table-shared block
우선 pretraining이 완료가 되면 XTab은 shared block의 weight를 이용해서 학습을 빠르게 완료할 수 있다.
3. Methods
이전의 pretraining 방법론들은 개별 tabular prediction task를 수행할 뿐이기에 domain specific하고 일반화 성능이 떨어져서 다른 type의 downstream task에 약하다.
이때 XTab는 cross-table의 shareable konwledge를 학습하는 것이 목표이기에 다양한 downstream task에 적용할 수 있다고 주장한다.
3.1. Model structure
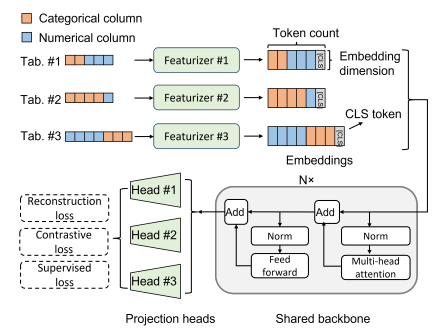
pretraining 과정에서 다양한 table로부터 각각의 row를 뽑아내서 batch를 구성한다.
featurizer을 data specific해서 각 table의 column을 token embedding으로 바꾼다.
그리고 CLS token을 부착해서 supervised prediction이나 contrastive self-supervised에 이용한다.
이후 transformer로 처리하는데 transformer은 공유된다.
transformer의 output에는 각각 head를 달아서 복구, contrastive, supervised loss로 loss를 각각 구성한다.
이때 projection head는 각 table마다 공유가 되지 않는다고 한다.
shared backbone은 knowledge를 저장하고 나머지는 각각 data specific하게 처리
약간 메타러닝 느낌인 것 같다. 여러 domain을 학습하면서 학습하는 방법을 학습한달까...
3.1.1. FEATURIZERS
다른 tabular transformer를 본 사람들이라면 이해가 쉬을 것이다.
sample을 으로 바꾸는 것이다.
c는 column 숫자이고 d는 embedding dim이다.
이후 CLS를 붙여서
로 구성된다.
text cell은 categorical로 취급하고 numerical이랑 categorical만 있다고 가정
numerical은 그냥 로 곱하고 bias만 더해준다. 즉 1 linear layer 느낌.
categorical은 torch.embedding으로 로 index를 embedding으로 바꿔준다.
3.1.2. BACKBONES
길이가 유동적인 sequence를 다룰 수 있게 만들기 위해 transformer를 채택
FT-Transformer
Feature Tokenizer Transformer로
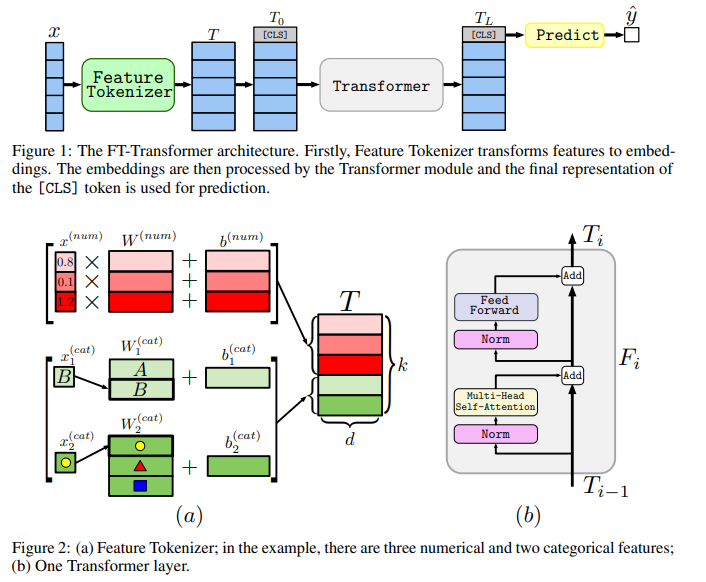 그냥 위처럼 매우 간단한 기본적인 transformer 구조이다.
그냥 위처럼 매우 간단한 기본적인 transformer 구조이다.
Fastfromer
transformer와 비슷한 모델 multi head self-attention 대신에 additive attention을 사용한 모델이라고 한다.
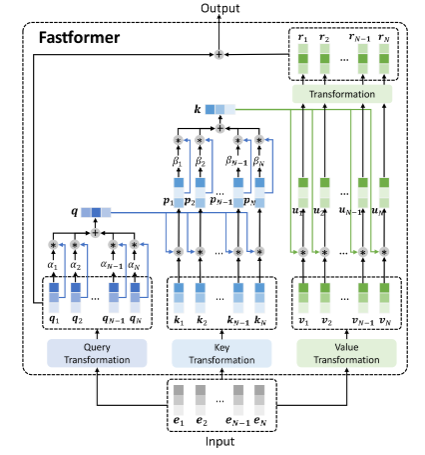 구조는 위와 같다.
구조는 위와 같다.
