CenterNet은 Anchor free로 유명한 모델이다. Yolov8의 Anchor Free 구조도 CenterNet의 아이디어를 참고하여 만들어졌고 Cost도 줄이며 Performace는 유지하거나 상승시킨 Architecture이기 때문에, 이 참에 리뷰를 해보려고 한다.
CenterNet Paper : https://arxiv.org/pdf/1904.07850
Abstract
기존의 object detection task는 object의 localization을 포함하는 많은 후보군을 나열하고 이를 분류한다.(NMS 과정) 이 과정은 비효율적이며 추가적인 후처리가 필요하게 된다. 따라서 저자들은 box의 중심점을 기준으로 모델링을 했다. 중심점 기반 접근 방식인 CenterNet은 차별화 가능하고, 단순하며, 더 빠르며 Anchor 구조인 object detection보다 더 정확했다.
--> Anchor Box를 사용한 object detection의 후처리란?
1. Non-Maximum Suppression(NMS)
- Anchor box 방식은 이미지 내에서 동일한 object에 대해 여러 box를 predict할 수 있다.
- 겹치는 box들 중에서 가장 높은 confidence를 가진 box를 남기고 나머지를 제거하는 NMS가 필요.
- cost가 발생하지만 탐지를 위해 필수적.
- IoU를 통해 Threshold를 넘지 못하는 박스를 필터링 해야함.
- 정규화된 좌표 변환
- Anchor Box는 모델이 predict한 상대적인 offset을 기준으로 bbox를 조정함.
- 최종적인 bbox를 얻으려면 predict 값을 Anchor Box의 크기와 위치를 기반으로 변환 및 보정이 필요함.(cost 증가)
==> 후처리로 인해 탐지 속도가 저하되고 NMS 설정으로 small object나 겹쳐진 object에 대해선 performance가 떨어질 수 있음.
==> CenterNet은 Anchor Box를 사용하지 않는 Anchor-Free 방식을 사용하여 NMS와 같은 후처리가 필요하지 않음. 따라서 cost가 줄어들어 real-time에 적합하고 효율적.
1. Introduction
Object Detection은 instance 분할, pose estimation, tracking, action recognition과 같은 많은 vision task에 동력을 제공한다. 지금의 object detection detector는 bbox로 object를 나타내고 anchor box를 regression을 통해 classification을 하는 것이 일반적이다.
One-stage detector
one-stage detector는 Anchor를 이용해 object를 탐지하고 객체성과 클래스 예측을 동시에 처리한다. 이 때문에 end-to-end 방식이라고 하는데, 하나의 Anchor box가 객체성(객체가 존재하는지)와 해당 객체의 class를 예측하는 것인데, 이는 two-stage detector랑은 다른 방식으로 돌아간다.
Two-stage detector
two-stage detector는 Region Proposal Network를 통해 이미지 안에서의 객체성을 찾는다. 이미지에서 객체가 존재하는 위치의 bbox의 coordinate를 반환하고 반대쪽 모델에서 feature를 분류한다. 두 가지의 모델을 학습해야 하다보니 end-to-end 방식이라 불리지 않는다.
저자들은 본 논문을 통해서 이들보다 더 단순하고 효율적인 대안을 제시했다. object를 bbox의 중심점으로 표현하였는데, 이는 아래의 그림을 참조하자.
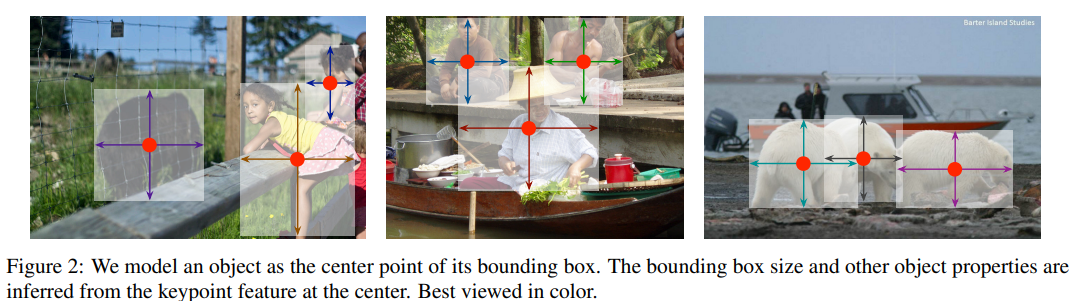
물체의 크기, 차원, 3D 범위, 방향, 자세와 같은 속성들은 중심점 위치의 image feature로부터 regression을 통해 예측된다. 따라서 Object detection은 표준 키포인트 추정 문제로 변환된다. input image를 fully convolutional network에 전달하여 heatmap을 생성한다. 해당 heatmap의 peak는 물체의 중심점에 해당한다. heatmap의 각 peak에서 얻은 image feature는 bbox의 높이와 너비를 예측한다. 모델은 dense supervised learning으로 학습되며 Anchor가 없으므로 NMS는 필요하지 않다.
