
이 글은 지난 6월 진행했던 초미세먼지 예측 모델(서울시 초미세먼지 예측 모델링 포스팅)을 실제 사용 가능한 프로그램으로 다듬어서 배포한 과정을 담고 있다. 모델은 단순하지만 머신러닝 모델의 저장과 로드(joblib), Standardization 값들로 학습된 모델에 넣기 위해 기존 학습데이터들의 분포도를 활용하여 새 데이터를 정규분포 상에 위치시키는 것 등을 학습해볼 수 있었다.
모델링 결과와 사용할 모델 선택

LSTM encoder(+attention)와 Random Forest로 실험한 결과 프로젝트에서 목표했던 Bad Recall 결과가 가장 좋았던 때는 Random Forest를 사용하면서 데이터 샘플링을 할 때 나쁨과 매우 나쁨 단계의 데이터 추출 비중을 높여줬을 때였다. 프로그램으로 만들어서 배포할 모델을 Random Forest (class weight [1,1,3,5]로 결정했다.
Bad Recall과 모델의 전체적인 목표에 대한 포스팅 -> Link
새로 들어온 데이터를 input data로 만들어보기
이제 새로운 데이터를 모델에 잘 들어갈 수 있도록 실험 때와 같은 모습으로 만들어줘야 한다. 아래의 과정들을 진행했다.
데이터 입력
