
서울시의 대기질 관련 데이터들을 가지고 이틀 동안 진행했던 작은 프로젝트에 대한 기록
데이터 확인
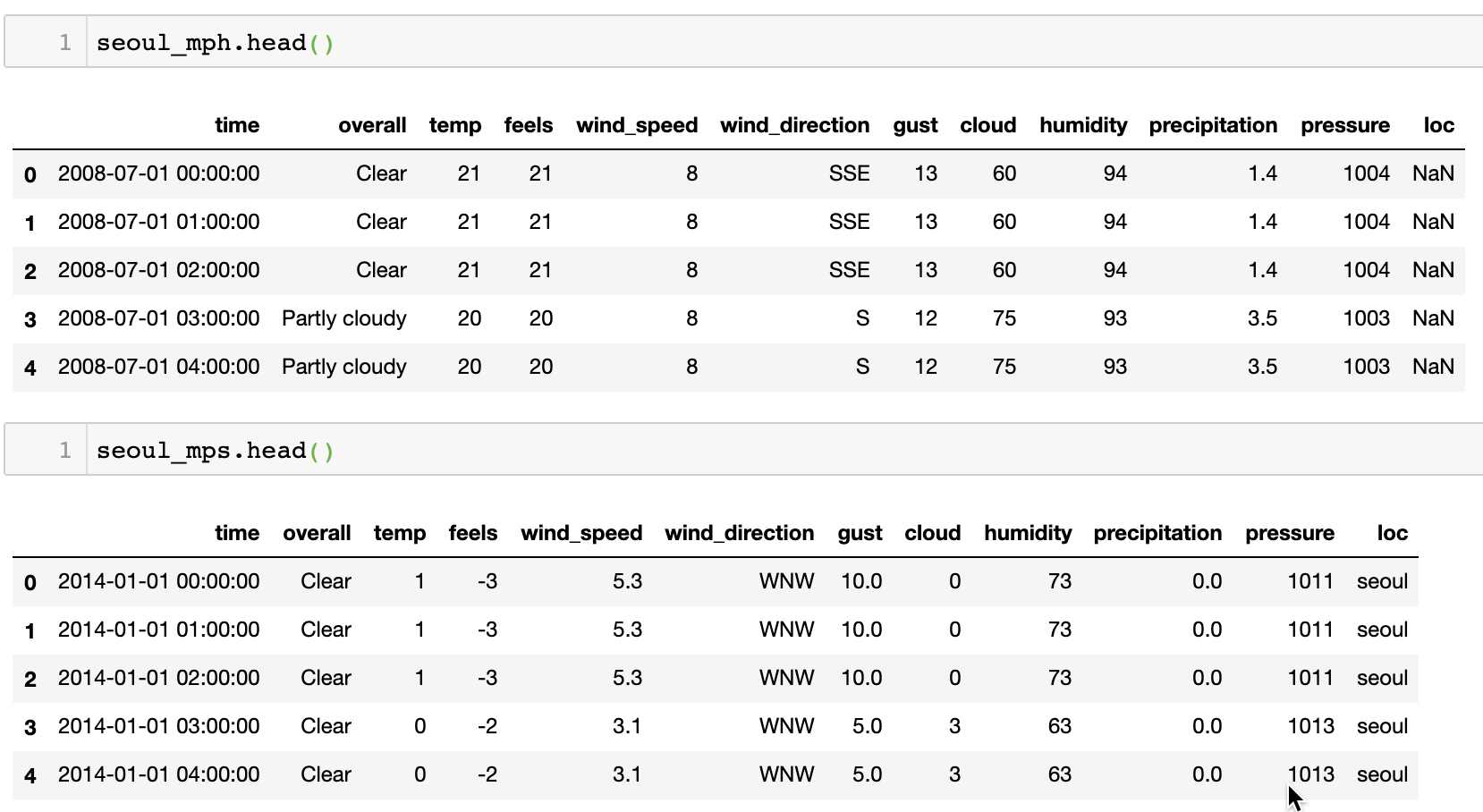
- 서울시 날씨 데이터 (2008-07-01 - 2018-04-10), 풍속 mph(mile per hour) 표기, shape:(85680, 12)
- 서울시 날씨 데이터 (2014-01-01 - 2018-12-31), 풍속 mps(meter per sec) 표기, shape:(43824, 12)
- 서울시 대기질 데이터 (2008-01-01 - 2018-06-18) shape:(2369634, 10)
- 모든 데이터는 한시간 단위로 기록되어 있음
- 1,2는 time, overall(전체적인 날씨), temp, feels(체감온도), wind_speed, wind_direction, gust, cloud, humidity, precipitation, pressure로 이뤄져 있음
- 3은 'time', 'district', 'pm10_con', 'pm25_con', 'o3', 'no2', 'co', 'so2', 'pm10_aqi', 'pm25_aqi'로 이뤄져 있음
목표 설정
Bad Recall Score: true positive bad air quality / truth bad air quality, where bad air quality means bad and worst.

-
실제로 초미세먼지(pm2.5) 농도가 bad, worst 일 때, 우리가 마스크를 끼고 있지 않을 가능성을 최소화 하자. Recall은 사건 A가 실제로 발생했을 때 그 발생을 얼마나 맞춰냈느냐를 보는 지표이다. 그래서 위 목표를 'Bad Recall Score'라 이름 붙였다.
-
1시간 단위가 아니라 3시간 이전의 데이터를 기반으로 초미세먼지 농도를 예측한다. 데이터셋은 1시간 단위로 존재해서 row가 매우 많지만, 우리가 실제로 매시간마다 농도를 궁금해하지 않겠다고 생각했다.
