
서울시의 대기질 관련 데이터들을 가지고 이틀 동안 진행했던 작은 프로젝트에 대한 기록
목표에 적합한 데이터만 남기기
앞서 목표를 정할 때, 3시간 마다의 데이터를 사용해 3시간 후의 PM2.5 농도를 예측하기로 했다. 그리고 서울시 전역의 평균값을 예측할 것이기 때문에 district(구) 값은 0번(서울 전체 평균)만 남긴다.
# distirct==0만 남기기
df1 = merged.loc[merged['district']==0].reset_index(drop=True)
# datetime 형태로 변환 후 시간만 추출
df1['time'] = pd.to_datetime(df1['time'])
def get_hour(time):
return time.hour
df1['hour'] = df1['time'].apply(get_hour)
# 0, 3, 6, 9, ..., 21시 데이터만 남기기
df2 = df1.loc[(df1['hour']==3) | (df1['hour']==6) | (df1['hour']==9) | (df1['hour']==12) | (df1['hour']==15)\
| (df1['hour']==18) | (df1['hour']==21) | (df1['hour']==0)]
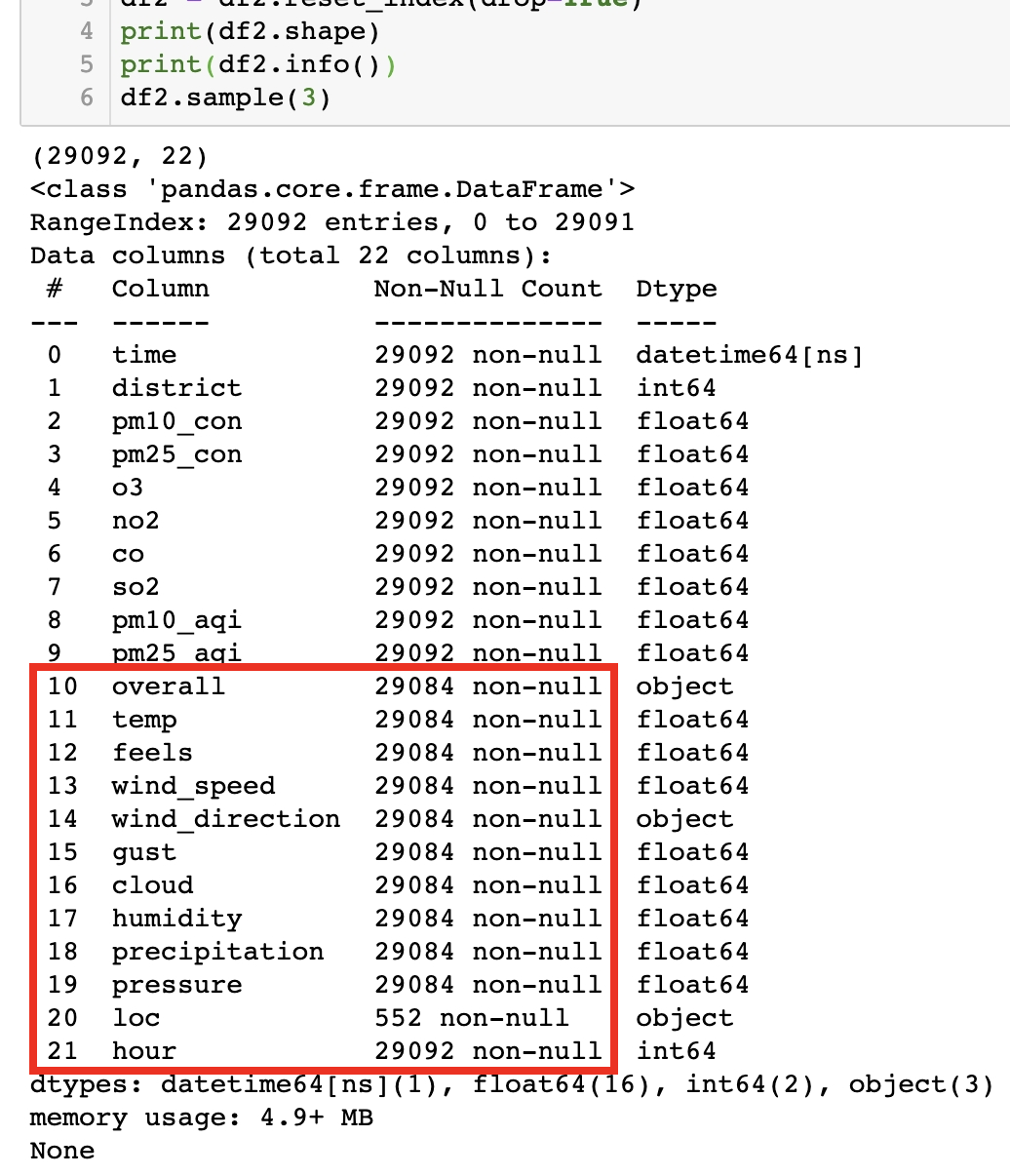
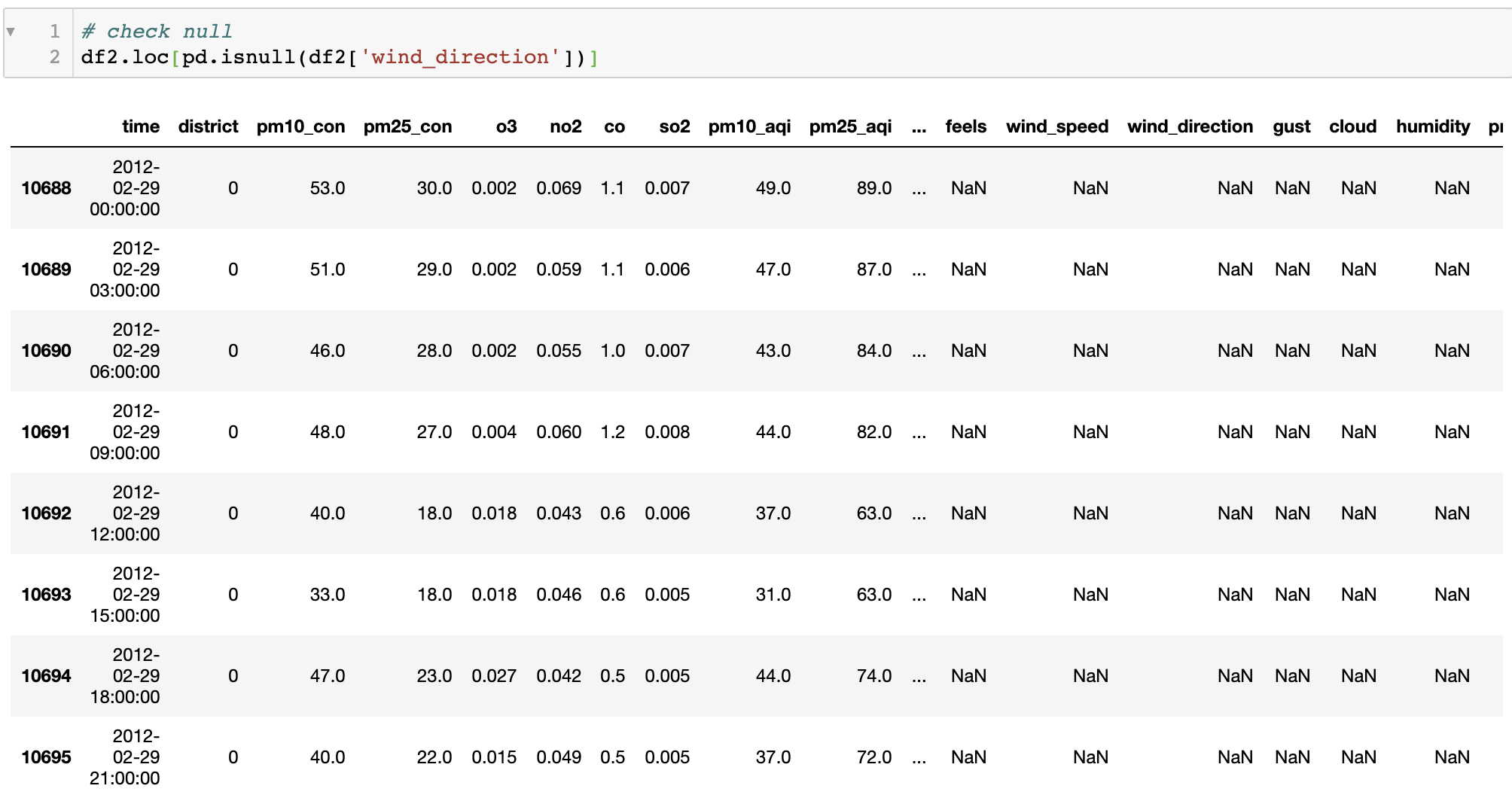
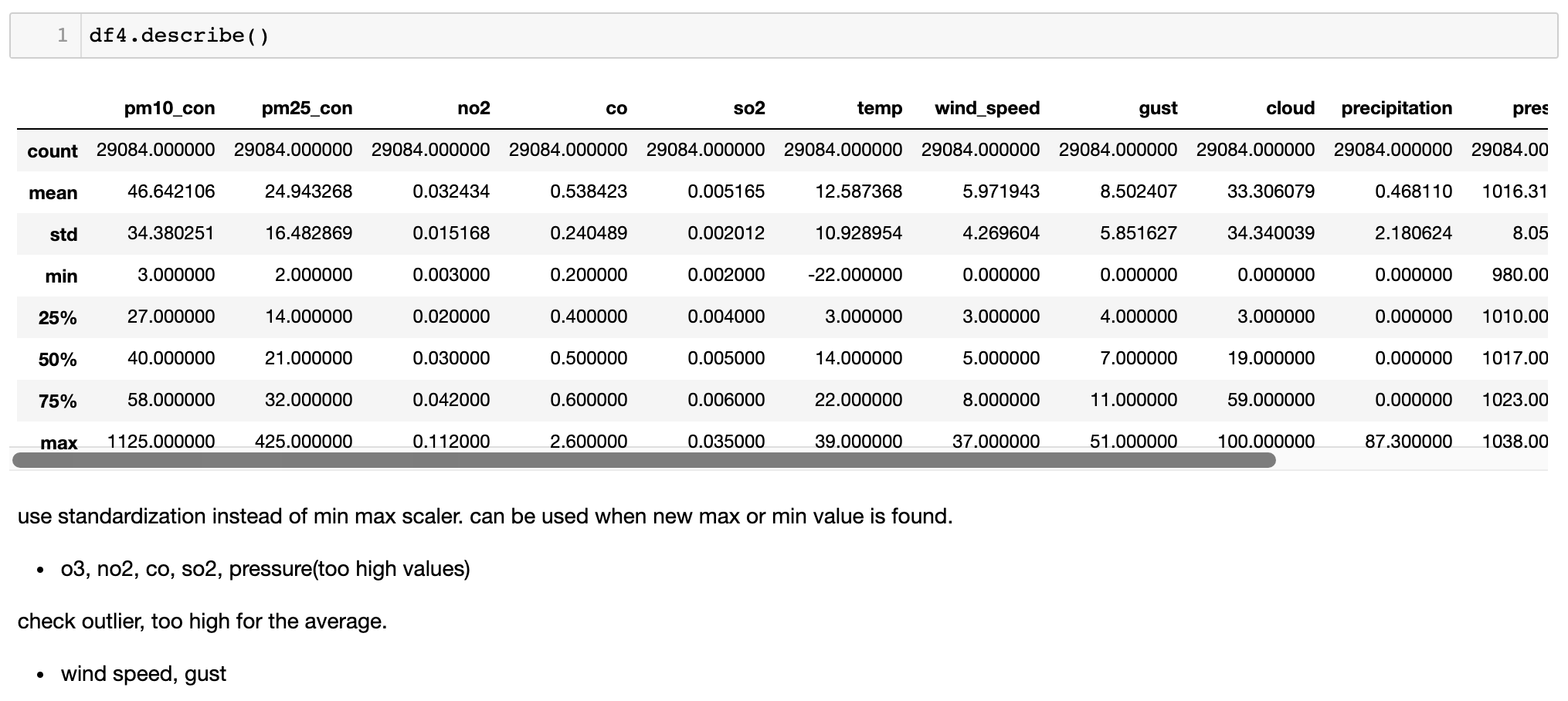
df2 = df2.reset_index(drop=True)3만개 이하의 데이터로 줄었으며, 아래처럼 날씨 데이터 어느 부분에서 8개의 null 값이 존재함을 알 수 있었다. 대기질 데이터를 기준으로 JOIN을 했기 때문에 아마 대기질 데이터는 있으면서 날씨 데이터는 없었던 날이 중간에 끼어있었을 것으로 보였다. 