우선 데이터를 어떻게 입력 받을지 고민해야 한다. 주피터 환경에서 데이터를 다룰 때는 pandas로 읽어서 dataframe 형태에서 처리했지만, 실제 서비스가 돌아갈 때는 txt 파일로 입력 받거나 실행 시에 하나의 샘플을 입력 받는 편이 빠르다.
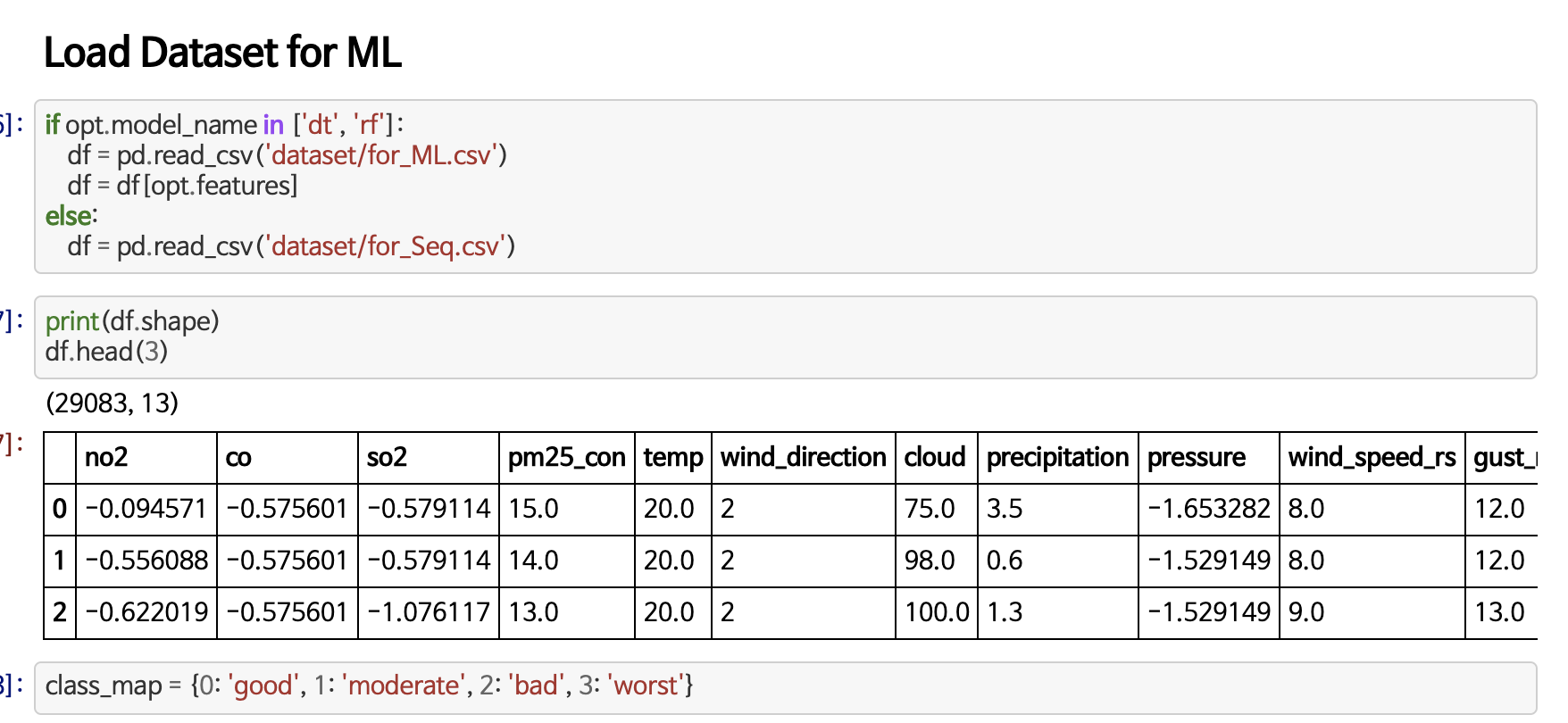

위 벡터와 같은 형태로 분석에 필요한 feature들을 입력 받아야 한다. txt 파일에 comma seperated 형태로 입력해 달라고 하면 사용자에게 과한 부탁일 듯하다. 파일로 입력하는 건 그렇다 쳐도 강수(precipitation)이나 구름의 정도(cloud) 등을 직접 찾아보지 못하는 상황이 많은데, 그런 결측값들을 'X'나 False로 정확히 입력해달라고 하는 건 사용자를 어렵게 만드는 방식인 듯했다.
그래서 argument parse 형태로 파일 실행시에 각 값들을 입력 받기로 했다. default를 자동으로 설정할 수 있기 때문에 입력하지 않은 값들이 생길 때에도 처리하기가 편하다.
여기서는 default를 False로, 그리고 이후에 데이터 전처리 과정에서 과거 10년(2008-2018) 간의 평균치로 그 False를 대체하도록 했다.
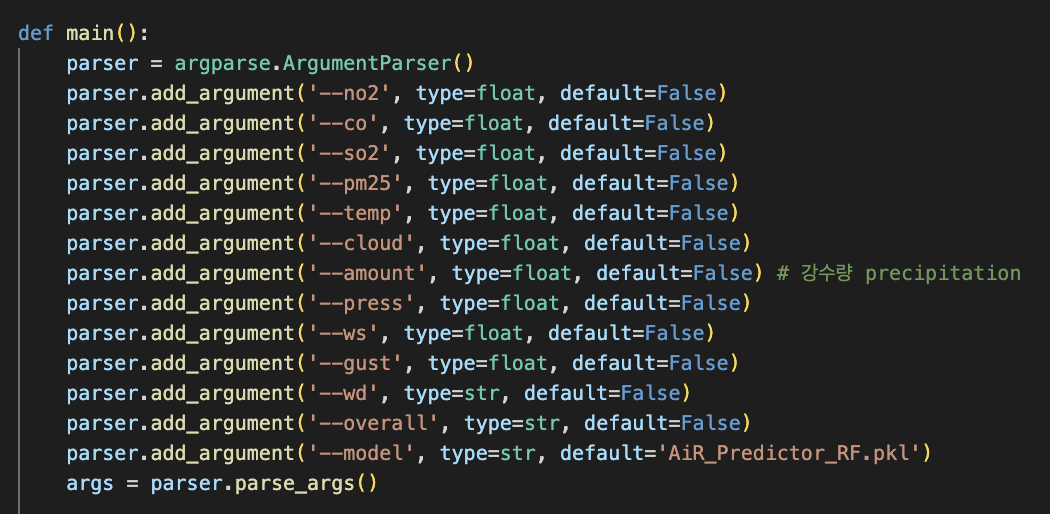
데이터 전처리
입력 받은 데이터를 모델에 들어갈 수 있는 형태로 바꿔준다.
