딥러닝의 종류
딥러닝은 크게 두가지 종류로 나뉜다.
- 컴퓨터 비전 (Computer Vison)
- 자연어 처리 (Natural Language Processing)
CV는 딥러닝을 통해 이미지를 분류, 생성하는 분야이고
NLP는 자연어, 즉 인간의 언어 (컴퓨터 언어가 아닌 언어)를 컴퓨터가 해석할수 있게 해주는 분야이다.
두 분야에서는 서로 다른 레이어가 쓰인다.
CV는 합성곱 신경망 (CNN)이 주로 쓰이고
NLP는 순환 신경망 (RNN)이 주로 쓰인다.
오늘은 자연어 처리와 Embedding Layer, RNN 을 다뤄볼 예정이다.
자연어 처리 (NLP)
희소 표현 (Sparse Representation)
상술했듯이, 자연어 처리는 컴퓨터로 하여금 인간의 언어를 해석할수 있게 만드는 과정이다.
탁자위에 사과, 바나나, 배가 있다고 가정해보자.
세가지의 과일을 어떻게 해야 컴퓨터에게 학습시킬수 있을까?
당연하듯 각 과일에 대해 수치적인 의미를 부여해야 컴퓨터는 과일을 인식할수있다.
사과 [0]
바나나 [1]
배 [2]
이제 컴퓨터는 0이면 사과, 1이면 바나나, 2면 배 라는것을 인식할수 있다.
하지만 바나나와 배중 어떤것이 사과와 비슷하게 생겼어? 라고 물어보면 컴퓨터는 알리가 없다.
이를 가능하게 하려면 2차원 이상의 벡터로 단어를 표현해줘야 한다.
전에는 단순히 임의의 순번 (0~2)를 부여해줬다면 이번엔 벡터를 이용하여 과일의 속성을 부여해준다.
[과일의 형태(0:동그람, 1:길쭉함), 과일의 색깔(0:빨강, 1:노랑)]
사과 [0,0]
바나나 [1,1]
배 [0,1]
이런식으로 단어에 속성을 부여해주면 컴퓨터에게 "사과와 생김새가 비슷한 과일이 뭐야?" 라고 물어봤을때 같은 형태값(0)을 가진 배를 선택할 것이다. 이와 같이 벡터의 특정 차원에 단어의 의미를 직접 매핑하는 방식을 희소 표현 (Sparse Representation)이라 한다.
하지만 자연어 처리는 위와 같이 단순하지가 않다. 인간의 언어는 여러 종류가 있고 한 언어에도 수십만개의 단어가 있다. 모든 단어를 일일이 매핑하기엔 단어의 벡터 범위가 몇차원까지 뻗어나갈지도 모르는 법이다.
분산 표현 (Distribution Representation)
위의 문제를 해결하기 위해 모든 단어를 256개의 고정 차원 벡터로 한정하기로 했다. 그리고 각 차원이 특정한 의미를 가지지 않는다 가정한다. 다만, "유사한 맥락에서 나오는 단어는 그 의미도 유사할 것이다!" 라는 가설만 세운다. 이것을 분포 가설 (Distribution Hypothesis) 이라고 한다.
예시 문장을 보자:
- 나는 밥을 먹는다.
- 나는 떡을 먹는다.
- 나는 []을 먹는다.
인간은 이 세문장만 봐도 '나는'과 '먹는다'라는 두 단어 사이엔 음식의 의미를 담고있는 단어가 들어가는구나! 라고 유추 할 수 있다.
하지만 컴퓨터는 그러지 못하기때문에 인간이 할 수 있는것은:
유사한 맥락이 나타난 단어들 사이의 벡터값을 가깝게 하고, 아닌 단어들의 벡터값은 멀게 조정해주는 것 뿐이다.
이러한 방식으로 얻어지는 단어 벡터를 단어의 분산 표현 (Distribution Representation) 이라 한다.
Embedding Layer
임베딩 레이어는 간단히 말해 컴퓨터가 쓰는 단어 사전이다.
우리가 "단어 n개를 쓸꺼야."라고 말해주면 컴퓨터는 알아서 사전을 만들고, 수많은 데이터를 거치며 각 단어의 의미 (분산표현)을 차근차근 업데이트 한다.
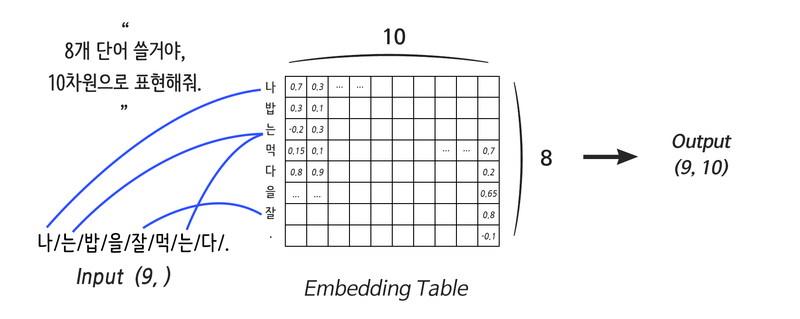
임베딩 레이어는 입력으로 들어온 단어를 분산 표현으로 연결해주는 역할을 하며, 그 동작이 weight에서 특정 행을 읽어오는것과 같아 룩업 테이블 (Look-up Table)이라고도 불린다.
순환 신경망 (Recurrent Neural Network)
문자, 음성, 영상과 같은 데이터는 이미지와 다르게 순차적인 (Sequential) 특징을 갖는다.
위에 예시로 들었던 문장을 보자:
- 나는 밥을 []는다
빈칸에 들어갈 문자는 당연히 '먹'일 것이다. 하지만 '먹'이라는 문자는 전에 있는 '밥'이라는 단어가 가지고있는 의미(벡터)에 의해 결정된다. 그 전에있는 '는'은 '나'라는 문자에 의해 결정된다.
영상도 같은 맥락으로, 연속적인 이미지의 결합체이기때문에 순차적인 특징을 갖으며 이러한 특징을 가진 데이터를 시퀀스 데이터라 부른다.
이러한 시퀀스 데이터를 처리하기 위해 고안된 것이 RNN이다.
RNN의 구조를 보기 쉽게 시각화한 페이지를 참조한다.
https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9
RNN은 모든 단어만큼의 weight를 만들지 않는다. (입력의 차원, 출력의 차원) 에 해당하는 단 하나의 weight를 순차적으로 업데이트 한다. 그렇다보니 단 한문장을 읽고 처리하는데 여러번의 연산이 필요해 다른 레이어보다 느리다는 단점이 있다.
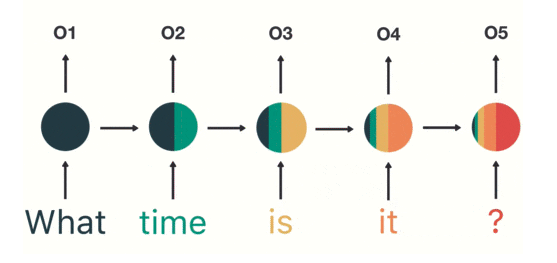
위에 보다싶이 what의 정보가 ?에 도착했을땐 대부분이 희석된 모습을 볼 수 있다. 이러한 현상을 기울기 소실 (Gradient Vanishin)이라 한다.
LSTM (Long Short Term Memory)
LSTM은 RNN의 기울기 소실 문제를 해결하기 위해 고안되었다.
LSTM에 대한 설명을 자세히 한 블로그가 있어서 링크를 첨부한다.
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
