
이 포스팅은 2024.11.27에 작성되었습니다.
서론
(주절거리는 서론이니 스킵하셔도 됩니다)
가장 최근에 진행한 프로젝트에서 PostgreSQL을 사용하게 되었다.
나는 학부시절부터 주로 MySQL을 사용하였고, 지금까지 진행한 모든 프로젝트들도 가장 편하고 이해도가 높은 MySQL을 데이터베이스로 선택하여 사용해왔다. 이 덕분에 MySQL에 대한 이해도가 높아진 것도 있지만, 편하게 사용하다보니 시각이 좁아지는 게 느껴졌고, NoSQL이 필요한 상황이나 다른 데이터베이스가 가지는 특징을 활용해야하는 상황에도 MySQL을 고집하기도 하였다.
이를 극복하고자 NoSQL을 많이 활용해보면서 시각을 넓혀가고자 하였고, 이전에 진행한 프로젝트에서는 MongoDB를 내가 맡은 대부분의 기능에 활용해보았다. 하지만 대부분의 경우(특히 유저관련) 관계형 데이터베이스의 정규화가 필요하였기 때문에 어쩔 수 없이 MySQL을 사용할 수밖에 없었다.
그러다 새로운 관계형 데이터베이스인 PostgreSQL을 알게되었고, 팀원들과 협의하에 이번 프로젝트에 적용해보며 MySQL과 비교해보았다. PostgreSQL을 채택한 이유는 새로운 데이터베이스를 사용해보면서 시각을 넓히려는 목적도 있지만, 가장 편한 MySQL과 차이점을 위주로 공부해보면서 MySQL을 더 깊게 이해하고자 하는 목적도 있다.
이 글은 uber의 2016년 글을 정리한 글이다. 직접 읽어보는 것도 재미있으니 아래 글을 참고하면 좋을 것 같다!
https://www.uber.com/en-KR/blog/postgres-to-mysql-migration/
PostgreSQL이란?
간단하게 개념먼저 정리해보고자 한다. 공식 사이트에서는 PostgreSQL을 "The World's Most Advanced Open Source Relational Database"라고 표현해둔 걸 볼 수 있다.
 (귀여운 코끼리가 특징이다)
(귀여운 코끼리가 특징이다)
PostgreaSQL은 오픈소스이고 1996년에 첫 출시된 RDBMS이다. 북미와 일본에서 높은 인지도와 인기를 얻고 있으며, 2024년 11월 기준 세계에서 4번째로 가장 많이 사용하는 RDBMS가 되었다. (인스타그램도 PostgreSQL을 이용하여 개발되었다고 한다)
PostgreSQL의 장점
간단하게 인터넷에서 찾을 수 있는 PostgreSQL의 장점은 아래와 같다.
- ACID, 트랜잭션 지원
- MVCC
- 유연한 Full-text search 기능
- 다양한 프로시져(PL/pgSQL, Perl, Python, Ruby, TCL, 등)/인터페이스(JDBC, ODBC, C/C++, .Net, Perl, Python, 등) 언어
- MySQL에 비해 SQL 표준을 더 잘 지원하고, 기능이 더 강력하며, 쿼리가 복잡해질수록 성능이 더 잘나온다고 함
- PostGIS를 통한 위치기반 쿼리는 오라클 이상의 강력함을 자랑한다고 함
- 개발자들이 선호하며, 컨퍼런스나 세미나도 꾸준함
- 잘 만든 문서 및 충분한 메뉴얼
본론 - 우버의 사례
원문: https://www.uber.com/en-KR/blog/postgres-to-mysql-migration/
Uber의 초기 아키텍처는 PostgreSQL고 Python을 채택한 모놀리식 백엔드 어플리케이션이었다고 한다. 이후 마이크로서비스 모델로 확장하며 PostgreSQL에서 MySQL로 데이터베이스를 변경하였다고 한다.
Uber가 PostgreSQL의 한계로 꼽은 점은 다음과 같다.