2. Related work
Object detection by region classification
2 stage detector중 가장 성공적인 detector 중 하나인 RCNN은 많은 Region 후보군에서 object의 위치를 열거하고 이미지를 잘라낸 후 각 이미지의 region을 input으로 사용하여 학습을 하였다.
그러나 Fast-RCNN은 RCNN과는 다르게 input에 feature map을 집어넣어 계산량을 줄였는데, 그래도 매우 느릴 수 밖에 없다. 모두 Region Proposal Network를 사용했기 때문이다.
Object detection with implicit anchors
Faster RCNN에서 detector network에서 Anchor box를 사용하게 되었다. input image grid 위치에 대해 다양한 크기와 비율의 Anchor box를 생성하여 총 9개의 Anchor box를 사용하였다. IoU를 통해 나온 output 값을 이용해 foreground, background로 나눈다. 이렇게 생성된 region은 다시 regression을 통해 분류된다.
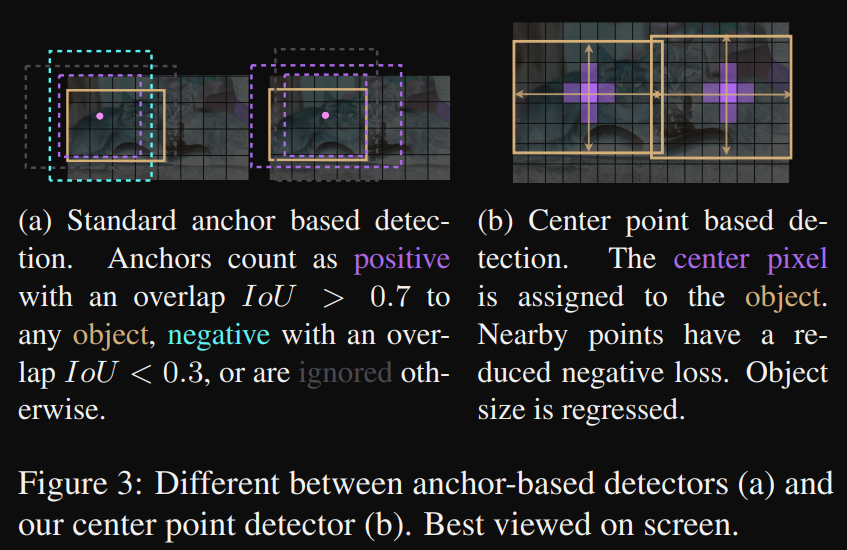
(a) : 표준 Anchor Based detection이다. IoU가 0.7이상이면 Positive, 0.3이하면 negative로 무시된다.
(b) : 중심점이 based인 detection이다. 중심 픽셀은 객체에 할당되어진다. 중심 주변의 픽셀들은 감소된 negative loss를 가지게 되며 물체의 크기는 regression을 통해 계산된다.
CenterNet의 차별점
저자들은 1-stage detection 접근 방식과 밀접하게 관련되어 있다고 언급함. 중심점은 단일 형태에 구애받지 않는 anchor로 간주될 수 있다. (Anchor free 구조라고 하는데, 저자는 단일 형태의 Anchor를 사용했다고 언급함.)
-
CenterNet은 IOU가 아닌 위치를 기준으로 anchor를 지정한다. 따라서 foreground, background 분류에 대해 수동 threshold가 필요하지 않다.
-
객체당 하나의 positive anchor만 있다보니 NMS가 필요하지 않다. keypoint heatmap에서 local peak를 추출한다.
