
앞선 단계에서 리뷰에 맞는 전처리 작업들을 했으니, 이제 이 네 가지 상품군(스마트워치, 립스틱, 무드가습기, 블루투스스피커)에서 각각 주요 단어(aspect word)가 될 수 있는 단어들을 통계적으로 선별해본다.
어려운 이유, 답이 없다..
이 작업이 어려운 이유는 정답이 없기 때문이다.
Aspect word라는 건 단지 많이 등장하는 명사인가? Pre-defined된 카테고리(기능, 내구성, 디자인, 가격, 배송 등)에 속하는 단어들이어야만 하는가? 그렇다면 카테고리는 어떻게 결정하는가? 사실 규칙이 명확하게 있다면 labeling을 하는 건 쉽지 말이다...
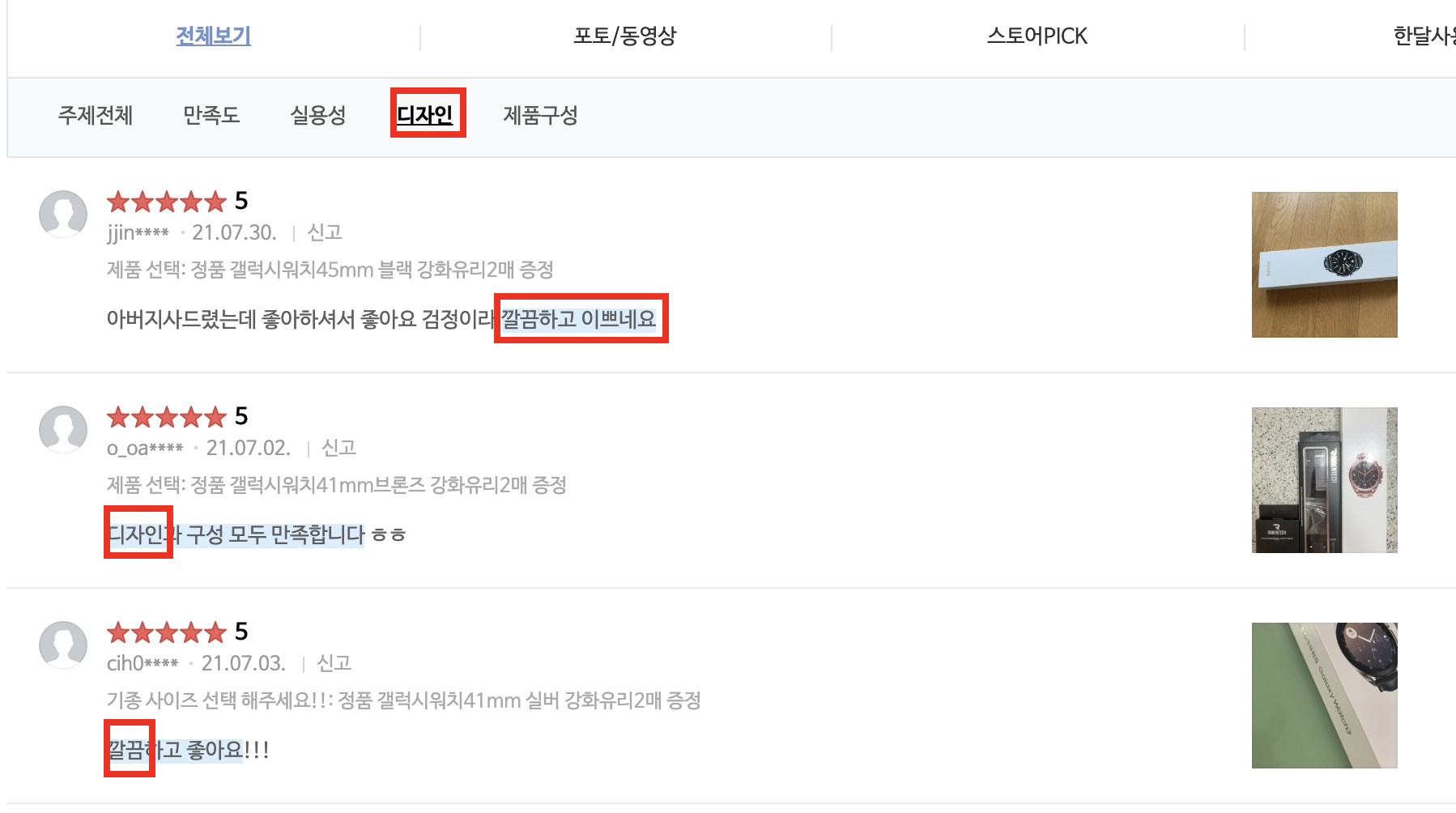
디자인 이라는 카테고리를 눌러보면 꼭 '디자인'이라는 단어가 들어 있지 않고, 또는 어떤 명사형 aspect word가 포함되어 있지 않더라도 주요 표현으로 주목하고 있다. ex)'깔끔하고 이쁘다'
ABSA의 대표 데이터셋인 SemEval에서는 aspect는 거의 명사형이며 주요 카테고리를 설명할 수 있는 단어가 된다. 그리고 그에 붙은 서술어나 관형어 ("깔끔하다")를 opinion라 부른다.
