참고
- https://23min.tistory.com/8
- http://www.kibme.org/resources/journal/20220617110639497.pdf
- https://blog.testworks.co.kr/3d-ai-data-point-cloud/
Point Cloud
Point cloud 데이터를 수집하는 센서

LIDAR (Light Detection and Ranging):
LIDAR는 레이저를 사용하여 환경에 빛의 펄스를 보내고 그 빛의 반사를 감지함으로써 거리를 측정합니다(Time Of Flight). LIDAR의 출력은 3D 포인트 클라우드로 주어집니다. 이 센서는 자동차, 드론, 항공기 등 다양한 애플리케이션에서 사용되며 특히 자율 주행 자동차의 센서 중 하나로 널리 알려져 있습니다.
특히 자동차의 센서로 사용될 때는 고정식이 아닌 회전식 LiDAR를 더 많이 쓰고 있습니다.
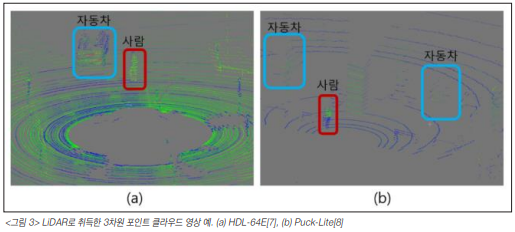
위 사진은 채널 수에 따른 선명도를 비교하기 위한 예시입니다. (a)사진은 채널 수가 64개인 liDAR를 사용하였고, (b)사진은 16개의 채널을 사용한 LiDAR를 사용하였습니다. 기본적으로 둘 다 가까운 물체가 멀리 있는 물체에 비해 더 조밀하게 샘플링이 된 것을 확인할 수 있습니다.
LiDAR를 이용하여 얻은 포인트 클라우드에는 3차원 좌표와 함께 반사되어 돌아온 신호의 강도를 나타내는 반사도 세기 정보도 포함되어 있습니다.
Structured Light Sensors:
이러한 센서는 특정 패턴의 빛 (예: 그리드 또는 스트라이프)을 물체에 투사하고 그 빛의 변형을 캡처하여 3D 정보를 얻습니다. Microsoft의 Kinect는 이러한 기술을 사용하는 대표적인 예입니다.
Stereo Cameras:
스테레오 카메라는 두 개의 카메라를 사용하여 같은 장면을 다른 시점에서 캡처함으로써 깊이 정보를 추출합니다. 두 이미지 간의 차이를 사용하여 각 픽셀의 깊이나 거리를 계산합니다.
Time of Flight (ToF) Cameras:
ToF 카메라는 빛의 펄스를 발사하고 그것이 목표물에 도달한 후 반사되어 돌아오는 시간을 측정하여 거리를 측정합니다. 이 방법은 LIDAR와 비슷하지만 전체 씬의 깊이 정보를 한 번에 얻는 데 사용됩니다.
Photogrammetry:
이는 여러 이미지에서 3D 정보를 추출하는 방법입니다. 사진들은 다양한 각도에서 촬영되며, 이 이미지들을 사용하여 3D 모델 또는 포인트 클라우드를 생성합니다.
3D scanner:
3D 스캐너는 주로 3D 객체의 외부 형태나 환경을 디지털로 캡처하기 위해 사용되며, 이를 통해 얻은 데이터는 주로 포인트 클라우드 형태로 제공됩니다.
3D 스캐너는 물체의 표면에서 수천 또는 수백만 개의 점을 빠르게 캡처하여 그 물체의 3D 표현을 생성합니다. 각 점에는 3D 공간에서의 위치 정보(x, y, z)가 포함되어 있습니다. 일부 3D 스캐너는 추가적으로 각 포인트의 색상이나 반사도 정보를 함께 제공할 수도 있습니다.
RGB-D:
3D 환경 정보를 캡쳐하는 센서로서, RGB 이미지 데이터와 함께 깊이(D) 정보도 함께 제공합니다.
"RGB" 부분은 일반적인 칼라 카메라와 같이 환경의 2D 이미지를 캡처하는 데 사용되며, "D"는 깊이 정보를 나타냅니다. 이 깊이 정보는 보통 미터나 피트 단위로 주어지며, 카메라 센서로부터 각 픽셀까지의 거리를 나타냅니다.RGB-D 센서를 통해 얻는 데이터셋은 포인트 클라우드 형태로 변환될 수 있습니다. 하지만 RGB-D 센서 자체에서 출력되는 원시 데이터는 일반적으로 깊이 맵(depth map)과 RGB 이미지의 형태로 제공됩니다.
깊이 맵(depth map)은 2D 이미지와 유사한 형태를 가지지만, 각 픽셀의 값이 카메라로부터 해당 픽셀까지의 거리를 나타냅니다. 이 깊이 정보와 RGB 이미지를 결합하여 각 픽셀의 3D 위치와 그에 대한 색상 정보를 얻을 수 있습니다.
