Confidence Intervals
ANOVA (one way)
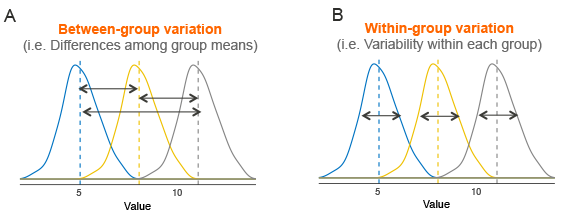
분산분석은 두 개 이상 집단들의 평균을 비교하는 통계분석 기법
즉, 분산분석은 두 개 이상 집단들의 평균 간 차이에 대한 통계적 유의성을 검증하는 방법
여러 그룹들이 하나의 분포에서부터 왔다 라는 가정이 나오는데,
이를 위한 지표는 F-statistic 입니다.
F값이 높다는건 어떤 의미 일까?
- 분자(다른 그룹끼리의 분산)는 크고, 분모 (전체 그룹의 분산)는 작아야 한다.
- 즉 다른 그룹끼리의 분포가 다를 것이다 라는 가정이 붙는 것이다.
import numpy as np
g1 = np.array([0, 31, 6, 26, 40])
g2 = np.array([24, 15, 12, 22, 5])
g3 = np.array([32, 52, 30, 18, 36])
from scipy.stats import f_oneway
f_oneway(g1, g2, g3) # pvalue = 0.11큰 수의 법칙 (Law of large numbers)
sample 데이터의 수가 커질 수록, sample의 통계치는 점점 모집단의 모수와 같아짐
중심극한정리 (Central Limit Theorem, CLT )
Sample 데이터의 수가 많아질 수록, sample의 평균은 정규분포에 근사한 형태로 나타남
Point estimate VS Interval estimate
example. 초등학교 5학년 1000명의 평균 키
점 추정 : 150cm일 것이다.
구간추정 :
145 ~ 155cm 정도 일 것이다.
140 ~ 160cm 정도 일 것이다.
1cm ~ 300cm 정도 일 것이다.
- 예측 하는 "구간"이 넓어질 수록 맞을 확률(신뢰도)은 올라간다.
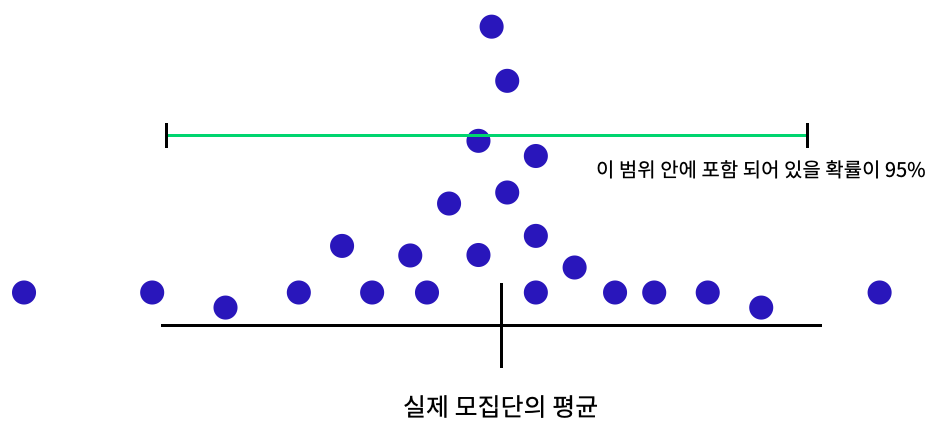
신뢰도
신뢰도가 95% 라는 의미는 표본을 100번 뽑았을때 95번은 신뢰구간 내에 모집단의 평균이 포함된다.

찐문과생의 빅데이터 생존기🐣 열심히 할래용 (ง •_•)ง