[논문 리뷰] SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
paper
Abstract
- gradient boosting, random forest가 tabular data의 문제를 풀기 위해 고전적으로 사용이 되어왔다.
- 그러나 deep learning을 이용한 방법도 고전적인 기술과 비교할 수 있는 수준에 올랐다.
- 이 논문에서는 tabular data 문제를 풀기위해 deep learning의 hybrid 접근방법을 고안해내었다.
- SAINT는 attention을 row, col에 적용을 하고 강화된 embedding 방법을 포함한다.
- 또한 label이 부족할 때 사용이 가능한 대조적인 self-supervised pretraining 방법을 제시한다.
1. Introduction
최근 vision, nlp 분야가 급속도로 발전했지만 tablular data는 특이한 특성이 있어 큰 이득을 보지 못하였다.
- tabular data는 categorical, continuous, ordinal feature들의 집합으로 표현이 됨. 그리고 이러한 값은 관계가 있을 수도 없을 수도 있음.
- tabular data는 내재적인 위치 정보가 없음. column의 숫서는 임의적이다.
이러한 특징은 이미지, text가 연속되고 위치에 따른 연관성을 가진다는 것과는 대조가 된다.
결국 tabular model은 다수의 discrete, continuous 분포를 가지는 feature들을 위치 정보에 의존하지 않고 연관성을 찾아야 한다.
여기에서 taular data를 위해 특화된 SAINT(Self-Attention and Intersample Attention Transformer)를 소개한다.
SAINT는 tabular data 학습의 어려움을 극복하기 위해 여러가지 방법을 사용하였는데
- categorical 뿐만 아니라 continuous data도 combined dence vector로 projection한다.
- 이렇게 projection된 vector는 token으로 취급이 되어서 transformer ecoder로 들어가는데 attention을 2가지 방법으로 사용한다.
- self-attention: 기존 방법
- intersample attention: 새롭게 제시하는 방법
intersample attention은 논문에서 제시하는 방법으로 row(data sample)의 classification을 다른 row와 연관을 짓는 방법으로 강화를 하였다.
이러한 방식은 nearest-neighbor classification과 비슷한데 distance metric을 fix하는 것이 아니라 end-to-end로 학습하는 것이다.
- 이러한 hybrid attention 외에도 self-supervised contrastive pre-training을 활용하여 semi-supervised 문제에서 성능을 이끌어냈다.
이러한 SAINT는 매우 좋은 성능을 보였다.
이전에 리뷰했던 TabTransformer에서는 transformer를 이용한 contextual embedding 학습을 categorical에만 적용을 하였기에 categorical과 continuous feature 간의 관계성이 버려지게 되었는데
SAINT에서는 continuous, categorical 모두 vector화 해서 transformer에 통과시키기 때문에 이러한 관계성이 버려지지 않는다.
3. Self-Attention and Intersample Attention Transformer (SAINT)
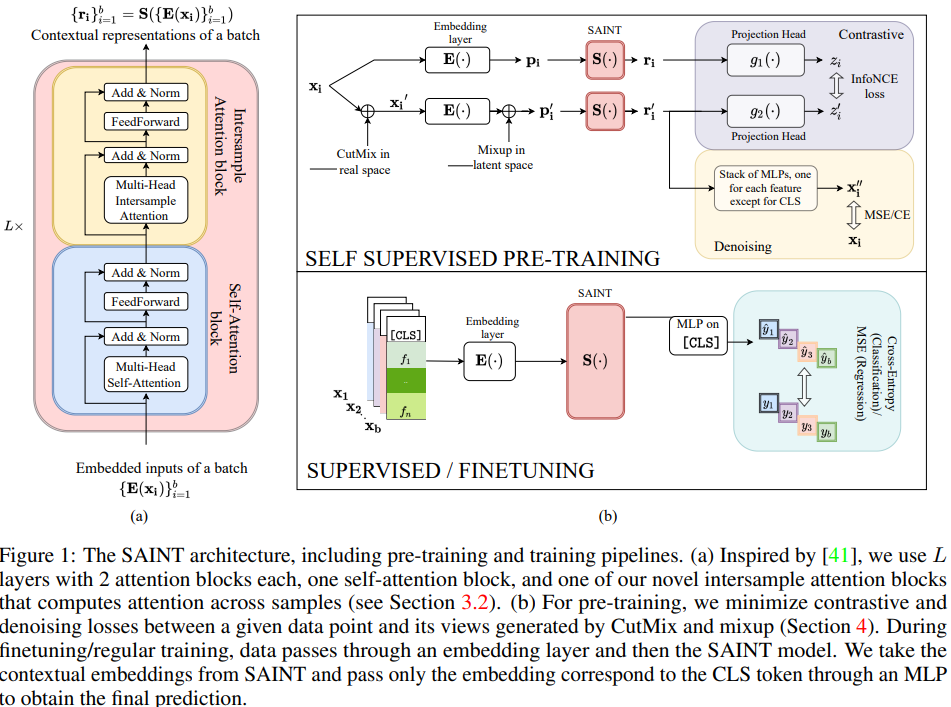 전체 모델 구조와 training을 간단하게 표현하면 위 그림과 같다.