- 쓰기에 비효율적인 아키텍처
- 비효율적인 데이터 복제
- 테이블 손상 문제
- 열악한 복제본 MVCC 지원
- 새로운 릴리스로의 업그레이드 어려움
글을 읽으면서, 이 문제들은 PostgreSQL의 저장방식과 연관이 깊다는 걸 알게되었고, 데이터베이스를 선택할 때 단순히 익숙하고 사용이 편한것을 고르는 게 아니라 서비스 특성을 충분히 고려해야한다는 걸 알게되었다.
PostgreSQL의 디스크상 형식
PostgreSQL은 ctid라고 부르는 immutable row data로 튜플의 디스크상의 위치를 표현한다.
테이블에 인덱스를 걸 경우, 인덱스 필드를 ctid 페이로드에 매핑하는 데이터구조(B-tree)로 구성한다.
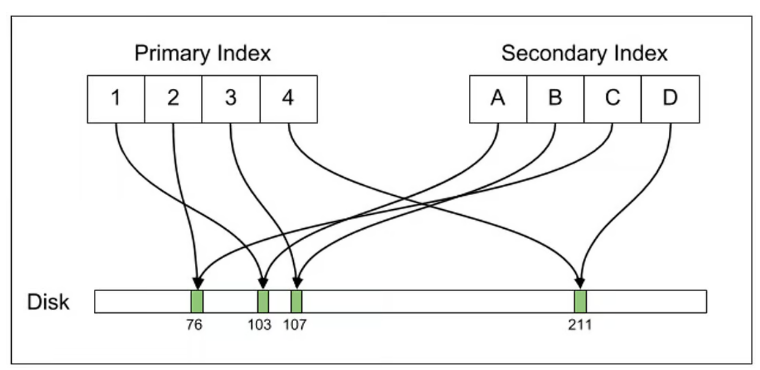
(세컨더리 인덱스도 실제 디스크 오프셋을 가리키고 있음)
튜플을 업데이트할 경우, MVCC를 위한 버전별 데이터 추가를 위해 새로운 튜플이 추가되고 이에 대한 새로운 ctid도 부여된다. 새로운 튜플이 추가되었기 때문에 관련 인덱스들도 모두 업데이트 해줘야한다.
PostgreSQL의 replication
PostgreSQL은 충돌 복구 목적으로 write-ahead log(WAL)을 유지관리하고, 이를 사용하여 two-phase commit을 구현한다. replica 서버와의 동기화를 위해 마스터 데이터베이스는 replica로 WAL을 전송하고, 이를 기반으로 데이터를 업데이트한다.
WAL의 내용은 행 튜플과 해당 디스크의 오프셋의 실제 디스크표현 수준이다.
PostgreSQL의 문제
문제1. Write Amplification
PostgreSQL의 설계로 인해 write Amplification이 발생할 수 있다.
튜플의 한 값을 update했을 때, 다음과 같은 프로세스로 update가 진행된다.
- tablespace에 새로운 row tuple 쓰기
- 새로운 tuple로 인한 primary key index 업데이트
- 추가적인 인덱스 업데이트
- WAL에 변경사항 반영
복제본이 많아질 수록 디스크의 총 쓰기 횟수는 많아진다. 작은 업데이트일 뿐인데 쓰기 횟수가 상당히 많은 걸 확인할 수 있다.
문제2. Replication
문제1에서 언급한 것처럼, WAL업데이트로 인해 복제 계층에도 모두 업데이트가 진행되어야한다. 단일 데이터 센터 내의 복제본이라면 크게 문제가 되지 않을 수 있지만, 데이터센터 간 복제가 이루어지는 경우 높은 대역폭 차지로 인한 비용이 많이 들 수 있다.
Uber의 경우, 서부 해안에서 동부 해안으로 데이터를 전송하여 복제서버를 관리하였는데, 초기 트래픽이 가장 많은 시기에 웹 서비스에 대한 대역폭이 WAL이 기록되는 속도를 따라잡을만큼 빠르지 않았다고 하였다.