그래서 한 개의 column을 골라 null 값을 가진 날짜를 찍어봤더니 2012년 2월 29일이 나왔다. 저 윤년의 추가일에 무슨 일이 있었는진 모르겠지만 데이터가 포함되지 않았기 때문에 그 날은 통째로 날리는 것으로 했다.
Feature Engineering
이 부분은 너무 주관적이기도 하고 수학적으로 근거가 부족하기도 하다. 또한 수학적 근거를 갖고 feature selection을 진행했다 하더라도 모델이 더 좋은 퍼포먼스를 보이는 데에 좋지 않은 경우도 있다. 도메인 지식도 함께 필요한 이유이다. 따라서 코드 참고 정도만..
Feature간 co-relation을 파악하여 feature 선택
사실 corr 데이터만 가지고 feature를 drop 하는 것은 잘못된 선택이다. 인과관계를 나타내지 못하고 A와 C가 관계가 없더라도 A->B->C 순으로 관계를 갖고 있을 수도 있다. 실제로는 시간을 가지고 여러가지 feature로 모델 테스트를 해보아야 할 것이다.
본 프로젝트에서는 0번만 남길 district, 미국 지수 기준인 pm10_aqi와 pm25_aqi, 온도로 설명이 가능한 체감온도, 서울시 표기가 되어있는 loc, 그리고 타겟과 상관도가 매우 떨어졌던 두 개의 feature를 제거했다. 습도를 없앨 때 고민이 되었는데 'overall'에 비나 눈 표기가 되어 있기 때문에 미세먼지에 영향을 줄 습도는 설명이 가능할 것으로 보고 자의적으로 제거하였다.
list_drop = ['district', 'pm10_aqi', 'pm25_aqi', 'feels', 'loc', 'humidity', 'o3']
df3 = df2.drop(list_drop, axis=1)범주형 변수(categorical)를 범주화(categorize)