학습 데이터의 분포 정보 로드
결측값을 처리하기 위해 학습 데이터의 평균 값이 필요하다. 또한 각 feature가 10년 간의 학습데이터에서 갖는 분포(mean, std)를 알아야 한다. Standardization을 거친 값들로 모델을 학습시켰기 때문에, 새 데이터가 그 분포 안에서 어느 위치에 있는지 파악해야하기 때문이다.
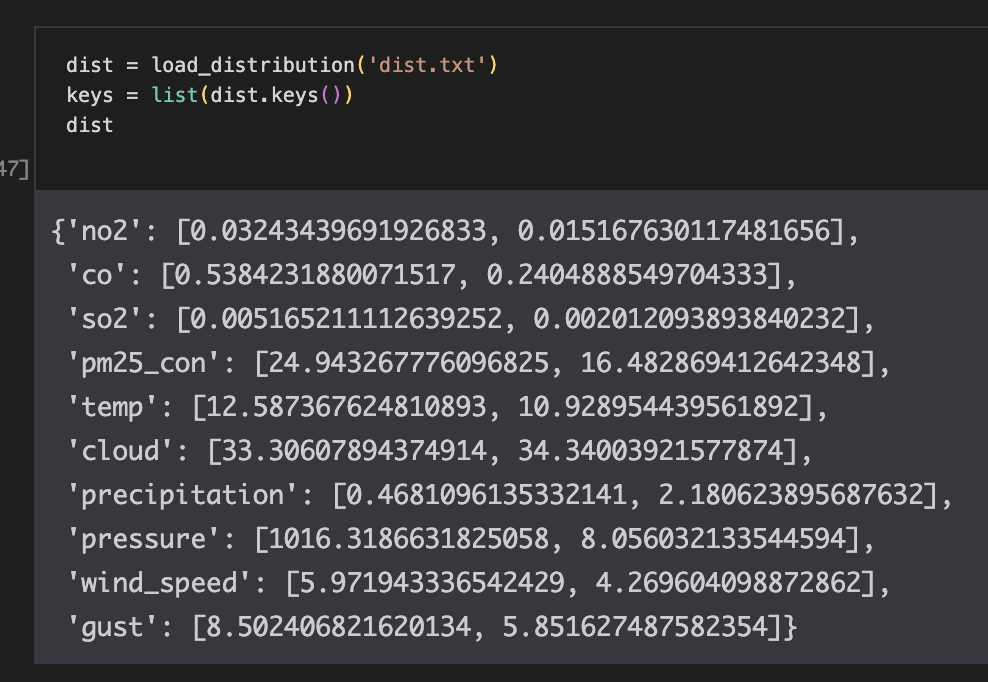
여기서는 non-categorical 피쳐들에 대해서 학습 데이터에서 갖는 평균과 표준편차를 위와 같은 형태로 가져왔다. 각 value에서 0번이 평균, 1번이 표준편차이다.