여기서는 트레이닝을 위한 세트를 만들어야 하는데 하나하나 검수하면서 라벨링을 할 수가 없기 때문에 '명사형' 이면서 00번 이상 등장한 단어라는 제약 조건을 걸어본다. 조건에 따라 일단 통계적으로 뽑아서 모델을 학습시킬 수 있을 정도의 데이터셋을 구축해보는 게 목표이다.

선정 과정
- Tokenize: 사전 결정한 Khaiii를 활용해서 형태소 tokenize
- Counter: 등장횟수를 파악해서 단순하게 많이 등장하는 단어들을 고려
- Customized TF-IDF: TF-IDF를 모방한 방식으로 특정 상품군에서 특히 많이 등장하는 단어들을 고려
- 노동.. 검수: 선별한 단어들의 적합성을 직접 검증해보기
1. Tokenize
앞서 리뷰 데이터셋 구축에 적합한 토크나이저를 비교해본 적이 있다. 관련 포스팅 Khaiii를 활용해서 형태소 단위로 리뷰를 쪼갰다. Mecab()에 비해 3~4배 정도 시간이 많이 소요되었던 것 같다. Khaiii는 .analyze 메소드를 써서 자체 정의한 클래스로 값이 return되기 때문에 아래와 같이 .morphs와 str()을 붙여줘서 하나하나 반환 객체를 만들어줘야 한다.
def get_tokenized(reviews, tokenizer='khaiii'):
rst = list()
if tokenizer=='khaiii':
def use_khaiii(text):
api = KhaiiiApi()
result = list()
for sent in api.analyze(text):
result += sent.morphs
return [str(word) for word in result]
for review in reviews:
rst.append(use_khaiii(review))
return rst
이와 같은 형태로 morphs 단위로 자를 수 있다. 시간이 꽤 필요하니 한번 자른 것은 꼭 txt파일로 저장해두자.
2. Counter
웬만한 크기의 데이터에서 크게 차이는 건 아니지만, collections.Counter 보다 직접 loop를 돌면서 count dict를 만드는 게 속도가 빠르다. (수 차례 실험에서 얻어진 결과) 아래와 같은 함수로 'NNG'(일반명사)의 태그를 갖고 있으면서 길이가 2 이상인 단어들을 Counter에 추가해주었다. 우리는 명사형의 aspect를 추출할 생각이기 때문이다.