이 정보를 사용하여 포인트 클라우드를 생성할 수 있습니다. 포인트 클라우드는 3D 공간에서의 점들의 집합으로, 각 점은 (x, y, z) 좌표와 RGB 값(또는 다른 색상 정보)을 가질 수 있습니다.
요약하면, RGB-D 센서는 원래 깊이 맵과 RGB 이미지의 형태로 데이터를 제공하지만, 이를 조합하여 포인트 클라우드 데이터를 생성하는 것이 가능합니다.
센서가 정보를 수집하는 방법
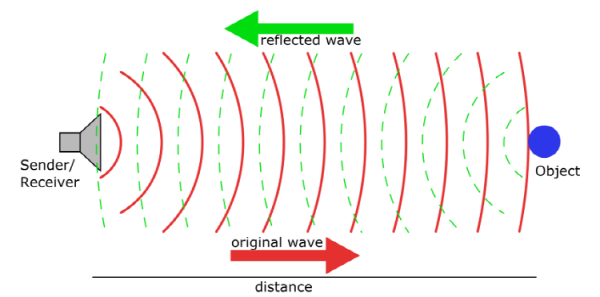
이러한 센서들은 그림처럼 물체에 빛/신호를 보내서 돌아오는 시간을 기록하여 빛/신호 당 거리 정보를 계산하고, 하나의 포인트(점)을 생성합니다. 이 방식을 Time Of Flight, TOF방식이라고 부릅니다.
Point Cloud란?

포인트 클라우드는 3차원 공간상에 퍼져 있는 여러 Point의 집합(Set cloud)를 의미합니다.
점군(Point Cloud)은 2D 이미지와 다르게 깊이(z축)정보를 가지고 있기 때문에, 기본적을 NX3의 numpy배열로 표현됩니다. 여기서 각 N줄은 하나의 점과 맵핑이 되며, (x,y,z)의 3차원 정보를 가지고 있습니다.
이미지 데이터와 Point Cloud
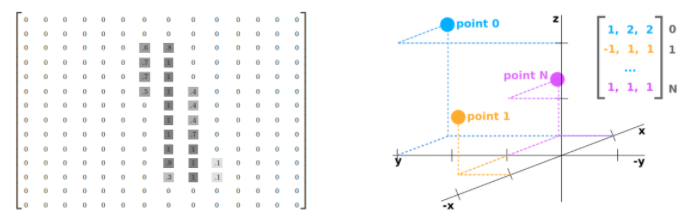
이미지 데이터에서 픽셀의 위치 정보는 항상 양수입니다. 기준점은 왼쪽 위 부터이며 좌표값은 정수로 표현합니다.
Point Cloud에서 점의 위치는 양수 또는 음수입니다. 기준점은 센서의 위치이며, 좌표값은 실수로 표현합니다.
기준점의 좌표에서 x, y, z 값은 다음과 같이 나타냅니다.
x : 앞, 뒤
y : 왼쪽, 오른쪽
z : 위, 아래
Point Cloud 데이터의 성질
현실에서 3D 공간 정보를 시각적으로 표현해 주는 데이터는 Point Cloud 데이터이다. 그렇기 때문에 3D 인공지능 연구 역시 Point Cloud 데이터 위주로 활발히 이루어졌다. 이미지 데이터와 마찬가지로 Point Cloud 데이터를 기반으로 한 Classification, Object Detection, Semantic Segmentation 등의 연구가 이루어졌다.
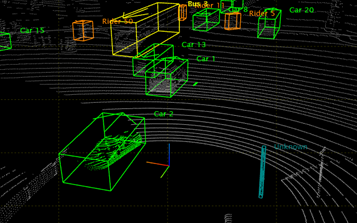 Point Cloud 기반 3D Object Detection
Point Cloud 기반 3D Object Detection
1. 정렬되어 있지 않고 정형화되어 있지 않은 데이터
 Point Cloud 데이터의 시각화 이미지(왼쪽)과 실제 저장 형태(오른쪽)
Point Cloud 데이터는 2D 이미지 데이터와 달리 정형화 되어있지 않습니다. 2D 이미지 데이터의 경우 정해진 격자 구조의 형태 안에 정보가 저장되지만, Point Cloud 데이터는 3D 공간상의 수많은 점들을 순서 없이 기록하는 방식으로 데이터가 저장됩니다. 이러한 데이터는 딥 러닝 모델에 있어서는 상당히 치명적입니다. 객체의 형상, 점들 간의 상호작용 등 데이터가 가지고 있는 기하학적인 특성을 파악하기가 상당히 어렵기 때문입니다.
Point Cloud 데이터의 시각화 이미지(왼쪽)과 실제 저장 형태(오른쪽)
Point Cloud 데이터는 2D 이미지 데이터와 달리 정형화 되어있지 않습니다. 2D 이미지 데이터의 경우 정해진 격자 구조의 형태 안에 정보가 저장되지만, Point Cloud 데이터는 3D 공간상의 수많은 점들을 순서 없이 기록하는 방식으로 데이터가 저장됩니다. 이러한 데이터는 딥 러닝 모델에 있어서는 상당히 치명적입니다. 객체의 형상, 점들 간의 상호작용 등 데이터가 가지고 있는 기하학적인 특성을 파악하기가 상당히 어렵기 때문입니다.
