
★ Pandas는?
Pandas: pandas는 데이터 조작 및 분석을 위한 파이썬 프로그래밍 언어 용으로 작성된 소프트웨어 라이브러리이다. 숫자 테이블과 시계열을 조작하기 위한 데이터 구조와 연산을 제공하며, 무료 소프트웨어 New BSD 라이센스이다.
★ Numpy는?
Numpy: NumPy("넘파이"라 읽는다)는 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리할 수 있도록 지원하는 파이썬의 라이브러리이다. NumPy는 데이터 구조 외에도 수치 계산을 위해 효율적으로 구현된 기능을 제공한다.
★ Series는?
Pandas의 데이터형을 구성하는 기본 구조자료이다. pandas series는 인덱싱된 데이터의 1차원 배열이다. numpy의 경우, 인덱스 없이 묵시적으로 '0'부터 차례로 정수형 인덱스를 사용하여 접근하지만 pandas series는 명시적으로 정의된 인덱스가 존재하기 때문에 명시적 인덱스를 사용할 수 있다는 차이가 있다.
★ DataFrame은?
데이터를 행과 열로 구성된 2차원 표(스프레드시트와 비슷)로 정리하는 데이터 구조자료이다. DataFrame은 최신 데이터 분석에서 가장 보편적으로 쓰이는 데이터 구조 중 하나로 유연하고 직관적인 방식으로 데이터를 저장하고 작업이 가능하다.
오늘은 pandas를 다루기 위해 알아야하는 기초적인 기능들에 대해서 알아보고 정리하고자 한다.
0. Series
- Series는 index와 value로 이루어져 있다.
- Series는 한가지 data type만 가질 수 있다.
pandas를 사용하기 위해서는 가장 먼저 pandas와 numpy를 import해주어야 한다.

(1) 정수형 데이터 출력
pd.Series([1, 2, 3, 4])Series에 리스트로 이루어진 정수 데이터를 입력해보면 아래와 같이 index와 value 값으로 표현되는 것을 볼 수 있다. 또 data type(dtype)까지 출력된다.
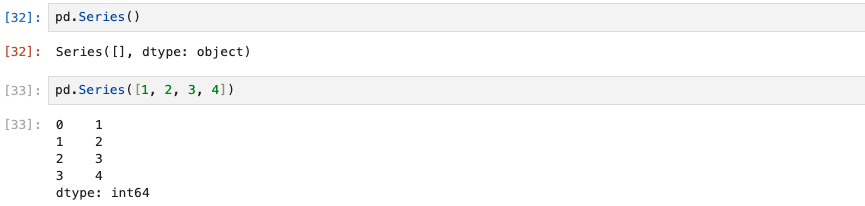 또 다른 예시들도 보겠다.
또 다른 예시들도 보겠다.
(2) 짝수
짝수를 찾고 싶다면 %2로 표현해 볼 수 있다.
data를 [1, 2, 3, 4]일 경우, data % 2를 하면 짝수는 1, 홀수는 0으로 출력된다.
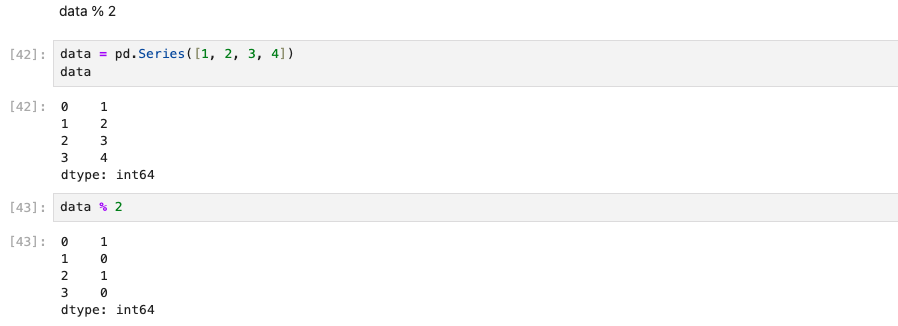
(3) 날짜/시간
변수로 dates를 기입하고 date_range를 이용하면 날짜도 이용할 수 있다.

(4) Series에서 사용하는 매서드
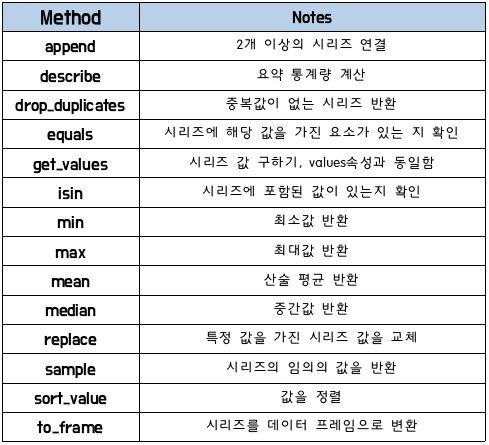
1. DataFrame(df)

- 2차원 자료구조이다.
- pandas에서 가장 많이 사용되는 데이터형이다.
- index와 values, columns를 지정하면 된다.
- 행레이블/열레이블, 데이터로 구성 된다.
- 딕셔너리(dictionary)에서 데이터프레임 생성한다.