-
CenterNet은 기존의 object detection의 stride 16 대신 더 큰 ouput resolution을 위해 stride 4를 사용한다. 더 큰 resolution은 다중 anchor에 대한 필요성을 제거하기 때문임.
일반적으로 학습하면서 feature map을 줄이는 궁극적인 요소는 계산량을 줄이고 더 깊게 학습하기 위함이라 stride를 16을 사용한다. 이미지 크기가 512 512라고 할 경우 512 / 16이라면 최종 feature map은 32 32가 되는데, 512 / 4 라면 최종 feature map은 128이 나오게 된다.
resolution 즉, 해상도가 높아지면 당연히 성능은 좋아질 수 밖에 없고 연산량과 계산량이 늘어나게 된다. 이 때문에 anchor box를 사용하지 않아도 성능은 좋아질 수 밖에 없다.
Object detection by keypoint estimation
Keypoint 추정을 이용한 object detection task는 기존에 있다. cornernet이 대표적이며 bbox의 두 모서리를 keypoint로 감지하여 물체의 상단, 하단, 왼쪽, 오른쪽, 중앙점을 포함한 모든 keypoint를 탐지한다. 이들 방법 모두 centernet과 동일한 keypoint 추정 network를 기반으로 한다. 다만, keypoint 추정 후에 combinatorial grouping 단계를 요구하여 속도가 저하된다.
conbinatorial grouping(조합적 그룹화)이란?
탐지된 여러 keypoint를 적절히 조합하여 하나의 object를 구성하는 과정을 의미한다. 이 과정에서 탐지 속도가 저하되는데 그 이유는 한 이미지에 여러 object가 있을 경우 탐지된 keypoint들이 서로 섞이게 된다. 이렇게 탐지된 keypoint들 중에서 어떤 keypoint들이 같은 class를 갖는 object인지 식별해야 하므로 이런 매칭 과정을 통해 탐지 속도가 저하된다.
Monocular 3D object detection
3D bbox 추정은 자율주행에 필수적이다. Deep3Dbox는 RCNN 프레임워크를 사용하여 속도가 느림.
3. Preliminary
입력 이미지 I는 전체 실수 R에 대하여 너비는 W이고 높이는 H인 RGB 3채널을 갖는다. keypoint는 0과 1사이로 이루어진 W/R H/R C 로 이루어지는데, 여기서 R은 stride를 뜻한다. 앞서 설명한 것처럼 object detection에서 R는 16을 default로 사용하는데, centernet은 9개의 anchor box를 사용하지 않는 대신 resolution을 키워 small object도 탐지할 수 있도록 feature size를 키웠다. 논문에선 R을 4로 사용했다. 따라서 heat map의 크기는 전체 이미지 크기에서 4로 나눈 값으로 출력되는 것을 알 수 있다. 또한 C는 keypoint의 갯수인데, 사람 포즈 추정을 위한 17개의 관절과 차량 감지를 위한 80개의 카테고리가 존재한다.
예측한 Y^의 값이 1에 가깝다면 keypoint를 감지했음을 의미하고 0에 가깝다면 backgroud에 해당된다. fully convolutional network 기반의 encorder-decorder network이다.
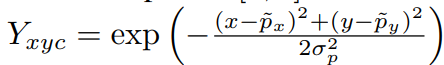
키포인트 예측 값은 위의 식을 통해 구해지게 된다.
x : heatmap의 x 좌표 위치
y : heatmap의 y 좌표 위치
μx : groundtruth keypoint의 x 좌표 위치
μy : groundtruth keypoint의 y 좌표 위치
이 식은 각 heatmap 좌표 x, y에서의 Gaussian distribution 값을 계산하는 과정이다. 왜 Gaussian distribution을 구하는 걸까? 그걸 알기 위해서는 heatmap에 대해서 알아야 한다.
heatmap이란?
keypoint 추정 문제에서 heatmap은 각 keypoint의 위치를 시각적으로 나타낸 것이다. 일반적으로 이미지 크기를 줄인 형태로, 특정 keypoint가 있을 가능성을 나타내는 확률 분포를 각 coordinate에 저장해 두는 2D map이다.
keypoint 예측 문제에서 Gaussian distribution을 사용하는 목적은 groundtruth keypoint가 이미지의 특정 coordinate에 약간 불확실성을 갖기 때문이다. Labeling을 하면서 객관적인 기준이 조금씩 달라지기도 하고 온전히 정확한 위치값을 갖지 못하기 때문이다. 이 때문에 Gaussian distribution으로 표현하는 것이다. Gaussian distribution은 특정 위치를 중심으로 점차 확률이 낮아지는 형태로 위치의 '중심'과 주변'범위'를 모두 고려할 수 있다.
