최근 Object Tracking에 관한 assignment를 받아서 관련 분야에 대해 학습을 해보려고 한다. Object Detection과 Object Tracking의 차이점을 명확히 알고 넘어가자.
Object Detection : 개별 Frame에서 객체를 인식하는 것.(독립적)
Object Tracking : Object Detction을 통해 인식된 객체를 여러 Frame에서 추적하는 것.(의존적)
Object Tracking에서도 Detection-free-tracking 방식이 있긴하나, 해당 방식은 고정된 환경에서만 사용이 가능하다. 새로운 객체가 들어오거나 기존 객체가 사라지는 상황이 생기면 무용지물이 되기 때문에 최근에는 Tracking-by-Detection 방식을 선호한다.
Tracking-by-Detection
Tracking-by-detection 방식도 크게 두가지로 나뉜다. Single Object Tracking(SOT)와 Multiple Object Tracking(MOT)로 구분된다.
SOT : 단일 객체에 Focus를 맞추기 때문에 간단한 구조이지만 Frame에서 사라지거나 다시 등장하면 처리가 어렵다. 스포츠에서 특정 선수나 공을 추적할때 사용하는 편.
MOT : 여러 객체를 Tracking하기 때문에 ID관리와 association 계산이 중요, 객체의 Re-Detection 및 Occlusion 처리가 매우 중요하다. 교통 상황에서 차량 및 보행자 추적을 할때 사용하는 편.
최근에는 Re-Detection을 하기 위해서 Re-identification(ReID)를 학습하는 Deep-SORT를 사용하는데, 이는 SORT에 대해 정확히 알아야 하기 때문에, 우선적으로 SORT 논문을 리뷰하여 관련 지식을 학습해보려고 한다.
ABSTRACT
해당 논문은 다중 객체 추적(MOT)에 대한 실용적인 접근 방식을 탐구한다. Detection 품질이 추적 성능에 영향을 미치는 주요 요소로 확인되었으며, detector를 변경하면 최대 18.9%까지 Performance를 향상시킬 수 있음으로 증명했다. Kalaman Filter와 Hungarian Algorithm 사용으로 높은 정확도를 달성했다고 말하고 있다.
앞서 말했듯, SORT는 Tracking-by-Detection의 Algorithm이므로 Detection이 선행되어야 한다. Detection에서 객체를 명확하게 계속 탐지하느냐에 따라 SORT Algorithm의 Performance를 향상시킬 수 있다.
1. INTRODUCTION
Object Detection은 각 Frame에서 object를 탐지하고 bounding box로 표현한다. 기존의 배치 기반 추적 방법과는 달리 이전 및 현재 frame에서 탐지된 결과만을 추적하는 온라인 추적에 초점을 맞춘다.
Batch-based Tracking
추적할 데이터가 모두 준비된 상태에서 모든 frame을 한꺼번에 처리하여 최적의 추적 결과를 계산하는 방식이다. Batch-base Tracking 방식에서 가장 독특한 것은 미래 frame의 정보도 활용하는 것이다.
특정 frame에서 object의 움직임을 추적할 때, 과거 frame뿐만 아니라 미래 frame의 정보도 활용한다.
모든 frame을 고려하기 때문에 정확도 자체는 매우 높지만 고정된 환경에서만 적용할 수 있다는 점이 매우 큰 단점이다.
MOT는 Data Association 문제로 볼 수 있으며, 어떤 Frame에서 object를 연관시키는 것이 목표이다. 이를 위해 Tracking은 object의 Motion과 Appearance modeling을 위해 다양한 방법을 사용했다.
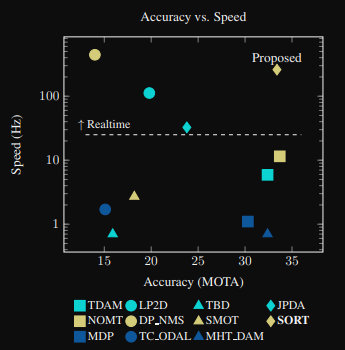
또한, 위의 벤치마크 성능을 보면 high accuracy를 가진 tracking은 real-time에선 너무 느리게 동작하는 문제점이 있었으나 SORT는 그것을 해결했다는 것을 보여주었다.
Occam's Razor의 원칙에 따라, 추적 과정에서 Detection 구성 요소를 넘어선 Feature 정보는 무시되며, bounding box의 위치와 크기만이 motion estimation(움직임 예측)과 data association(데이터 연관)에 사용된다.