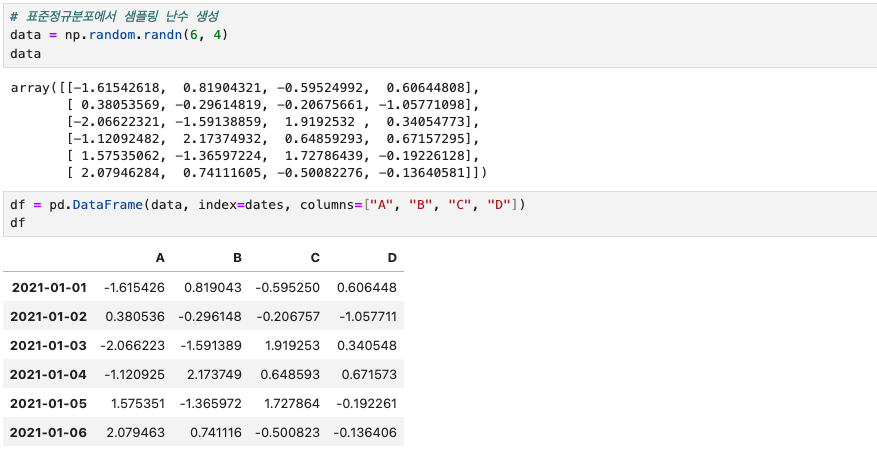
data = np.random.randn(6, 4)
dataDataFrame을 이해하기 위해 data라는 변수를 두고 샘플링 난수를 생성해 보았다.
randn(6, 4) 는 행이 6, 열이 4임을 뜻한다.
df = pd.DataFrame(data, index=dates, colums=["A", "B", "C", "D"])
dfDataFrame은 index, values, columns를 지정해주어야 하므로 위와 같이
- values = data(6행*4열로 이루어진 난수 data)
- index = dates(날짜)
- columns = "A", "B", "C", "D"로 지정해보았다.
그 결과는 아래와 같다.
(1) 데이터 확인
df.head()데이터 정보를 확인할때 내용이 긴 경우, df.head()를 이용하면 앞 부분 5개의 데이터를 확인 할 수 있다.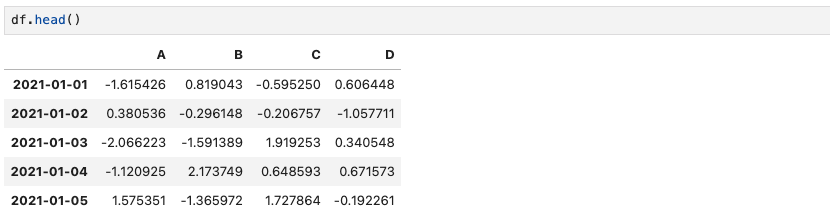
(2) 인덱스(index) 확인
df.indexDataFrame의 index를 확인할 수 있다.

(3) columns 확인
df.columnsDataFrame의 column을 확인 할 수 있다.

(4) value 확인
df.valuesDataFrame의 value를 확인 할 수 있다.

(5) 기본정보 확인
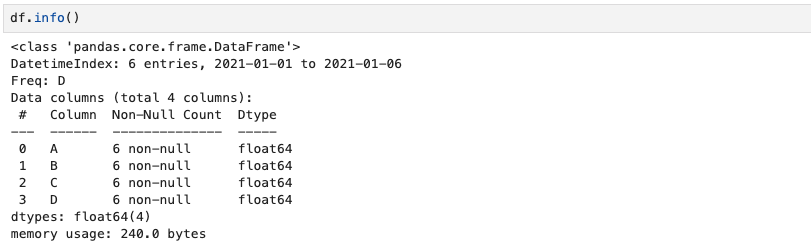
df.info()DataFrame의 기본정보를 확인할 수 있으며, 각 컬럼의 크기와 데이터 형태를 확인하는 경우가 많다.
(6) 통계정보 확인
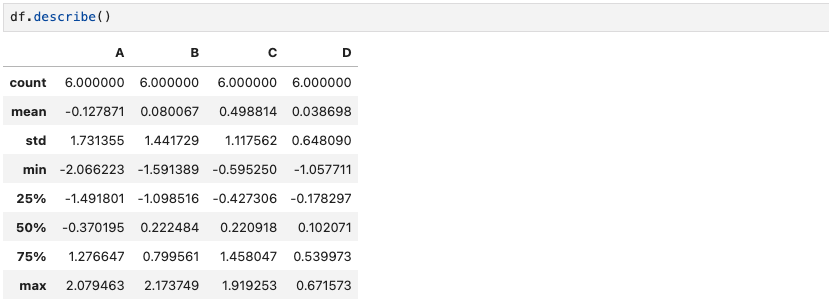
df.describe()DataFrame의 기술 통계에 대한 기본정보를 확인할 수 있다.
(7) 데이터 정렬(Sort)
df.sort_values(by="B", ascending=False)df로 정의된 DataFrame을 정렬하는 것으로, column "B"를 내림차순으로 정렬해보았다.
출력하면 다음과 같다.