def get_word_count(tokenized: List[List]) -> dict:
vocab = dict()
for sentence in tokenized:
for word in sentence:
if word.split('/')[1] in ['NNG'] and len(word.split('/')[0]) >= 2: # 길이 2 이상, 일반명사, 고유명사(NNP)는 제거
if word in vocab: vocab[word] += 1
else: vocab[word] = 1
return vocab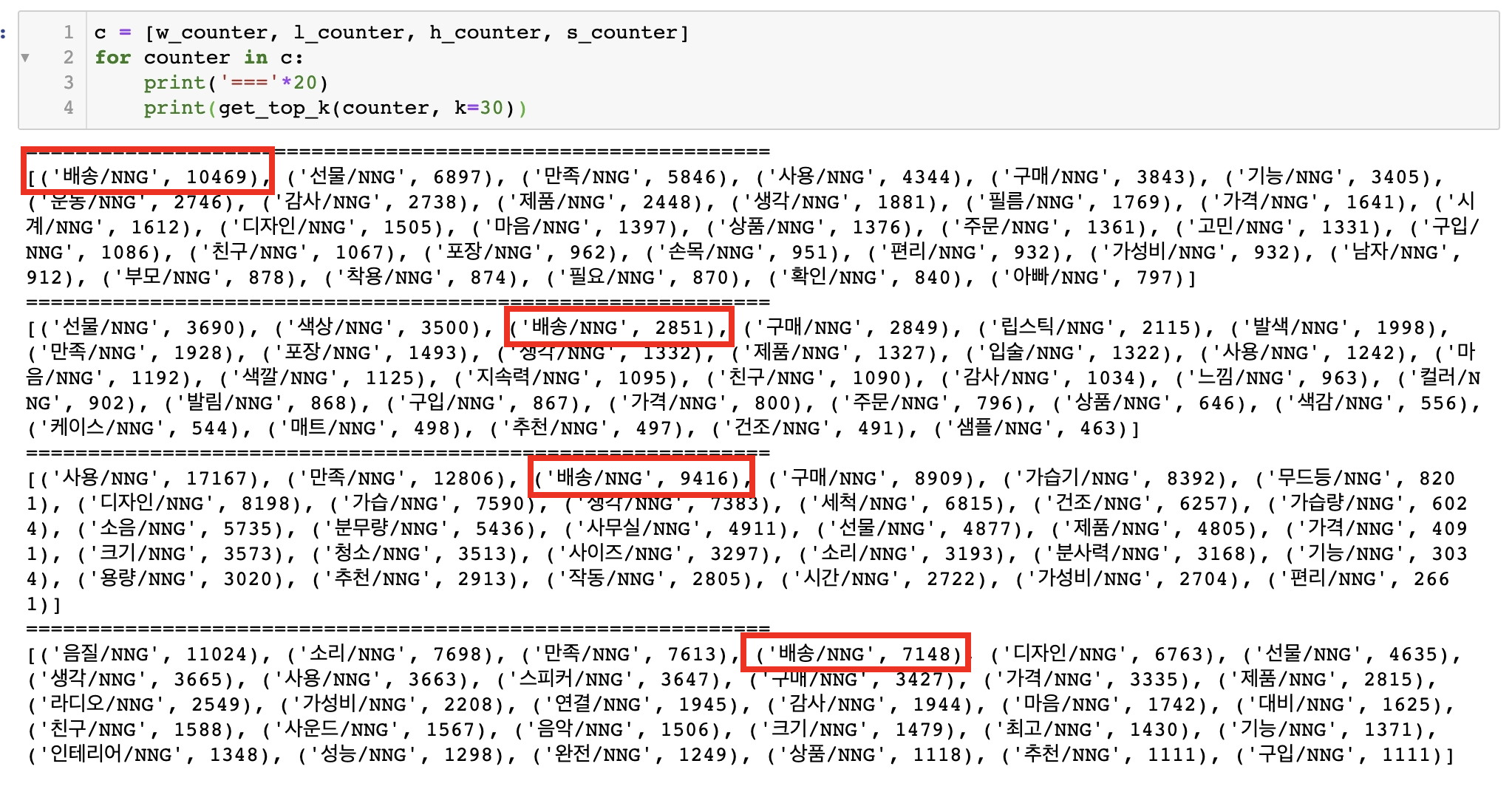
상위 30개씩 뽑아본 결과, '배송', '선물', '가격', '디자인' 등이 공통적으로 등장했다. 나중에 aspect seed라 부를만한 단어들을 선정할 때 여기서 적절히 상위권에서 끊어서 반영하게 된다.
3. Cumstomized TF-IDF
TF-IDF (Term Frequency - Inverse Documnet Frequency)는 어떤 쿼리문에 가장 관련도가 높은 문서를 찾아낼 때 유용한 계산 방식이다.