결측값을 평균치로 채우기
False를 갖는 피쳐는 value의 [0]번 데이터를 가져와서 그 값을 대체할 수 있도록 했다.
def fill_false(sample, dist):
keys = list(dist.keys())
for i in range(len(keys)):
if not sample[i]:
sample[i] = dist[keys[i]][0] # 평균치로 채우기
return sampleStandardization

앞서 학습 때에도 Standarization 방식으로 feature들을 re-scaling 했기 때문에 새로운 샘플에 대해서도 똑같이 진행한다. 지난 10년 간의 데이터로 그려진 분포에서 새 값들이 어느 수준에 위치하는지를 파악해서 input vector에 넣는 것이다. 처음부터 Min-Max scaler를 쓰지 않은 이유가 여기에 있다. 새 값들이 기존 min-max 범위 안에 들어있지 않을 경우도 많이 발생할테니.
standard = [0,1,2,7] # standardization idx: NO2, CO, SO2, pressure
for i in standard:
sample[i] = (sample[i] - dist[keys[i]][0]) / dist[keys[i]][1]학습 때 standardization을 진행했던 NO2, CO, SO2, pressure에 대해서 위와 같은 작업을 진행했다. new value에서 평균을 빼고 표준편차로 나눠주면 standization된 분포에서 갖는 위치값을 얻을 수 있다.
Encoding (Categorical) features
학습 때 진행했던 피쳐 전처리 과정을 똑같이 거친다. Target인 PM25 카테고리를 제외하고 총 12개의 피쳐들 중 풍향과 전체적인 날씨는 카테고리 데이터이기 때문에 그룹화 후 숫자로 인코딩이 필요했고, 풍속은 한국에서 주로 사용하는 mps(meters per second) 값을 받아서 mph(miles per hour)로 변환해준다. 또한, 학습 때와 마찬가지로 wind_speed와 gust 값들은 평균에서 너무 많이 벗어나는 데이터들을 줄여주기 위해 극한의 아웃라이어들을 사전 정의한 최대치로 내려주는 작업을 거치도록 했다. 풍속은 넉넉 잡아 20, 돌풍은 30으로 최대치를 잡았다. 10년 간의 학습 데이터 중 약 3% 정도가 그에 해당했다.
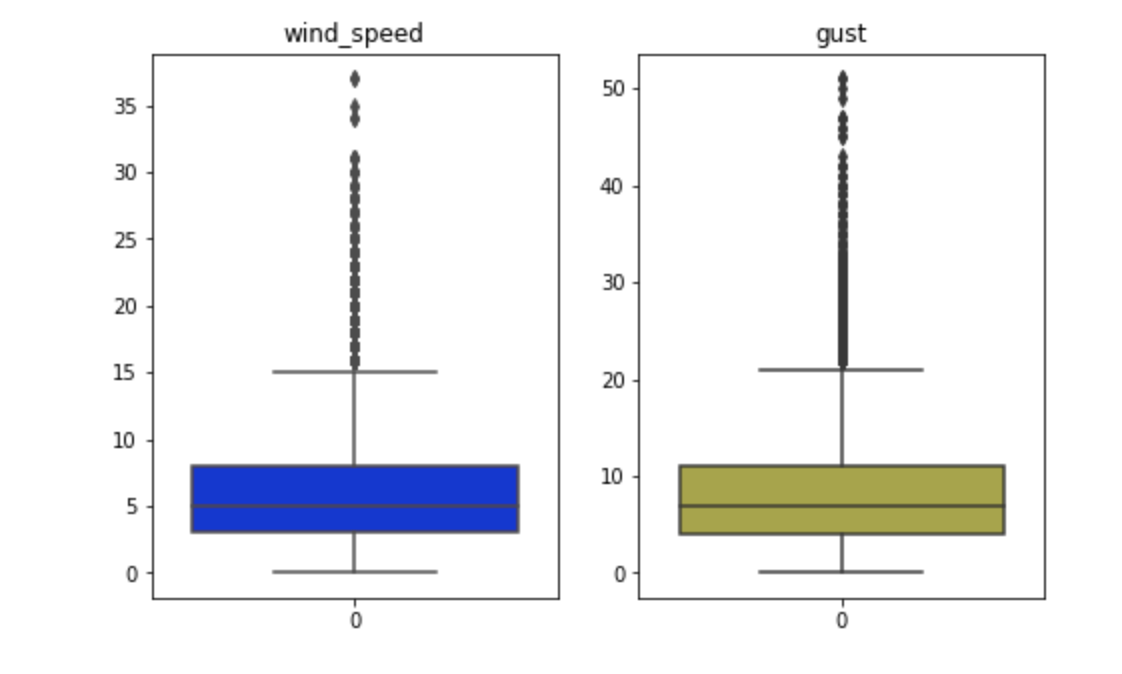

이 같은 전처리 작업을 해줄 수 있는 함수들은 Process_Features.py에 들어 있으며 main.py에서 import해서 가져다 쓰도록 했다.