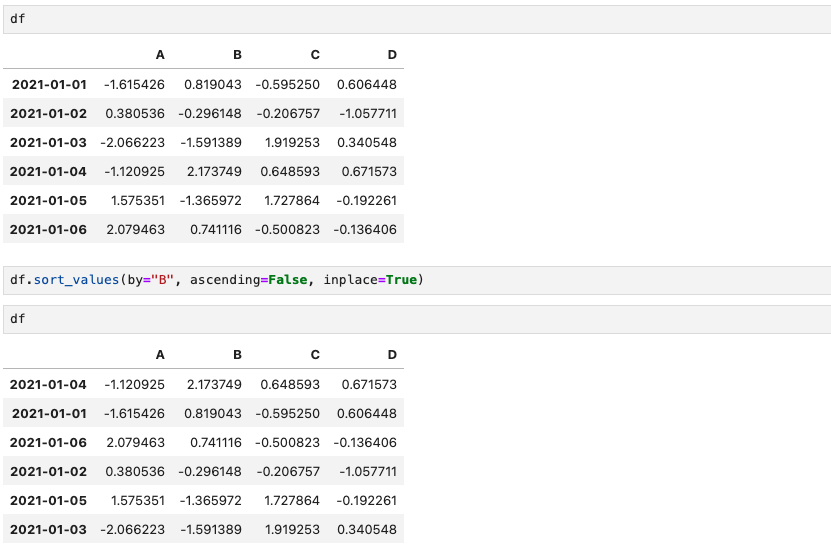
B column을 제외한 나머지는 정렬되지 않았다.
(8) 특정 column 읽기
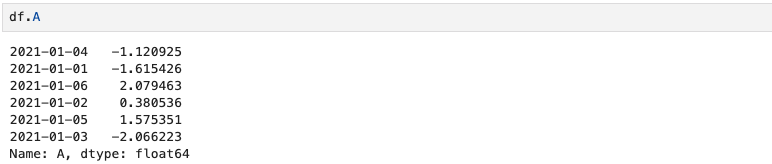
df["A"]이렇게 하면 A column만 읽을 수 있다.

df.A이렇게도 입력 가능하다. 만약 두 개의 columns을 선택하고 싶다면 df[["A", "B"]] 라고 입력해보자.
(9) Offset index
[n:m] : n 부터 m-1까지, index나 column의 이름으로 slice하는 경우는 끝을 포함한다.
df[0:3]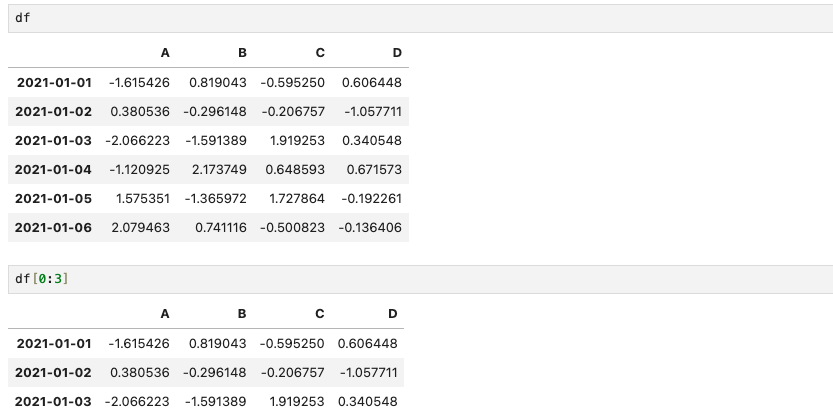
df[0:3]은 0부터 1까지의 DataFrame을 출력함을 의미한다.
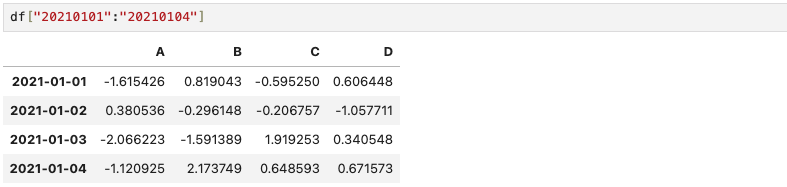
아래의 경우는, df["20210101":"20210104"]로 DataFrame의 지정된 index를 직접 입력하여 slice를 한 경우이므로 끝을 포함하기 때문에 20210101부터 20210104까지 나타낸다.
(10) Pandas Slice - option LOC
LOC는 pandas의 보편적인 slice 옵션으로, loc:location을 뜻하며 index와 column name으로 특정 행, 열을 선택한다.