잘보면 query를 각각 를 곱해주는데 이는 learnable vector와 query를 곱하고 weighted average해준 것이다.
그렇게 qeury를 1개의 vector로 압축한다. 이를 key와 곱하고 압축해서 global key vector로 만들고 value와 product해서 linear transform해서 attention matrix를 얻고 query와 더한다.
압축 연산으로 이득보는 구조.
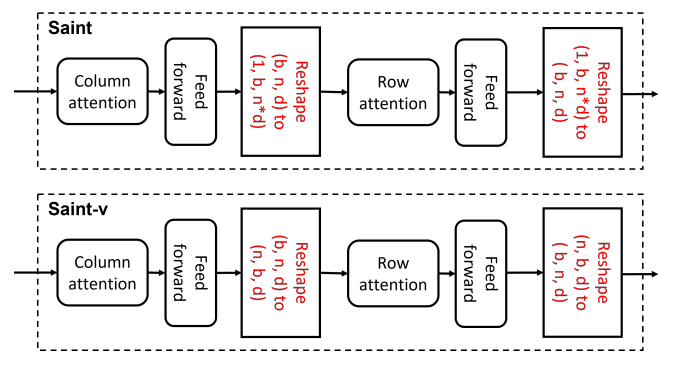
Saint-v
SAINT는 row-wise attention, column-wise attention을 한다.
SAINT 논문리뷰를 한적이 있으니 읽으면 좋다.
뒤에 붙은 v는 variable table을 처리할 수 있게 바꿨다고 한다.
논문의 내용을 보면
그냥 reshape를 바꿔준 것이다. 근데 이러면 각 column별로 따로 attention이 들어가는 문제가 생길 것 같다.
즉 기존은 전체 column을 한번에 batch wise attention이 들어갔으면 따로따로 진행되는 구조가 된다.
3.1.3. PROJECTION HEADS AND OBJECTIVES
Reconstruction loss
self-supervised task
corrupted data로부터 복구하는 것이 목표 categorical은 cross-entropy, numerical은 MSE
Contrastive loss
self-supervised task이고
reconstruction과 비슷하게 corrupted data를 만들고 corrupted 된 와 원본 랑 positive pair이고 나머지는 negative pair이다.
Supervised loss
regression과 classification이 가능
XTab의 경우 projection head가 data specific하기에 table마다 objective를 다르게 pretraining이 가능하다. 즉 regression과 classification을 동시에 처리 가능.
3.2. Federated pretraining
pretraining이 data의 개수가 많아지면 오래 걸린다.
그러나 Federated training으로 시간을 매우 짧게 pretraining이 가능했다.
- 논문은 Nvidia T4로 납득가능한 시간내에 했다는 것 같다.
Federated Averaging (FedAvg) algorithm을 사용했다고 하는데
central server와 multiple client가 있고 각각의 client는 1개의 dataset을 돌린다고 한다.
이렇게 분산학습을 진행하는데 간단하다.
각 client에서
이렇게 gradient를 구해서 weight를 업데이트 하는데
k는 client의 index이고 i는 iteration이다.
이때 shared weight의 param을 server가 모아서 업데이트 한다.
이렇게 구성이 된다. weight의 차이는 gradient와 같으니 gradient와 동일하게 보고 이를 client K개를 모아서 업데이트를 진행한다.
이렇게 servser가 weight를 다 모으고 다시 이 weight를 client에 뿌려서 학습을 하고 다시 모으고 반복한다.
은 hyperparam인데 이면 그냥 단순한 분산 SGD학습이고 이면 servser와 client의 communication cost를 줄일 수 있다.
이 논문은 로 설정해서 학습을 진행했다고 한다.
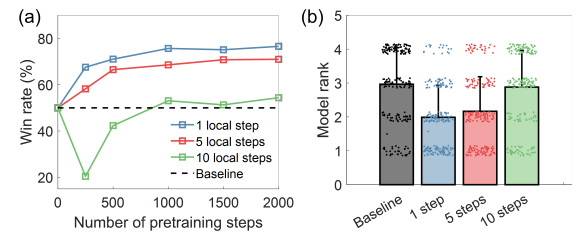 이때 downstream prediction 성능을 보면 N의 성능은 아무래도 1이 제일 좋고 5는 조금 떨어지고 10은 매우 떨어진다.
이때 downstream prediction 성능을 보면 N의 성능은 아무래도 1이 제일 좋고 5는 조금 떨어지고 10은 매우 떨어진다.
4. Experiments
finetuning 때는 featurizer와 projection head를 random init 부터 시작했다고 한다.
오직 transformer backbone만 학습된 것을 가져와서 학습.
4.1. Datasets
pretraining과 eval에 OpenML-AutoML benchmark사용
총 104개의 dataset에서 52개를 pretraining 나머지 52개를 eval에 사용
data는 normalization을 하고 missing value는 numerical의 경우 mean 값으로 채우고 categorical은 null category로 처리한다.
table corruption의 경우 랜덤한 feature의 비율을 선택하고 resample하는 식으로 corrupt를 진행
그냥 다른 row에서 feature을 가져온다고 생각하면 될 것 같다.