-
마지막으로 regression이 아닌 classification으로 문제를 재정의했다. 우리가 정확한 농도를 알아야 하는가? 아니면 미세먼지 단계를 알면 될까? 질문에서 후자에 무게를 실었다. 단계는 한국 기준으로 진행할 것이다.
데이터 통합 (join, concatenate)
세 가지 데이터셋을 하나로 통합했다.
- 우선 데이터1(서울날씨mph)와 데이터2(서울날씨mps)를 통합했다. 둘이 겹치는 기간이 있는데 mph 데이터를 사용했고, mps 데이터만 있는 기간 (2018-04-11 - 2018-12-31)은 풍속 단위를 mph로 바꿔주었다. Mph는 int 형태로 반올림 처리가 돼 있었던 반면 mps는 float 형태로 남아 있었기 때문에 mph -> mps 보다 mps -> mph 변환에서 미세 손실이 적을 것이다.
def mps_to_mph(spd):
return int(spd*3600*0.000621)
mps['wind_speed'] = mps['wind_speed'].apply(mps_to_mph)
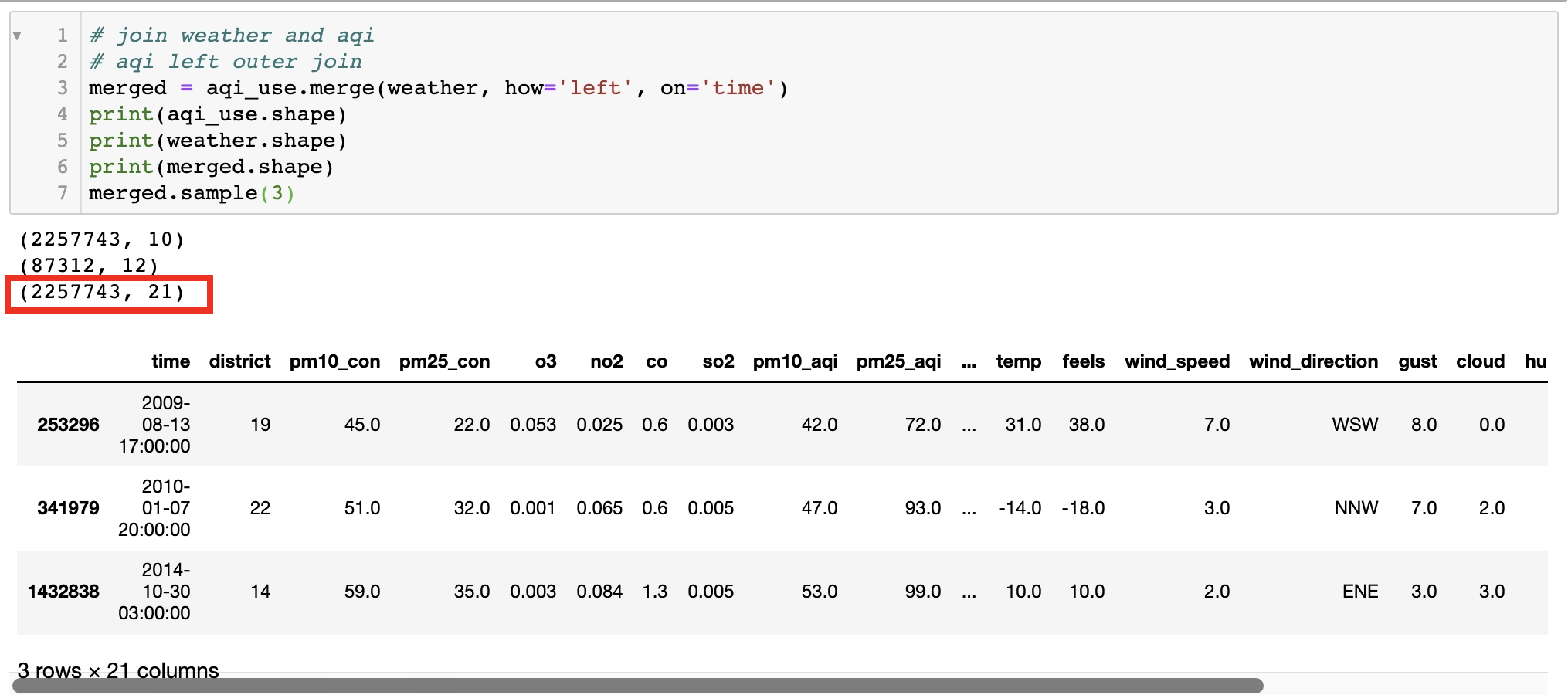
mps['gust'] = mps['gust'].apply(mps_to_mph)- 가장 중요한 데이터는 데이터3(서울 대기질)이다. 우리의 목표 변수인 PM2.5가 포함되어 있다. 이게 없으면 나머지 변수들은 의미가 없다는 뜻이다. 따라서 데이터1,2를 통합한 데이터의 기간과 데이터3의 기간이 겹치는 부분(2008-07-01 - 2018-06-18)에서 데이터1+2와 데이터3을 합쳤다. 아래 코드처럼 time을 key로 하고 데이터3(aqi: air quality index)에 데이터1+2(서울날씨) 데이터를 JOIN했다.
merged = aqi_use.merge(weather, how='left', on='time')- 결과적으로 2,257,743개의 row와 21개의 feature를 가진 데이터 테이블을 만들었다. 다음에는 이 데이터를 살펴보면서 모델에 들어갈 수 있도록 데이터를 변형해보겠다.
모든 코드는 > github

Graduate School of DataScience, NLP researcher. AI engineer at NAVER PlaceAI