전체 모델 구조와 training을 간단하게 표현하면 위 그림과 같다.
Input 처리
로 표현이 가능한 m개의 tabular 데이터가 있다고 하자. x는 n-dimension feature vector이고 y는 target variable이나 label이다.
BERT와 비슷하게 여기에서도 학습가능한 [CLS]토큰 embedding을 사용한다.
으로 하나의 데이터 포인트를 표현이 가능한데
는 각 categorical이나 continuous feature에 해당하는 1개의 value이다.
그리고 는 embedding layer로 각 feature을 -차원으로 embed한다.
- 여기에서 중요한 점은 는 각각 feature에 독립적으로 다른 embedding 함수를 작용할 수 있다.
에서 으로 만들어진다.
Encoding the data
-
언어 모델은 embedding을 같은 함수로 만들지만 tabular data에서는 feature마다 다른 distribution을 가지기 때문에 다른 embedding function을 적용하는 것이 필요하다.
-
또한 여러개의 feature에서 동일한 class가 나오는 것도 가능한데 동일한 관계를 가진다고 알려진 것이 아니라면 각각 다르게 임베딩을 해야한다.
-
TabTransformer와는 다르게 continuous feature 또한 d-dimension vector로 projection을 하고 transformer encoder에 넣는다.
이 때 각 continuous feature의 projection을 위해 1-dim을 1개의 fully connected layer와 ReLU를 통해 d-dim으로 바꾼다.
3.1 Arcihtecture
SAINT는 L개의 동일한 stage로 구성이 되는데 각 stage는 1개의 self-attention transformer와 1개의 intersample transformer로 구성된다.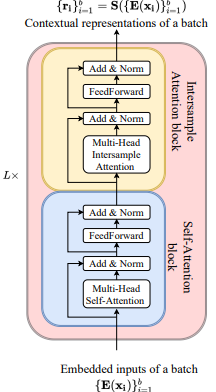 각 self-attention block은 encoder와 동일한데 FeedForward는 2개의 Fully connected layer와 GELU로 구성이 된다.
각 self-attention block은 encoder와 동일한데 FeedForward는 2개의 Fully connected layer와 GELU로 구성이 된다.
각 layer는 skip-connection과 layer normalization으로 구성이 된다.
intersample transformer는 attention이 Multi-head intersample attention으로 대체된 것을 제외하면 동일하다.
아래는 stage의 개수 L=1 이고 batch가 b일 때의 수식이다.
MSA(multi head attention), MISA(multi head intersample attention)
FF(Feed forward), LN(layer normalization)
이렇게 순차적으로 진행이되고
는 SAINT의 데이터 에 대한 contextual representation이다.
3.2 Intersample attention
intersample attention은 row에 대해서 attention을 구하는 것으로 1개의 데이터의 feature의 attention을 보는 것이 아닌 batch 단위로 보는 것이다.
만약 한 데이터가 noise나 missing data가 존재한다면 batch의 다른 row를 보고 추측할 수 있게 만들어준다.
 sigle head, batch 3인 intersample attention의 실제 동작은 위 그림과 같다.
sigle head, batch 3인 intersample attention의 실제 동작은 위 그림과 같다.

pytorch 식으로 구현하면 위와 같다.
그림으로 이해해하면 간단한데
위 그림과 같이 self-attention은 (Feature num x d)에 작용이 되었다면
intersample attention은 Feature와 d를 펴서 (batch x (Feature * d))에 작용을 한다.
4. Pre-training & Finetuning
대조학습(contrastive learning)이란 이미지를 자르거나 순서를 바꾸는 등 데이터에 수정을 가해도 같은 것으로 인식할 수 있게 해주는 사전학습 기법인데 vision, language 분야에서 매우 강력한 도구로 이용이 되었지만 tabular data에는 적용이 되지 않았다.
contrastive learning을 vision 분야로 예시들면
이미지, 내용 출처
이런 식으로 기존의 데이터를 색을 바꾸거나 돌리거나 자르는 등 변경을 가하고 원본과 동일한 벡터 표현을 할 수 있도록 vecotr 차이를 줄이는 방향으로 학습하는 것이다.