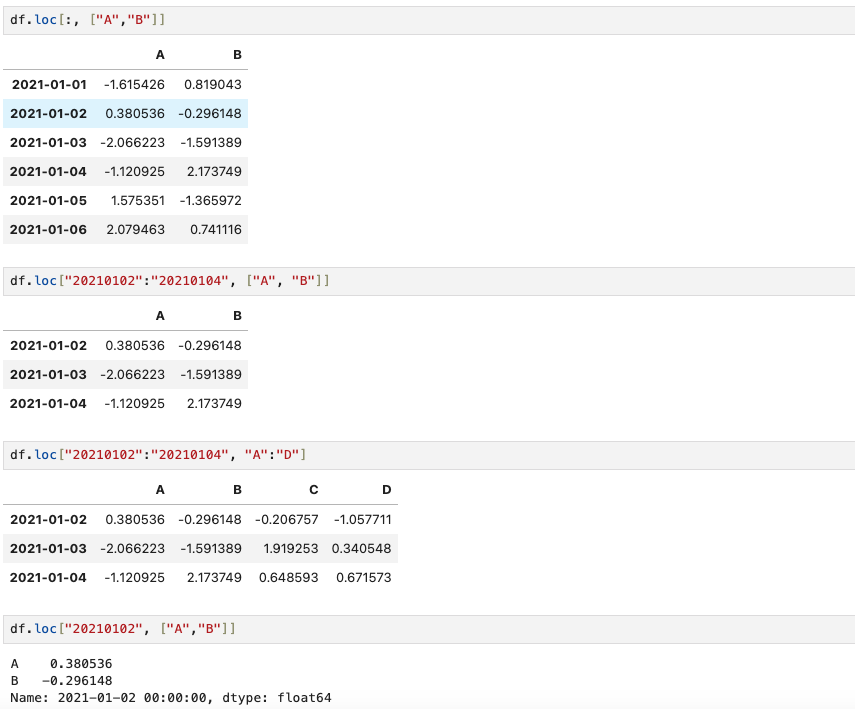
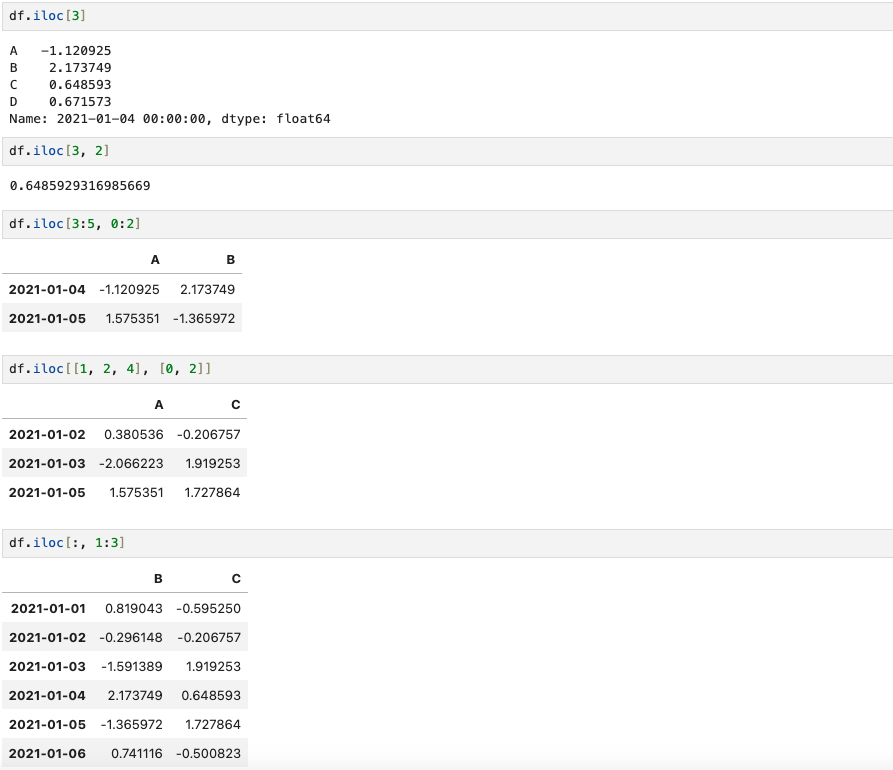
(11) Pandas Slice - option iLOC
iloc는 inter location의 약어로 컴퓨터가 인식하는 index값(번호)으로 특정 행, 열을 선택한다.
예를 들어 df.iloc[3:5, 0:2]의 경우, index 3부터 4까지(행), index 0부터 2까지(열)의 value를 출력한다.
(12) Pandas Slice under condition
DataFrame이 아래와 같을 때,
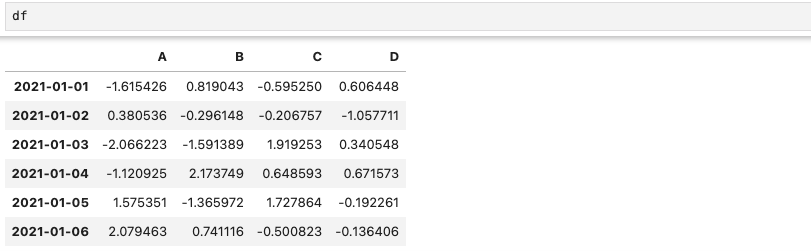
조건에 따라 DataFrame을 재설정할 수 있다.