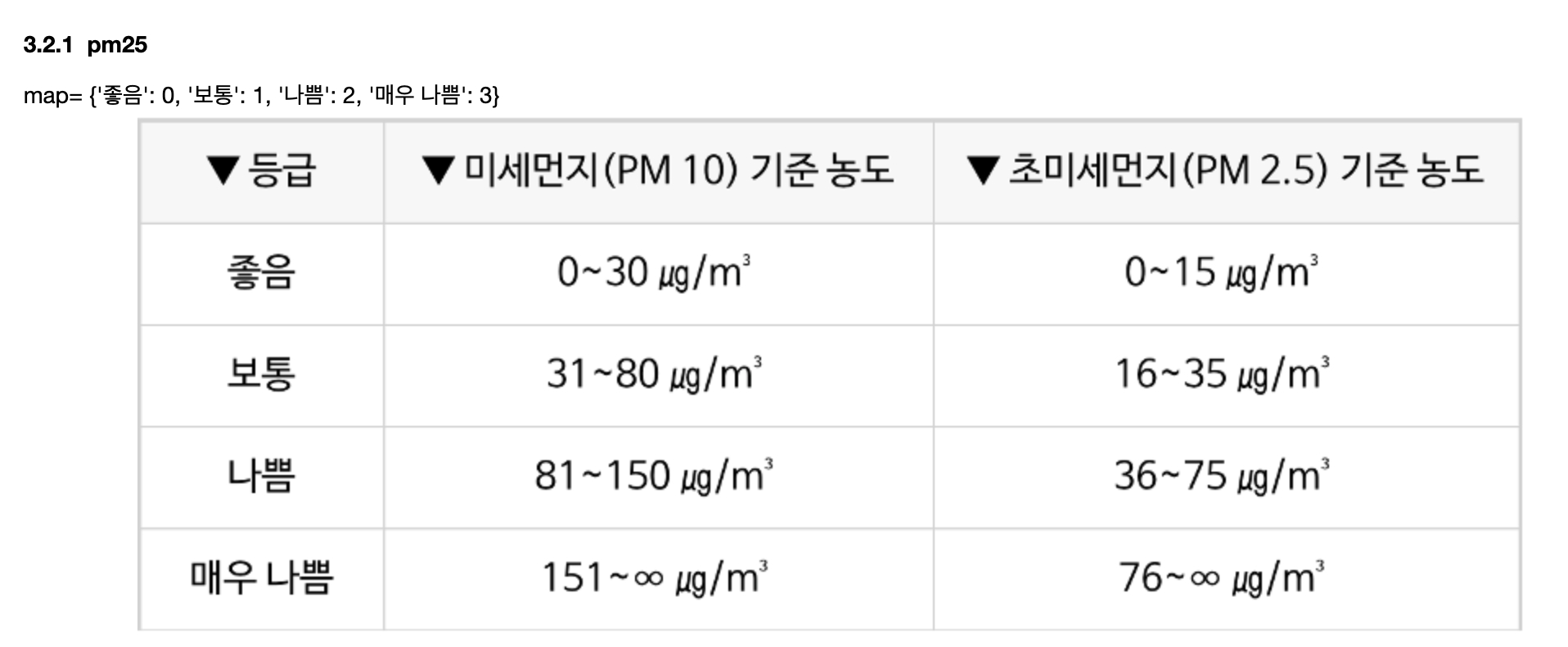
Overall, wind direction, pm25 값들을 범주화 해주었다. PM2.5 농도는 한국 기준으로 구분을 하였다. 목표 설정을 할 때부터 고민을 했던 부분인데 우리가 정확한 농도를 알아야 하는가? 아니면 미세먼지 단계를 알면 되는가? 질문에서 후자를 선택하게 되었다. 따라서 Regression이 아닌 Classification으로 문제를 재정의하고 농도를 범주화했다.
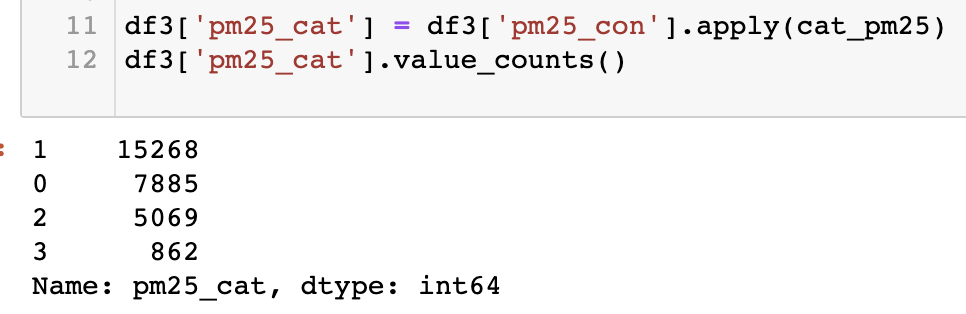
그 결과 아래와 같은 통계를 볼 수 있었다. 0(좋음), 1(보통)이 약 23,000여 개로 데이터의 대부분을 차지했다. 2008년부터 '18년까지의 우리나라 날씨 대부분은 그래도 마스크를 끼지 않아도 되는 날씨였나보다.