대략 이런 식으로 진행이 된다.
이 논문에서는 tabular data에서 contrastive learning을 적용하는 방법을 제시한다.
기존의 denoising, Tabtransformer의 masking, token replacing 등다양한 방법이 존재하지만 contrastive learning이 더욱 강력한 결과를 보여줬다.
Generating Augmentation
보통 vision 분야에서는 이미지를 잘라내거나 돌리는 식으로 다른 "view"를 만들어낸다.
이는 tabular data에서는 어렵다.
저자는 CutMix를 input space에서 적용을 하고 Mixup을 imbedding space에서 적용을 하는 방법을 제시한다.
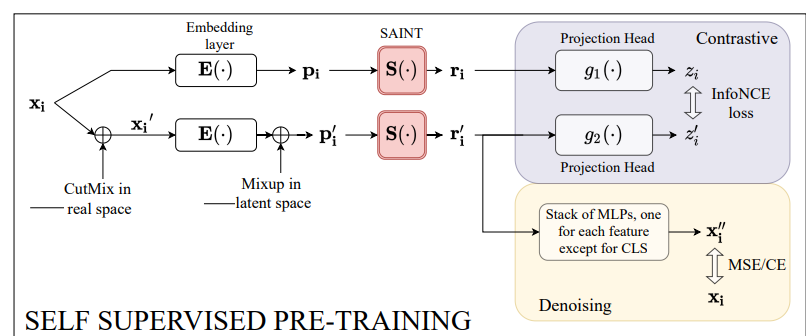 위와 같은 모습을 보인다.
위와 같은 모습을 보인다.
CutMix와 mixup에 대한 설명은 CutMix의 논문 자료를 가져왔는데
데이터의 label을 섞는 것이다.
수식은 다음과 같다.
여기에서 m은 X와 같은 shape인데 이미지가 포함이 되냐 안되냐 {0,1}로 구성이 되어있는 Bernoulli distribution mask matrix이다.
아래 alpha는 간단하게 비율을 나눠서 이미지를 합치는 것이다.
여기에서 알아야할 부분은 는 의 cutmix 버전이다.
이는 batch 내부에서 데이터 쌍을 랜덤하게 골라서 Cutmix를 진행하고 embedding을 진행한 다음 새로운 상대를 골라서 섞는 것을 의미한다.
SAINT and projection heads
이제 이렇게 만든 와 embedding이 섞인 가 나오게 되는데 이를 SAINT에 통과시킨다.
그리고 1개의 hidden layer와 RELU를 가진 MLP projection head에 통과시키는데 이는 Vision 분야에서 contrastive loss를 구하기 전에 dim을 줄이는 용도이다. 그리고 tabular에서는 실제로 성능 향상을 보였다.
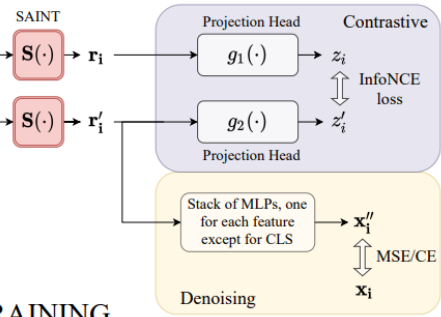
Loss functions
2개의 loss가 고려되었는데
- contrastive loss: 같은 데이터의 다른 view는 비슷한 위치에 놓이게 하고 다른 데이터는 먼 위치에 두게 학습한다.
이를 위해 InfoNCE loss를 가져왔다. - denoising loss: denoising을 위하여 origin data를 noisy view에서 pretidct한다.
위 두 loss를 합치면 다음과 같다.
여기에서 앞부분은 contrasitive loss이고 뒷부분은 denoising loss이다. 두 loss의 결합이다.
loss에 대해 자세히 이해를 해보겠다.
우선 contrastive loss는
이렇게 구성이 되는데 설명을 하자면
와 는 동일한 데이터에 다른 view를 가지는 것이다. 이 부분의 표현을 가깝게 만들어야한다.
그리고 와 는 다른 데이터다. 이 부분은 표현을 멀리 떨어트려야 한다.
여기에서 이제 -log는 내부의 값이 커져야 (0에서 1로 갈수록) 작아진다.
그렇기 때문에 결국 는 커져야 한다. 즉 유사하게 만들어져야 하고
는 작아져야 한다. 즉 다르게 만들어야 한다.