df["A"] > 0 # A컬럼에서 0보다 큰 숫자에 대한 True/False
df[df["A"] > 0] # A컬럼에서 0보다 큰 숫자만 선택 출력
df[df > 0] # df전체에서 0보다 큰 숫자만 선택 출력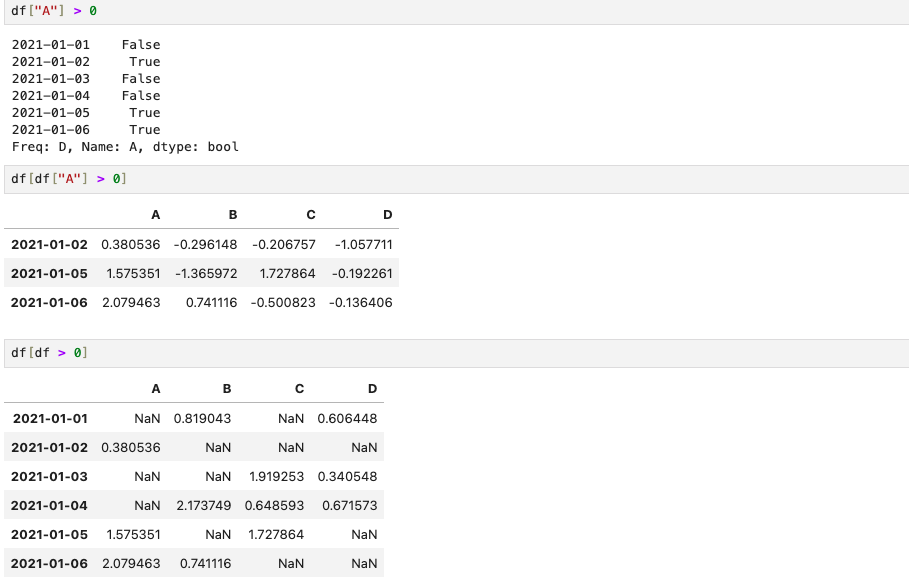
NaN 은 'Not a Number'를 뜻한다. 즉 condition에 맞지 않는 value는 NaN으로 출력된다.
(13) column 추가
기존 컬럼이 없으면 추가되고, 기존 컬럼이 있으면 수정된다.
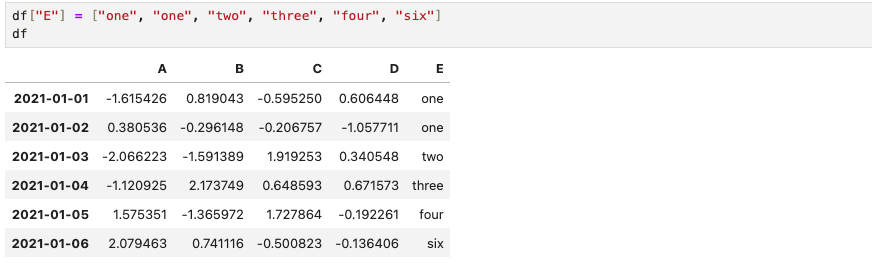
(14) isin()
특정 요소가 있는지 확인할 수 있다.
df["E"].isin([two])
df["E"].isin(["two", "five", "three"])
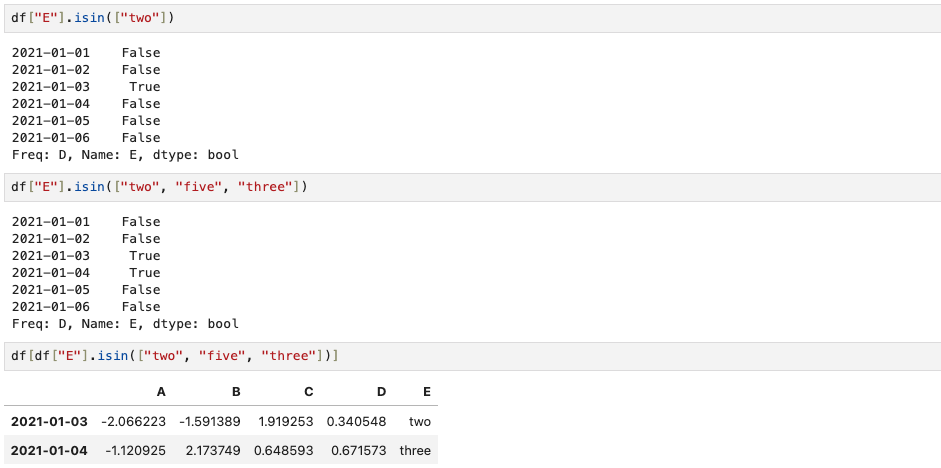
df[df["E"].isin(["two", "five", "three"])]E column에 two라는 요소가 있는지, 또는 여러개 "two", "five", "three"요소가 있는지 True and False로 출력된다. df[df["E"]].isin(["two", "five", "three"])]는 해당 요소들이 포함된 특정 행만 선택하여 DataFrame을 출력하라는 의미이다.
(15) 특정 column 제거
DataFrame이 아래와 같을 때,
 del() 또는 drop()으로 column제거가 가능하다.
del() 또는 drop()으로 column제거가 가능하다.