또한 우리는 나쁨, 매우나쁨 단계를 골라내야하는데 학습 데이터에 이런 샘플들이 부족하다는 것을 알 수 있었다. Data augmentation 방법이 있을지 고민해보는 것도 좋은 방법일 것이다.
- wind_direction은 16가지가 존재했는데 4개로 줄였다.
- 개수가 많은 방향이 우세 ('WSW': 'W')
- 개수가 동일할 때는 'N', 'S' 보다 'W', 'E' 우세 ('SE': 'E')
남북보다는 중국 서해안과 관련이 있는 동서풍이 중요하다고 보았기 때문이다.
- overall은 수십가지의 종류가 있었는데 강수가 있는지 여부에 따라 0과 1로 통합하였다. 비나 눈이 내리는 날엔 미세먼지 농도가 낮았고 실제로 데이터에서도 그 부분을 확인할 수 있었기 때문이다.
# PM25 카테고라이징 & 인코딩
def cat_pm25(val):
if val < 15:
return 0
elif 15 <= val < 35:
return 1
elif 36 <= val < 75:
return 2
else:
return 3
df3['pm25_cat'] = df3['pm25_con'].apply(cat_pm25)
# 풍향 카테고라이징 & 인코딩
wind_map = {'NW': 'W', 'WSW': 'W', 'WNW': 'W', 'W': 'W', 'SW': 'W', 'SSW': 'S', 'E': 'E', 'ENE': 'E',
'ESE': 'E', 'NNW': 'N', 'SE': 'E', 'S': 'S', 'SSE': 'S', 'NE': 'E', 'NNE': 'N', 'N': 'N'}
def cat_wind(val):
return wind_map[val]
df3['wind_direction'] = df3['wind_direction'].apply(cat_wind)
wind_map_int = {'W': 0, 'E': 1, 'S': 2, 'N': 3}
def encode_wind(val):
return wind_map_int[val]
df3['wind_direction'] = df3['wind_direction'].apply(encode_wind)
# 전체적인 날씨 카테고라이징 & 인코딩
rain = set(['drizzle', 'rain', 'snow', 'sleet'])
def cat_overall(val):
if set(val.lower().split()) & rain:
return 1
else:
return 0
df3['overall_int'] = df3['overall'].apply(cat_overall)Re-scaling
데이터 분포가 너무 좁거나 넓은 경우, 그리고 다른 데이터들에 비해 절대적으로 매우 큰 값만을 가지는 경우에는 학습력이 떨어질 수 있다. 특히 딥러닝 모델에서는 큰 절대값을 갖는 숫자를 더 중요한 feature로 인식하게 될 수 있기 때문에 모든 값들의 re-scaling이 필요하다고 봤다.
O3, NO2, CO, SO2와 같은 대기질 지표들은 편차가 매우 작으면서 값들이 작았다. 또한 pressure는 편차가 작으면서 혼자 1000 이상의 큰 값들을 가졌다. 적절한 분산을 주기 위해 re-scaling이 필요하다고 판단. 다만 가볍게 사용하던 min-max scaler 대신 standardization을 사용하기로 했다. 왜? 새로운 test case 값들이 들어왔을 때 min-max 범주를 벗어난다면 어떤 값을 적용하기가 어렵다. 반면 10년 간의 데이터로 표준화를 해두면 어떤 아웃라이어들도 표기는 가능할 것이라 생각했다.