이 논문에서는 60%를 resample
4.2. Experimental setup
T4 gpu cluster로 구성이 되었고
총 3000시간의 gpu hour가 들었다고 한다.
그런데 cluster이기 때문에 분산 학습이 이루어져서 생각보다 실제로 걸린 시간은 얼마 없을 것 같다.
Evaluation metrics
regression의 경우 RMSE로 평가
binary classification의 경우 AUC
multi class의 경우 log loss
4.3. Comparison with baseline transformers
평가가 되게 특이한데 win rate로 측정한 것이 있다.
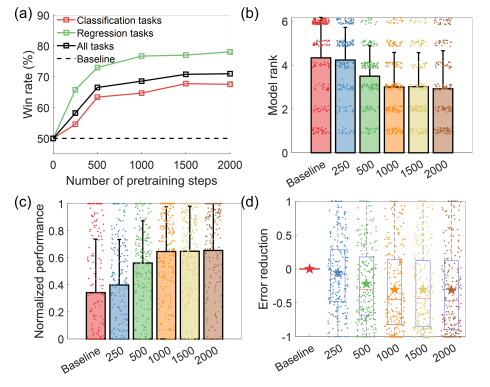 그러나 확실히 pretraining이 진행이 되면서 성능이 향상이 된다.
그러나 확실히 pretraining이 진행이 되면서 성능이 향상이 된다.
(c)에서 normalized는 최소 preformance와 최대의 min-max normalize가 된 것이다.
error 역시 best와 worst로 min-max normalized 되었다고 한다.
error에서 음수는 low error(1-AUC) or loss(RMSE)라고 한다.
finetuning 방법 차이는 다음과 같다.
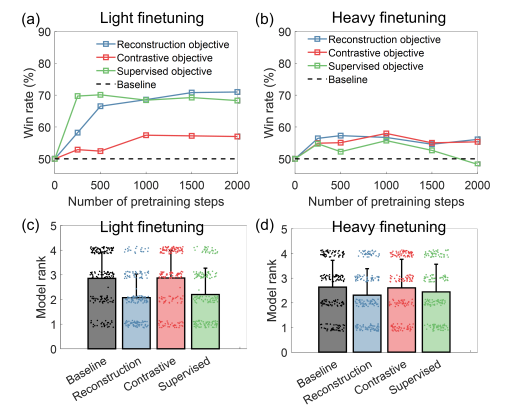
light는 고정 3 epoch이고 heavy는 early stop으로 3epoch 감소 없으면 중단.
그리고 각각의 loss를 어떻게 정했냐에 따른 차이점이다.
supervised나 reconstruction이 좋은 것 같다.
주의할게 위 그래프는 win rate이기에 light가 성능이 더 잘나오는게 아니다.
light의 상황에서 더 pretrain의 효과가 큰 것
절대적인 성능은 heavy이다.
transformer backbone의 차이
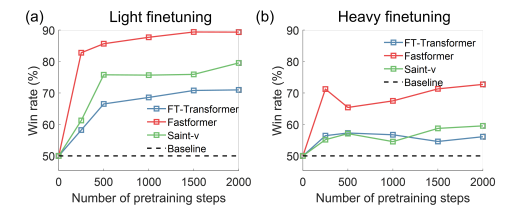 FAST > Saint> FT의 순으로 좋다.
FAST > Saint> FT의 순으로 좋다.
4.4. Performance compared to traditional baselines
XTab의 경우 104개의 data를 각각 52개씩 나누고 pretraining을 하는데
fold 1을 가지고 train하고 fold 2를 test하는 식으로 진행
이때 20개의 data는 GPU mem이 부족해서 제외되고
나머지 84개의 data로 test가 진행되었다고 함.
학습 시간과 model rank는 AutoML 84개 dataset으로 구성
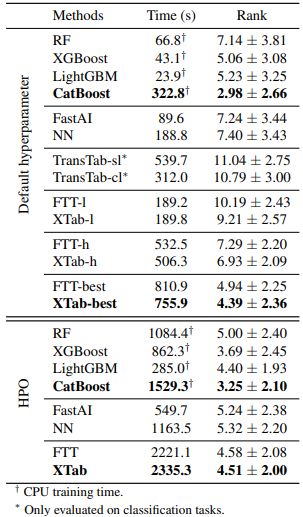 HPO는 hyper param optimization
HPO는 hyper param optimization
tree 기반 CatBoost가 가장 성능이 좋았고 딥러닝 based model은 XTab이 제일 좋았다.
TransTab의 sl은 supervised, cl은 contrastive 이다.
-l은 light -h는 heavy learning이다.
best는 제일 loss가 낮은 모델을 고르는 것
HPO는 validation set의 성능을 토대로 찾는 것이고 1시간 들여서 100번 진행해서 골랐다고 함