del df["E"] # E column제거
df.drop(["D"], axis=1) # D column 세로 축(열) 제거
df.drop(["20210104"]) # 20210104행 제거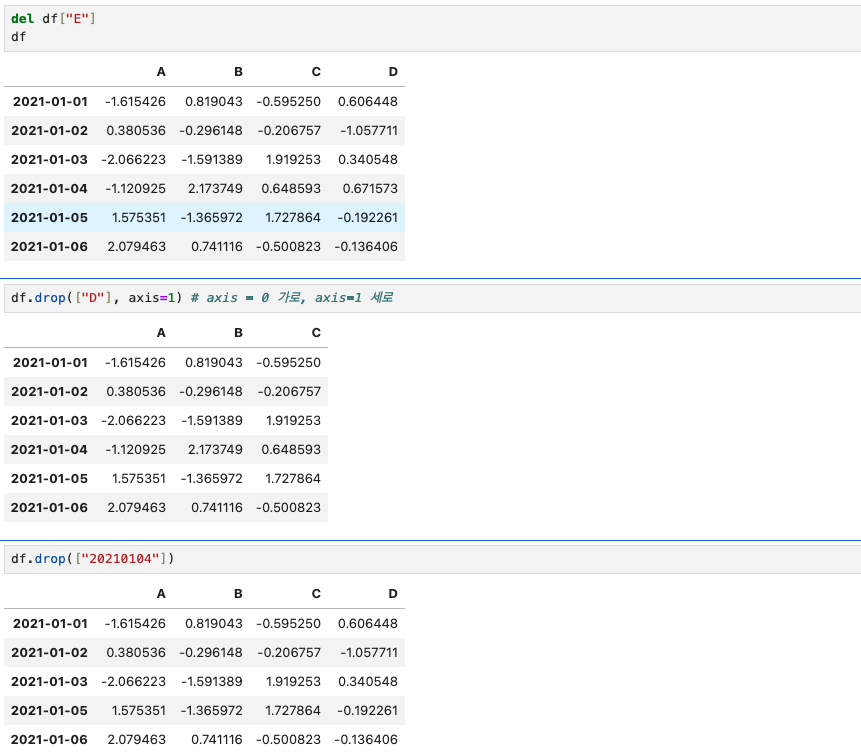
(16) apply()
DataFrame이 아래와 같을 때,
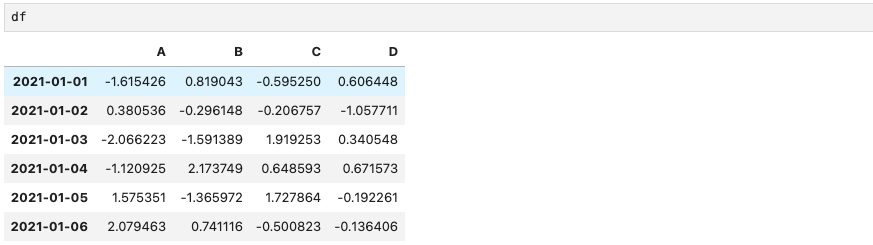 apply()는 각 column의 누적합을 출력한다.
apply()는 각 column의 누적합을 출력한다.
df["A"].apply("sum") # A column 전체 합계
df["A"].apply("mean") # A column 평균
df["A"].apply("min"), df["A"].apply("max") # A column의 최소값, 최대값
df[["A", "D"]].apply("sum") # 여러 column의 합계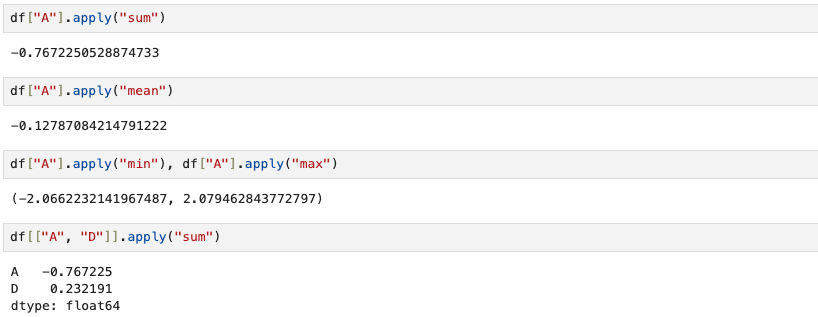
numpy에서 사용하는 덧셈 기능도 이용할 수 있다.
df["A"].apply(np.sum) # A column 전체 합계
df["A"].apply(np.mean) # A column 평균
df["A"].apply(np.std) # A column의 표준편차
df.apply(np.sum) # 전체 여러 column의 합계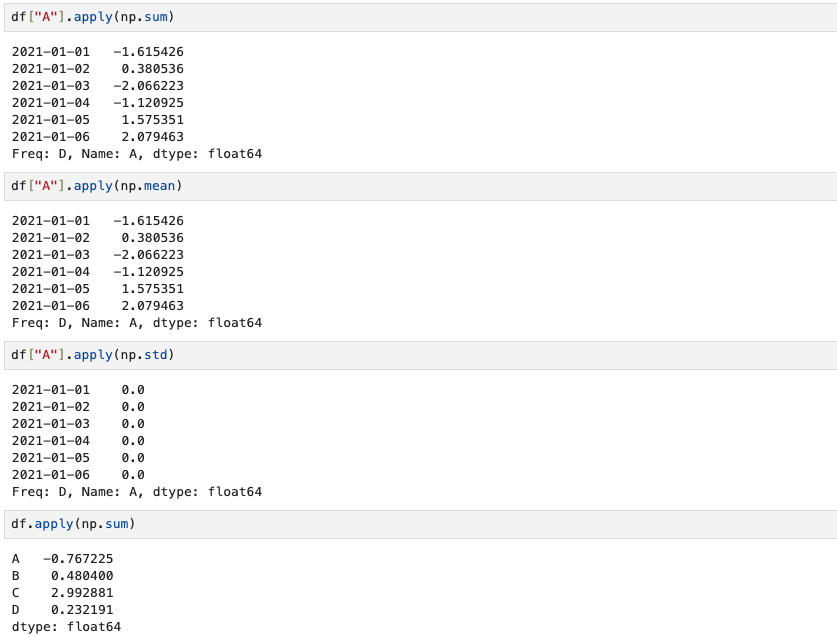
나아가 더 알아보면,
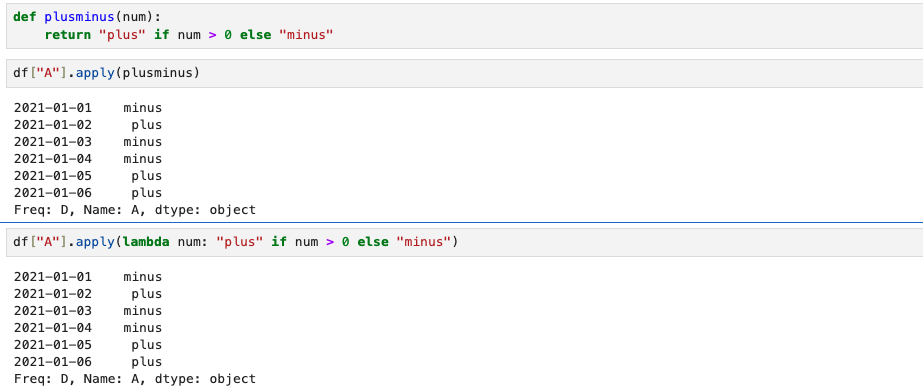
만약 내가 if ~ else 구문을 이용해 0보다 크면 plus, 0보다 작으면 minus라고 반환하는 함수를 만들었다고 했을 때,
def plusminus(num):
return "plus" if num > 0 else "minus"
df["A"].apply(plusminus)
df["A"].apply(lambda num: "plus" if num > 0 else "minus")내가 만든 함수를 적용해보면 plus, minus로 반환된 것을 알 수 있다.