문제3. Data Corruption
Uber는 데이터베이스 용량을 늘리기 위한 마스터 데이터베이스 프로모션 중에 버그를 발견하였다고 한다. 복제본이 타임라인 스위치를 잘못 따라가면서 일부 replica가 일부 WAL 레코드를 잘못 적용하였고, 레코드값이 잘못표시되는 문제가 발생하였다고 한다.
예를 들어, pk값으로 조회하는 select문이 있다고 하자.
SELECT * FROM users WHERE id = 4;해당 쿼리를 조회했을 때 pk값으로 조회하였기 때문에 값은 단 한 개가 나와야 정상이다. 하지만 새로운 업데이트를 적용한 튜플도 같이 조회되면서 2개 이상의 데이터가 조회되었다고 한다.
나도 JPA를 쓰면서 findById를 자주 사용하였는데, 단 하나의 값이 나오지 않으면 에러가 발생하면서 해당 서비스로직이 실패하는 문제를 자주 만났다. Uber도 이와 같은 문제를 만났고, 방어적인 프로그래밍문을 추가하면서 해결하려고 하였지만 잠재적으로 문제가 발생할 수 있다는 점은 굉장히 큰 문제였다.
또한 Uber는 여러 개의 replica 서버를 운영중이었고, 해당 에러가 어디에서 발생하는지 추적하기도 어려웠고 데이터베이스 인덱스가 완전히 손상될 수 있는 위험도 배제할 수는 없었다. 이를 해결하기 위해 실제로 발생한 버그를 추적하여 새로운 마스터 데이터베이스에 손상된 행이 없음을 확인하고, 새 스냅샷의 모든 복제본을 다시 동기화하였다고 하였다. (듣기만 해도 굉장히 쉽지 않은 과정이었을 것 같다)
해당 문제는 Postgres 9.2의 특정 버전에서 발생한 문제였지만, 언제 또 이런 문제가 발생할 지 알 수 없었기 때문에 신뢰할 수 없게 되었다고 한다.
문제4. Replica MVCC
Uber는 Postgres가 진정한 replica MVCC를 지원하지 않는다고 말하였다.
Postgres는 MVCC를 위해 오래된 row version을 유지해야한다. 만약 streaming replica가 트랜잭션이 open되어있을 때, 다른 트랜잭션에서 열어둔 row에 영향을 미치는 경우 데이터베이스 업데이트가 차단된다. 이 상황에서 Postgres는 트랜잭션이 종료될 때까지 WAL 어플리케이션 스레드를 일시 중지한다.
하지만 트랜잭션이 오래 걸리는 경우 복제서버는 master의 업데이트를 빠르게 적용할 수 없게 된다. 이를 해결하기 위해 Postgres는 시간초과를 적용하여 일정 시간 이상 WAL어플리케이션을 차단할 경우 해당 tx를 종료한다.
이런 상황을 모르는 개발자는(특히 JPA를 사용할 경우) 데이터베이스 tx 범위를 제대로 지정하지 않아 계속 트랜잭션이 종료되는 문제를 겪을 수 있다. 물론 트랜잭션 범위는 짧을 수록 좋지만, 서버 개발자가 이런 구조를 모를 경우 그냥 사용할 경우 원인모를 tx종료 에러를 겪을수도 있을 것이다.
문제5. Postgres Upgrades
복제 레코드의 경우 물리적 수준에서 작동하기 때문에, Postgres의 다른 general availability releases 간에 데이터 복제가 불가능하다. (Postgres 9.2 <-> Postgres 9.3 불가능)
그래서 Uber는 다를 release로의 업데이트를 다음과 같은 과정으로 진행하였다.