이러한 과정에서 자연스럽게 같은 data의 view는 같게 표현하고 다른 data는 다르게 표현하게 만든다.
두번째 denoising loss는 간단하다.
noise를 줄이기 위해 original data sample을 예측하는 것이다. 이 때 추가 MLP를 사용한다. 이를 통해 output을 와 가깝게 만든다.
는 1개의 hidden layer와 ReLU를 가진 MLP이다.
n은 feature의 개수이다. 각 feature마다 MLP를 통과시켜서 원본을 찾는 것이다.
와는 hyper param이다.
5 Experimental Evaluation
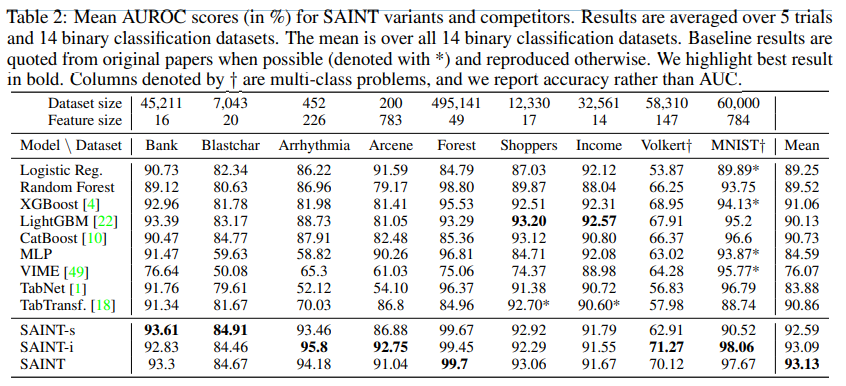 SAINT 모델은 매우 좋은 성능을 보였다.
SAINT 모델은 매우 좋은 성능을 보였다.
추가로 위의 -s -i는
attention을 각각 한가지만 사용한 모델이다.
특히 데이터의 개수는 적은데 feature의 숫자가 많은 arcene, arryhythmia 등의 데이터에서 intersample이 엄청 좋은 성능을 보임
5.2 Interpreting attention
transformer는 MLP와는 다르게 attention을 분석해서 내부의 작동 방식을 이해할 수 있다는 것인데
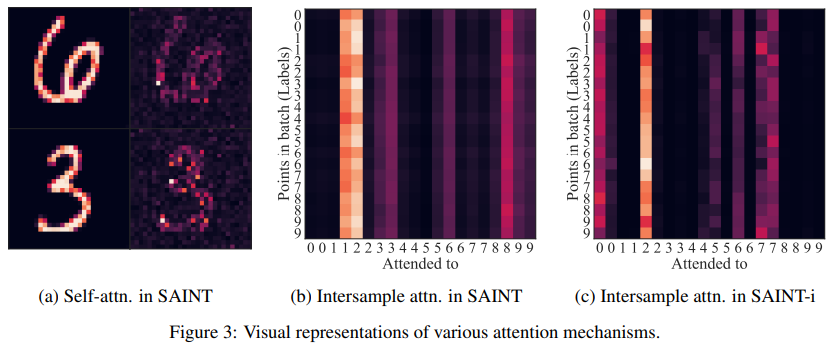 attention을 확인했을 때 Mnist data의 숫자를 파악하는 것이 보였고
attention을 확인했을 때 Mnist data의 숫자를 파악하는 것이 보였고
특이한 부분은 intersample을 진행할 때 특정 데이터에만 attention이 집중이 되어있었다는 것이다.
이를 보고 한가지 가정을 세웠는데 데이터의 직접적인 비교가 없이는 분류가 어려운 데이터에 집중을 한다는 것이다.
결국 intersample attention layer는 데이터를 분류하기 더 어려울수록 더 dense하게 된다.
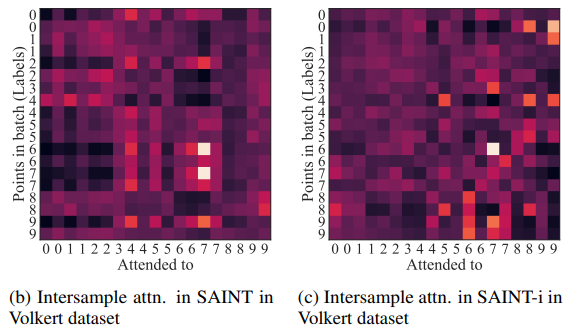 어려운 Volkert data의 경우 매우 빽빽하다.
어려운 Volkert data의 경우 매우 빽빽하다.