(17) merge
Pandas DataFrame 데이터를 병합해보자. pandas에서 데이터를 병합하는 방법에는 세 가지 method가 있다.
pd.concat(), pd.merge(), pd.join() 이다.
1) dataFrame 1
- 딕셔너리 안의 리스트 형태
- 열 값 기준으로 데이터가 들어간다.
- left라는 변수에 해당하는 DataFrame
- "key", "A", "B"라는 각 column에 data값을 입력해주었다.
left = pd.DataFrame({
"key": ["KO", "K4", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]
})
left
2) dataFrame 2
- 리스트 안의 딕셔너리 형태
- 행 값으로 데이터가 들어간다.
- right 변수에 해당하는 DataFrame
- "key", "A", "B"라는 각 column에 data값을 입력해주었다.
right = pd.DataFrame([
{"key":"KO", "C":"C0", "D":"D0"},
{"key":"K1", "C":"C1", "D":"D1"},
{"key":"K2", "C":"C2", "D":"D2"},
{"key":"K3", "C":"C3", "D":"D3"},
])
right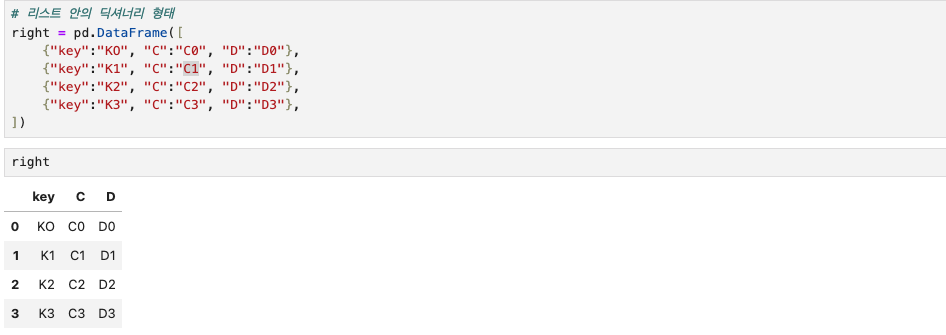
이렇게 실행해보면, 두 개의 DataFrame이 생성되었다.
3) dataFrame 1 과 dataFrame 2 합치기
- 두 DataFrame에서 cloumn이나 index를 기준으로 잡고 병합하는 방법이다.
- 기준이 되는 column이나 index를 key값이라고 한다.
- 기준이 되는 key값은 두 DataFrame에 모두 포함되어 있어야 한다.
pd.merge(left, right, on="key")on="key"는 양쪽 DataFrame 중에서 "key"라는 column 기준 key값으로 잡고 병합하겠다는 의미이다.
아래 결과를 보면 공통된 부분만 데이터 프레임으로 만들어진 것을 볼 수 있다.