이를 해결하는 방법으로 Point Cloud 데이터를 Voxel 형태의 정형화된 데이터로 전처리하는 방법이 존재합니다. 하지만 이 방법 역시 다음 성질로 인해 3D 인공지능의 한계를 극복하는데 도움이 되지 못했습니다.
2. Sparse한 성질을 지닌 Point Cloud 데이터
 점에 비해 빈 공간이 훨씬 더 많은 Point Cloud 데이터
2D 이미지 데이터가 정해진 격자에 pixel 값이 모두 존재하는 dense한 특성을 지녔다면, Point Cloud 데이터는 매우 sparse한 성질을 가지고 있습니다. 부연 설명을 하자면, 주어진 데이터의 3D 공간 안에는 Point들에 비해 빈공간이 상당이 많다는 것입니다. 이러한 데이터는 크기에 비해 얻을 수 있는 유의미한 정보가 거의 없습니다. 이는 전 처리 작업을 통해 Point Cloud 데이터를 정형화 데이터로 변환하여도 동일하게 가지고 있는 성질입니다.
점에 비해 빈 공간이 훨씬 더 많은 Point Cloud 데이터
2D 이미지 데이터가 정해진 격자에 pixel 값이 모두 존재하는 dense한 특성을 지녔다면, Point Cloud 데이터는 매우 sparse한 성질을 가지고 있습니다. 부연 설명을 하자면, 주어진 데이터의 3D 공간 안에는 Point들에 비해 빈공간이 상당이 많다는 것입니다. 이러한 데이터는 크기에 비해 얻을 수 있는 유의미한 정보가 거의 없습니다. 이는 전 처리 작업을 통해 Point Cloud 데이터를 정형화 데이터로 변환하여도 동일하게 가지고 있는 성질입니다.
이러한 데이터로 인공지능 모델이 학습 될 경우 유의미한 정보를 거의 얻기 어려우며, 학습 난이도만 올리게 됩니다. 이로 인해 3D 인공지능 모델은 좋은 성능을 보여주지 못했고, 오랜 시간 이 상태가 지속되면서 Point Cloud 데이터를 다루는 초기 3D 인공지능 모델은 한계를 보였습니다.
Point Cloud 데이터를 다루는 3D 인공지능 모델
PointNet (2017):
PointNet은 포인트 클라우드 데이터를 직접 처리할 수 있는 첫 번째 심층 학습 아키텍처 중 하나입니다.
이 모델은 입력 포인트의 순서에 무관하게 고정 크기의 표현을 생성할 수 있습니다.
PointNet은 분류, 분할 및 의미론적 분할 작업에 사용될 수 있습니다.
PointNet++ (2017):
PointNet의 확장 버전으로, 지역적인 구조를 더 효과적으로 캡처하기 위한 계층적인 접근 방식을 사용합니다.
여러 크기의 이웃을 고려하여 포인트 클라우드의 다양한 규모에서 특징을 추출합니다.
VoxelNet (2017):
포인트 클라우드를 3D 복셀(voxels)로 나누고, 각 복셀 내의 포인트들을 고정 크기의 특징 벡터로 인코딩합니다.
주로 자율 주행 분야에서 객체 탐지에 사용됩니다.
Dynamic Graph CNN (DGCNN) (2018):
DGCNN은 가장 가까운 이웃을 기반으로 동적으로 그래프를 구성하여 포인트 클라우드 데이터에서 특징을 추출합니다.
이 동적 그래프 구조를 통해 CNN과 유사한 연산을 수행합니다.
PointCNN (2018):
포인트 클라우드 데이터를 처리하기 위해 CNN 연산을 적용하기 전에 입력 데이터를 균일한 그리드 형태로 변환합니다.
X-Conv 연산을 도입하여 공간적 순서를 갖는 데이터로 변환하고, 이후에 일반 CNN 연산을 적용합니다.
SECOND (2018):
"Sparsely Embedded Convolutional Detection"의 약자입니다.
VoxelNet의 후속 연구로, 복셀 기반의 특징 추출과 더 효율적인 3D 컨볼루션을 통한 객체 탐지를 제안합니다.
PointPillars (2018):
3D 포인트 클라우드를 수직 기둥(pillars)로 나누고, 이 기둥들의 정보를 2D 이미지 형식으로 표현하여 객체 탐지를 수행합니다.
기존의 복셀 기반 방법들보다 계산 효율성이 뛰어나며, 높은 정확도를 달성했습니다.
KPConv (2019):
Kernel Point Convolution (KPConv)는 변형 가능한 커널을 사용하여 포인트 클라우드 데이터에 컨볼루션을 적용합니다.
KPConv는 리기드와 디폼러블 두 가지 버전이 있습니다.
PointTransformer (2020):
Transformer 아키텍처의 개념을 포인트 클라우드 데이터에 적용합니다.
자기 주의 메커니즘을 활용하여 포인트 간의 관계를 모델링합니다.