거리 계산을 통해 구해진 값들은 Gaussian function 을 통해 kepoint의 중심에서 멀어질수록 지수적으로 감소하게 만든다.
위의 수식에서 σ는 object의 크기에 따라 비례적으로 설정된 표준편차이다.
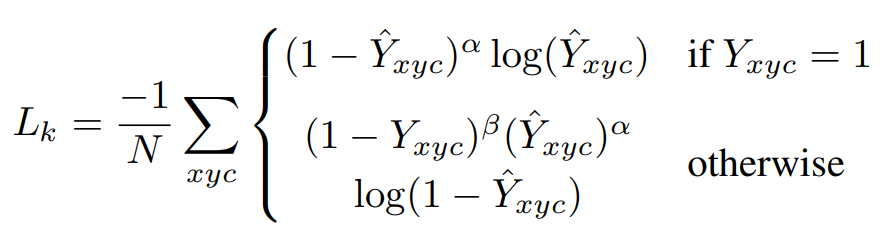
논문을 읽다보면 위의 조건문 Y와 Gaussian distribution의 Y는 다르다. 보기엔 같아보이지만 Gaussian distribution을 통해 나온 Y값은 0과 1사이의 확률값을 갖게 되는데, Loss function에서 사용한 Y는 특정 위치에서의 Y가 1이라는 조건을 나타내고 이는 실제 keypoint의 위치를 의미한다.

α와 𝛽는 Focal Loss의 hyperparameter이며 N은 이미지내의 keypoint 갯수이다. N으로 normalization을 하는 이유는 positive focal loss instance가 1이 되도록하기 위함이다.α는 2, 𝛽는 4를 사용한다.
또한, offset에 대한 Loss function도 같이 해줘야 하는데, 이는 Quantization 때문이다. 이 Quantization이 필요한 이유는 Feature map의 저자가 언급한 stride 4를 사용해 원본 이미지보다 줄어들었기 때문.
원본 이미지의 keypoint 중심좌표가 4로 나누어 떨어지지 않거나 소수점일 경우 feature map -> heatmap의 keypoint 중심좌표는 부동소수점으로 나타내짐. 그렇다보니 원본이미지의 keypoint 위치와 다운 샘플링된 heatmap의 keypoint의 위치가 서로 다른 offset이 발생할 가능성이 있다.
예를 들어, 원본 이미지의 keypoint 좌표가 (25.3, 40.7)이고 stride가 4일 경우 downsampling된 heatmap의 keypoint는 (6.325, 10.175)로 계산된다. 하지만 feature map 즉, heatmap은 이 좌표를 정수로 취급해야 하기 때문에(6, 10)으로 Quantization된다. 이 오차를 보정하기 위해 offset 값을 추가적으로 예측해야 한다.
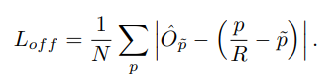
offset의 loss function은 L1 loss를 통해 구해진다. 모든 class는 동일한 offset prediction을 공유하게 된다.
해당 offset loss function은 keypoint location에 대해서만 학습되고 나머지 location에선 무시된다. 이 말이 무슨 뜻이냐면, centernet은 중심점이 keypoint인 단 하나만의 Anchor를 사용하는 구조이기 때문에, 중심점이 매우 중요하다. Quantization을 사용하는 것도 이 중심점 때문에 사용하는 것이기 때문에 이 중심점에 대한 보존이 매우 중요하다는 것이다. 따라서, 정확히 keypoint가 1인 곳에서만 offset을 구하면 되고 나머지 location은 그리 중요하지 않다는 것을 의미한다. 객체의 중심점이 아니라면 모두 무시해도 될정도로 중심점만은 반드시 찾고 예측된 offset으로 복원할수 있는 작업을 하는 것.