from sklearn import preprocessing
cols_standard = ['no2', 'co', 'so2', 'pressure']
scaler = preprocessing.StandardScaler().fit(df4[cols_standard])
modified = pd.DataFrame(scaler.transform(df4[cols_standard]), columns=cols_standard)
df5 = df4.copy()
for col in cols_standard:
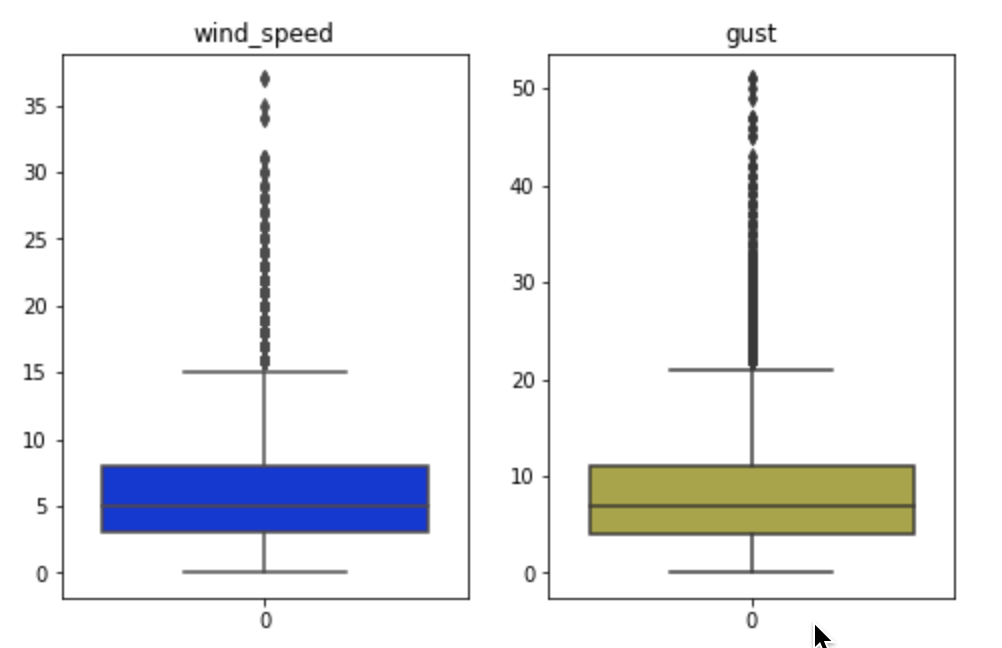
df5[col] = modified[col]또한, max 값이 평균치에서 너무 많이 떨어졌다고 판단되는 feature는 분포를 찍어보고 아웃라이어들을 완화시킬 필요가 있는 feature를 찾아보았다. 아래 두 지표가 그러했고 각각 4, 5%의 아웃라이어가 존재함을 알 수 있었다. 이후 머신러닝을 위한 데이터셋에서는 이 부분을 완화시켜줄 것이다.

두 가지 타입의 데이터셋 만들기
ML: Random Forest
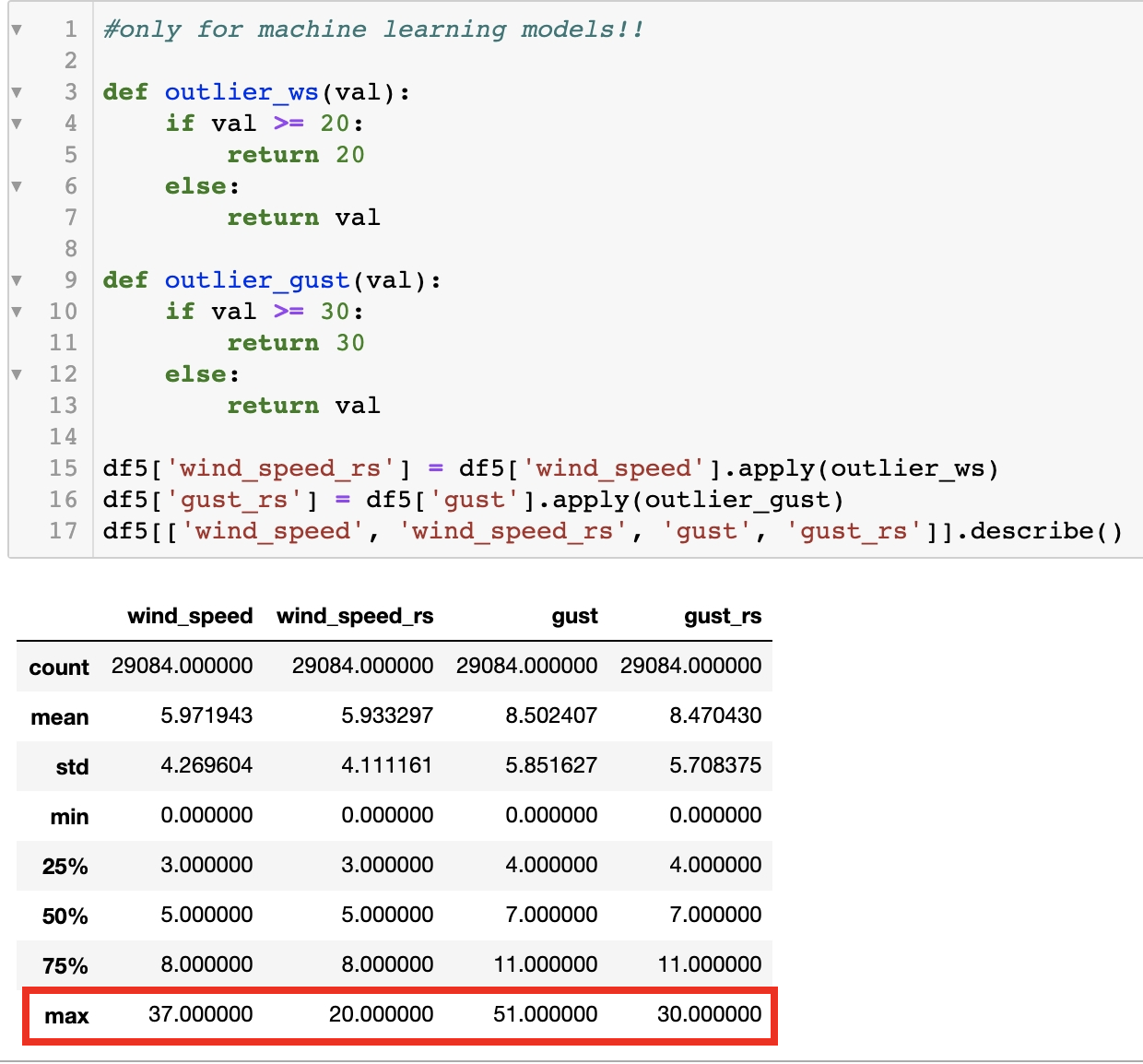
- 아웃라이어 제거: wind speed 20 이상, gust 30 이상 데이터를 20과 30으로 맞췄다.
- 데이터 비틀기: 랜덤포레스트 모델은 Sequential한 데이터를 다루지 않는다. 그래서 이런 장치를 사용해보았다.
timestep T의 PM2.5 예측 <- timestep T의 날씨 + timestep T-1의 대기질