4) 교집합으로 합치기
'inner'는 교집합이란 뜻으로, 두 DataFrame에서 공통된 부분만 뽑아주는 것이다.
pd.merge(left, right, how="inner", on="key")
5) 합집합으로 합치기
반대의 개념으로 'outer'는 합집합이란 뜻으로, 두 DataFrame의 모든 key값을 출력해준다.
pd.merge(left, right, how="outer", on="key")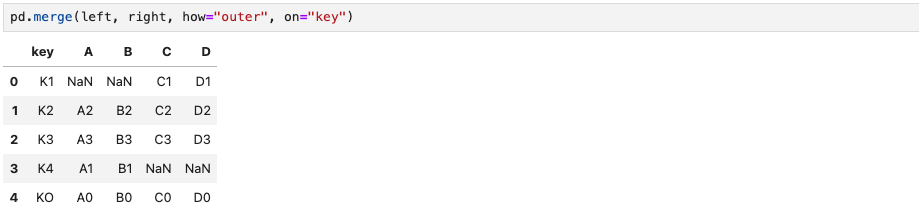
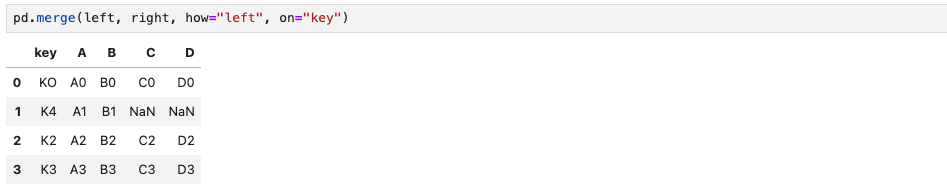
6) how를 사용하면?
pd.merge(left, right, how="left", on="key")how="left"는 left DataFrame과 right DataFrame을 "key"라는 column을 기준으로 데이터를 합치는데, left DataFrame에 있는 "key" column을 기준으로 합치라는 의미이다.
따라서 left DataFrame의 "key" column을 기준으로 합쳤을때, right DataFrame에 없는 값은 NaN으로 표기되었음을 알 수 있다.
이번에는 반대로 how="right"는 left DataFrame과 right DataFrame을 "key"라는 column을 기준으로 데이터를 합치는데, right DataFrame에 있는 "key" column을 기준으로 합치라는 의미이다.
따라서 right DataFrame의 "key" column을 기준으로 합쳤을때, left DataFrame에 없는 값은 NaN으로 표기되었음을 알 수 있다.
pd.merge(left, right, how="right", on="key")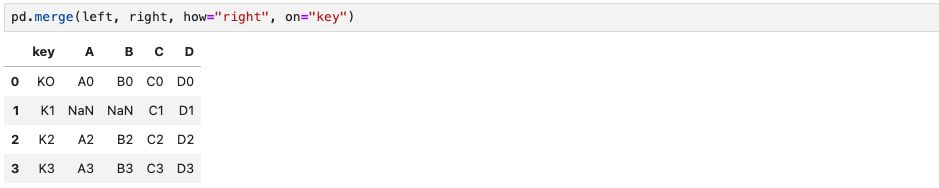
두 DataFrame을 합쳐줬을때 NaN값이 나온다면, 그 값을 어떻게 채워줄지 고민을 해봐야한다.
(18) Indexing options with DataFrame
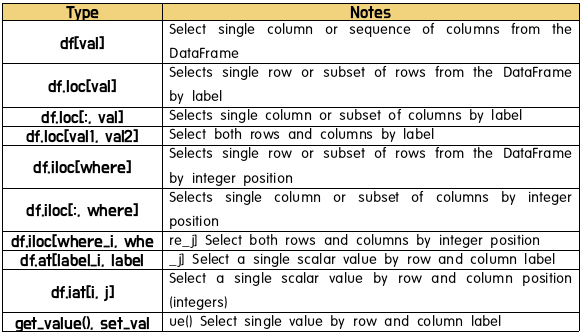
(19) Pandas 통계처리
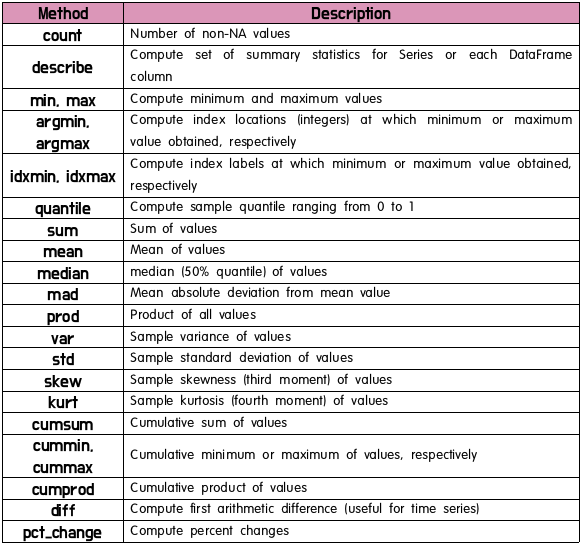
(20) Read & write data in Pandas
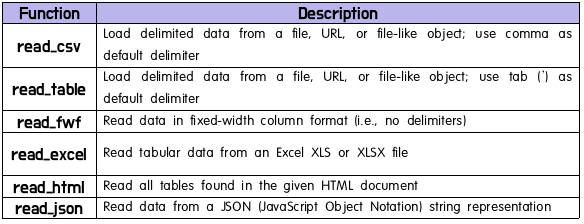
앞으로 프로젝트를 실행하기에 앞서 Pandas의 기초적인 내용들을 정리해보았다.
pandas를 통해 발전된 프로젝트를 실행할 수 있다면 너무 좋을 것 같다.