TF(d,t)는 문서 d 안에서 쿼리 단어 t가 등장하는 횟수이고, IDF(d,t)는 단어 t가 등장하는 문서의 수에 반비례하는 수치이다. TF-IDF는 이 둘을 곱해준다. 아래 IDF식에서 df(t)는 단어 t가 등장하는 문서들의 숫자이다. 즉, 해당 문서에서 많이 등장하면서 다른 문서들에서는 적게 등장할 수록 이 스코어가 높다. 마침 검색엔진을 Haystack으로 구축해봤던 경험을 소개했던 글(링크)에서 설명을 해두었으니 참고.
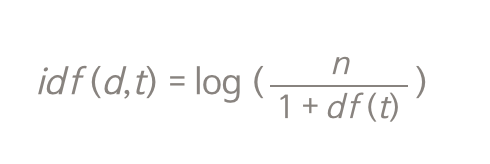
아래는 TF-IDF와 비슷한 개념으로 Score를 뽑아내는 BM25(Best matching) 알고리즘. 복잡해보이지만 단어q가 등장하는 문서의 수가 분모에 오고(반비례), 해당 문서 내에서 단어 q가 등장하는 수가 분자에 온다는 점(비례)에서 TF-IDF와 유사한 의미를 갖는다.

본론으로 들어가서, 여기서는 다른 상품군 리뷰에는 많이 들어있지 않으면서 해당 상품군 리뷰에만 유의미하게 많이 들어있는 단어들을 찾아낼 수 있도록 위 방식들과 유사한 score metric을 만들어보았다.
-
counters: 각 상품군의 counter dict를 포함한 list
-
target_idx: 우리가 스코어를 뽑고 싶은 상품군이 counters list에서 몇 번째에 들어있는지
-
threshold: 높은 스코어를 갖는다 해도 리뷰에서 워낙 조금만 등장하면 의미가 없을 수 있기 때문에 이 threshold 이상 등장하는 단어들만 걸러내기 위해 사용
-
TF는 말 그대로 그 문서 속에서 word A가 등장하는 횟수
-
IDF는 Document Frequency라는 본래 의미와 달리 여기서는 다른 상품군에서 word A가 평균적으로 등장하는 횟수로 했다.
다시 말해, 해당 상품군 리뷰에는 많이 등장하면서 다른 상품군 리뷰에서는 잘 등장하지 않을 수록 높은 스코어를 갖는 방식이다. 상품군에 특화된 aspect들을 찾기 위함이다.
def get_TFIDF(counters, target_idx, threshold):
rst = dict()
c_else = counters[:]
c_target = c_else.pop(target_idx)
for word in c_target:
tf = c_target[word]
if tf < threshold: continue # 리뷰에서 threshold 이하로 등장한다면 그냥 pass
# IDF는 해당 단어가 다른 항목 리뷰들에 평균적으로 포함된 수
cum = 0
for c in c_else:
if word in c:
cum += c[word]
idf = cum / len(c_else)
rst[word] = round(tf/(idf+1), 4) # TF를 IDF+1로 나눈 숫자
return rst
위에서부터 스마트워치, 립스틱, 무드가습기, 블루투스스피커 순이다. 모든 단어들이 유의미한 것은 아니지만 각각 그 상품군의 리뷰에서 유의미한 aspect를 대표할 수 있는 단어들이 꽤나 많이 포함되었다고 판단했다.
- 워치: 착용감, 심박수, 스트랩 등
- 립스틱: 발색, 발림, 발색력, 지속력 등
- 가습기: 가습량, 분무량, 세척, 분사력 등
- 스피커: 음질, 사운드, 음향, 음량 등
다음에는 단순히 많이 등장한 단어들 + 해당 상품군에서만 많이 등장한 단어들 + 공통적으로 포함시키고 싶은 소수의 단어들을 SEED aspect words라 이름 짓고 이들을 기반으로 W2V 형태의 임베딩 벡터 학습을 통해 aspect 단어가 될만한 후보들을 찾아보는 작업을 진행했다. (다음 포스팅에서)