Load Model
torch를 통해 딥러닝 모델의 weight를 저장하고 다시 가져다 쓰는 건 기본이지만, Scikit Learn으로 구현한 ML 모델을 저장해서 활용해 본적은 이번이 처음인 듯하다. sklearn의 모델들은 joblib이라는 라이브러리로 쉽게 모델을 파일로 출력해서 저장해뒀다가 쓸 수 있다. 이 프레딕터에서 사용할 모델 파일은 AiR_Predictor_RF.pkl에 저장되어있다. Document
model = joblib.load(args.model)args.model에는 모델파일(.pkl) 경로를 넣어준다. 모델을 불러온 후 추가로 이어서 더 학습시킬 수도 있다고 하니 머신러닝 모델링을 할 때에는 joblib을 유용하게 사용할 때가 있을 듯하다.
joblib은 원래 sklearn.externals에서 import 했지만 최신 버전으로 바뀌면서 곧바로 import joblib 으로 사용하게 됐다.
Classification
딥러닝 모델에서 단 한 개의 데이터라도 batch에 넣어 모델에 입력하는 것처럼 여기서도 X=[f1, f2, f3, ...]가 아닌 [X]= [[f1, f2, f3, ...]] 형태로 input vector를 만들어준다. 그리고 간단하게 model로 .predict 해주면 결과가 도출된다.

결과 출력
class_map = {0: '좋음', 1: '보통', 2: '나쁨', 3: '매우 나쁨'}사용자에게 필요한 것은 0, 1, 2, 3이라는 class(미세먼지 class)가 아니라 그 classification 값들이 갖는 의미이다. 따라서 class_map을 거쳐서 자연어로 정보를 출력하도록 했다.
print('>>>>>>>>>>')
print('3시간 뒤 초미세먼지(PM2.5) 농도는 {} 단계로 예상됩니다'.format(class_map[y]))
if y >= 2:
print('초미세먼지용 마스크를 준비해서 외출하세요!')
else:
print('초미세먼지용 마스크까지는 필요하지 않습니다')
return
개선 예정 사항 (To Do)
- 3시간 전이 아닌 12시간, 24시간 이후의 PM2.5를 예측하는 모델: Target의 특성상 단 3시간 만에 PM2.5 농도가 급하게 높아지거나 낮아질 가능성이 적다. 심지어 그게 input에 포함되기 때문에 이미 성능에 큰 영향을 주고 있을지도 모르겠다.
- Feature를 줄여서 학습시킨 모델: 돌풍(gust)나 구름(cloud) 등 직접 구하기 힘든 지표들이 있다. 이미 그런 방대한 데이터로 모델을 만들어놨기 때문에 새 데이터 입력 때도 같은 종류의 데이터를 찾아야 한다는 문제가 있다. 좀 더 유저가 찾아보기 쉬운 feature들로만 이뤄져 있으면서도 성능이 빠지지 않는 모델을 테스트해봐야한다.
- 대기질 정보(CO, SO2, NO, PM2.5 농도)는 단순한 포털 검색으로 찾기가 어려울 수 있다. 대기질 안내 페이지에서 크롤링을 해서 가져올 수 있도록 하면 좋을 것 같다. (크롤러를 붙여보기)
전체 프로그램은 -> github