- 마스터 데이터베이스를 종료
- 마스터에서 pg_upgrade라는 명령을 실행하여 마스터 데이터를 제자리에서 업데이트함. 이 작업은 대규모 데이터베이스의 경우 몇 시간이 걸릴 수 있으며, 이 프로세스가 진행되는 동안 마스터에서 트래픽을 제공할 수 없음
- 마스터를 다시 시작
- 마스터의 새 스냅샷을 만듦. 이 단계는 마스터의 모든 데이터를 완전히 복사하므로 대규모 데이터베이스의 경우 몇 시간이 걸림
- 각 복제본을 지우고 마스터에서 복제본으로 새 스냅샷을 복원
- 각 복제본을 복제 계층으로 다시 가져옴. 복제본이 복원되는 동안 마스터에서 적용한 모든 업데이트를 복제본이 완전히 따라잡을 때까지 기다림
Uber는 9.1에서 9.2로의 업그레이드를 성공적으로 완료하였지만, 프로세스에 너무 많은 시간이 걸려서 이후 업데이트를 적용할 수 없었다고 한다. 그래서 9.5 release가 나온 시점에도 레거시 코드는 Postgres 9.2를 실행한다고 한다.
+) Postgres 9.4를 사용할 경우 Postgres에 대한 논리적 복제 계층을 구현하는 pglogical을 사용할 수 있지만, 이 기능은 Postgres 메인라인 트리에 통합되지 않았기 때문에 문제가 있다고 하였다.
MySQL의 구조
Postgres의 아키텍처와 MySQL의 아키텍처를 비교하여 MySQL 구조를 살펴보자.
(MySQL의 InnoDB를 중점으로 본다)
1. InnoDB On-Disk Representation
MySQL도 MVCC 및 가변 데이터 기능을 제공한다.
Postgres와의 가장 큰 차이점은, InnoDB의 인덱스는 디스크상 행 위치에 대한 포인터를 가지는 대신, Primary Key에 대한 포인터를 가지도록 한다. 즉, 세컨더리 인덱스에 대한 데이터 조회를 위해 다음과 같은 두 번의 실질적 조회를 수행한다.
(1) 세컨더리 인덱스 조회 -> PK찾기
(2) Primary key인덱스 조회 -> 디스크상 위치 조회
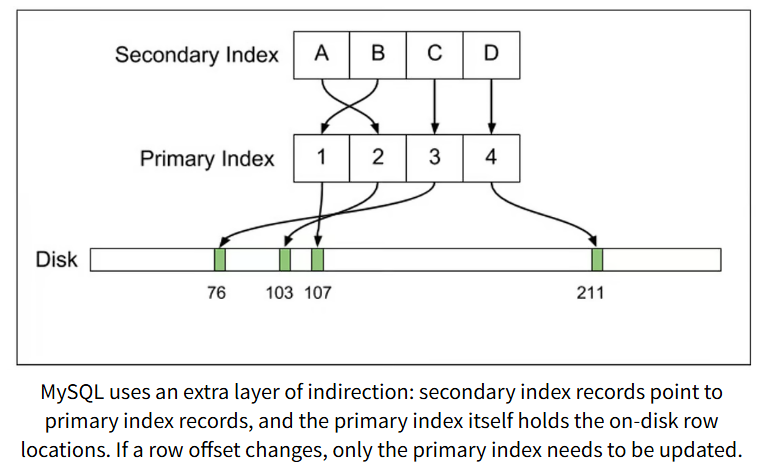
매번 두 번의 조회를 해야하기 때문에 Postgres보다 세컨더리 인덱스 조회 시 조금 불리한 점은 있다.
하지만 업데이트 시에는 단일 업데이트만 수행해도 된다는 장점이 있다. 이전 tx가 MVCC를 목적으로 행을 참조하는 경우 MySQL은 이전 행 데이터를 롤백 세그먼트라는 특수 영역에 복사한다. 기본 키 인덱스를 업데이트 할 필요도 없고, 세컨더리 인덱스도 업데이트할 필요가 없다.
해당 설계는 vacuuming과 compaction을 더 효율적으로 만든다, vacumming이 가능한 모든 행은 롤백 세그먼트에서 직접 사용할 수 있는 반면, Postgres의 auto vacumming 프로세스는 삭제된 행을 식별하기 위해 전체 테이블 스캔을 수행한다.
2. Replication
✅ 복제스트림 비교
MySQL은 Primary key 인덱스만 행의 디스크 오프셋에 대한 포인터를 갖는다. 이는 복제와 관련한 중요한 결과를 가져온다. 결론부터 말하면 MySQL 복제 바이너리 로그가 PostgreSQL WAL 스트림보다 훨씬 컴팩트하다.