우리가 세 시간 후의 미세먼지를 예측한다고 가정해보자. 그 때의 일기예보는 존재할 것이다. 그리고 T-1의 CO, NO2 등의 대기질도 예측에 활용할 수 있다. 다만, T-1의 PM2.5 농도는 예측에 활용하지 않을 것이다. 이게 들어가면 Sequential 데이터가 된다.
past = ['no2', 'co', 'so2', 'pm25_con']
cur = ['time', 'temp', 'wind_direction', 'cloud', 'precipitation', 'pressure', 'wind_speed_rs', 'gust_rs', 'overall_int', 'pm25_cat']
past_array = list()
for i in past:
past_array.append(df6[i][:-1].reset_index(drop=True))
cur_array = list()
for i in cur:
cur_array.append(df6[i][1:].reset_index(drop=True))DL: LSTM and Attention
딥러닝 모델로는 RNN 계열을 사용할 예정이다. Sequential한 성격을 갖는 데이터이기 때문이다. 앞서 언급한 대로 모든 feature들을 표준화했다. Neural Network는 특별히 큰 수치들을 더 중요한 것으로 인지할 수 있기 때문에 적절히 re-scaling 되어 있지 않은 데이터로는 학습이 잘 이뤄지지 않을 수 있다.
이제 모델에 들어갈 데이터들을 각각 다듬었으니 이후에는 모델을 만들고 training 후 평가하는 내용을 다룰 것이다.
모든 코드는 > github