MySQL 복제 스트림은 행에 대한 논리적 업데이트에 대한 정보만 포함하면 된다. 복제본은 이러한 명령문의 결과로 변경해야 하는 모든 인덱스 변경사항을 자동으로 유추한다.
반면 Postgres 복제 스트림에는 디스크 오프셋에 대한 물리적 변경사항이 포함되고, 해당 물리적 변경 사항은 WAL 스트림에 포함된다. 새 튜플을 삽입하고, 모든 인덱스가 해당 튜플을 가리키도록 업데이트하는 변경사항이 모드 WAL 스트림에 포함되고, 많은 디스크상 변경이 발생한다.
✅ 진정한 MVCC를 구현할 수 있는 MySQL
해당 복제 스트림 작동 방식은 MVCC가 복제본과 작동하는 방식에도 중요한 영향을 미친다. MySQL 복제 스트림에는 논리적 업데이트가 있으므로, 복제본은 진정한 MVCC의 의미를 가진다. (복제본에 대한 읽기 쿼리가 복제 스트림을 차단하지 않음)
하지만 Postgres WAL 스트림에는 물리적 디스크 변경사항이 포함되어, 읽기 쿼리와 충돌하는 복제 업데이트를 수행할 수 없고, 진정한 MVCC를 구현할 수 없게된다.
✅ 버그로 인해 인덱스가 손상되지 않는 MySQL
MySQL의 복제는 논리적 계층에서 발생하므로, B-tree를 재조정하는 작업으로 인해 인덱스가 손상되지 않는다. 물론, 명령문을 건너뛰는 경우나 두 번 적용되는 경우의 경우 데이터가 누락되거나 유효하지 않을 수 있지만, 데이터베이스 자체가 중단되는 문제는 발생하지 않느다.
✅ 서로 다른 MySQL 릴리스간 복제가 쉬움
MySQL의 복제 아키텍처는 서로 다른 MySQL 릴리스 간 복제가 용이하게 만든다.
MySQL은 복제 형식이 변경될 때만 버전을 증가시키는데, 이는 다른 DBMS에서는 볼 수 없는 특징이다. 논리적 복제를 실제 데이터 변경 내용을 SQL 문장형태로 전달하기 때문에, MySQL의 논리적 복제 형식은 스토리지 엔진 계층의 디스크상 변경 사항이 복제 형식에 영향을 미치지 않는다.
MySQL 업그레이드를 수행하는 일반적인 방법은 한 번에 하나의 복제본에 업데이트를 적용 후, 모든 복제본을 업데이트하여 그 중 하나를 새 마스터로 승격하는 것이다. 이는 다운타임이 거의 없이 수행가능하고, MySQL을 최신 상태로 유지하기도 굉장히 좋다.
그 외에도 MySQL은 버퍼풀 캐싱, 연결 당 스레드를 생성하는 방식으로 오버헤드를 줄이는 등 PostgreSQL과 비교되는 설계적 이점이 존재한다.
마치며
우버의 글은 2016년에 작성되었고, PostgreSQL은 현재까지도 꾸준히 릴리스되고 있기 때문에(최신 릴리스 11/21) 해당 문제를 어느정도 극복했을 가능성이 있었다. 하지만 아직 postgreSQL의 구조를 완벽히 이해하지 못하여 최신 업데이트 사항을 분석해볼 수는 없어서 조금 아쉬웠다.
그래도 글을 읽으면서 데이터베이스를 사용할 때 서비스의 특성을 충분히 고려하여 선택해야한다는 걸 깊게 깨달을 수 있어서 좋았다. 나도 확실히 데이터베이스를 이해하고 사용하는 개발자가 되고싶다.
참고자료
https://namu.wiki/w/PostgreSQL
https://www.uber.com/en-KR/blog/postgres-to-mysql-migration/
https://d2.naver.com/helloworld/227936

좋은 글 잘 봤습니다!!
최신 PostgreSQL은 이러한 점이 고쳐졌을지 궁금하네요!!