Occam's Razor의 원칙이란?
단순함을 선호하는 원칙으로 '불필요한 복잡성을 배제하고 가장 단순한 해결책을 선택하자'라는 의미를 가진다.
short-term and long-term occlusion에 대한 문제는 무시한다. 보통 이러한 현상은 드물게 발생하며 Tracking framework에 복잡성을 부여하기 때문이다. 거기에 object re-identification 형태의 복잡성을 도입하게 되면 상당한 overhead가 발생하여 fps가 저하되어 real-time에서 사용할 수 없다고 판단하였다.
해당 논문의 주요 기여는 다음과 같다.
- MOT context에서 CNN 기반 detector의 강점을 활용한다.
- Kalman Filter와 Hungarian Algorithm에 기반한 실용적인 Tracking 접근 방식을 MOT 벤치마크에서 평가한다.
2. LITERATURE REVIEW
MOT(다중 객체 추적)은 Multiple Hypothesis Tracking(MHT), Joint Probabilistic Data Association (JPDA) Filter를 사용하였었는데, 이 방법들은 object 할당에 대한 높은 불확실성이 있을때 결정을 뒤로 미루는 방식을 취하는데, 객체의 수가 지수적으로 증가하게 되면 real-time에서 사용할 수 없게 만든다. (온라인 추적 부적합)
motion 정보는 detection 결과를 track과 연결하는데 자주 사용되며, Hungarian algorithm과 같은 글로벌 최적화 방법을 사용하여 온라인 추적에 적합하게 설계하였다.
Geiger 등의 방법을 보자면
- Tracklet 생성
-> 인접 frame의 detection 결과를 기반으로 gracklet을 형성
-> geometry cues와 appearance cues를 결합하여 유사도 행렬을 형성- Occlusion 문제 해결
-> Occlusion으로 인해 끊어진 track을 연결하기 위해 다시 geometry와 appearance 활용
3. METHODOLOGY
제안된 방법은 Detection, object 상태를 미래 frame으로 전파, 현재 detection 결과를 기존 object와 associating, tracked object의 수명 관리의 구성 요소들로 설명한다.
3.1 Detection
CNN 기반 detection 기술에서 detection framework인 Faster RCNN를 사용한다. Faster RCNN은 두 단계로 구성된 end-to-end framework이다.
- 첫 번째 단계는 feature를 추출하고 제안 영역을 생성한다.
- 두 번째 단계는 제안된 region에서 object를 classification 한다.
SORT Algorithm을 이해하기 위해서는 그리 필요하지 않은 sector이다. 최근에는 Faster RCNN보다 더 성능이 좋은 Yolo 시리즈를 사용하고 있으며 real-time에서 더 빠르고 더 높은 performance를 보여주는 detector들이 많이 나오고 있기 때문에, 굳이 Faster RCNN을 사용할 필요는 없다. Detection의 역할은 object의 위치의 bbox와 confidence score를 frame단위로 보내는 역할만 하게 된다.
3.2 Estimation Model
해당 sectort에서는 object를 다음 frame으로 전파하기 위해 사용되는 representation과 motion model을 설명한다. 각 객체의 frame간 이동을 카메라 움직임 및 다른 객체와 독립적인 선형 등속도 모델로 근사하는데, 다음과 같이 모델링된다.
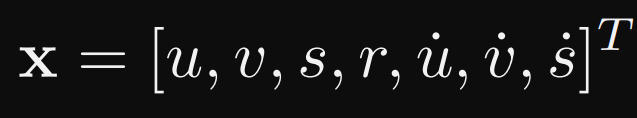
- u, v : oobject 중심의 수평 및 수직 픽셀 위치를 나타낸다.
- s : bounding box의 크기를 나타낸다.
- r : bounding box의 종횡비를 나타낸다.
나머지 3개는 시간에 따른 변화율을 의미하는데, 이는 kalman Filter Framework를 통해 최적화된다.
3.3 Data Association
detection 결과를 기존 대상에 할당하는 과정에서, 각 대상의 bounding box geometric은 현재 frame에서 새로운 위치를 예측하여 추정한다. 이는 Estimation Model에서 설명한 것과 같이 motion model을 사용하여 구한다.
Detected object와 이전 프레임에서 추적 중인 object를 matching하기 위해서 Kalman filter와 같은 motion model(velocity, acceleration)을 사용해 계산한다. 예를 들어 이전 frame에서 추적된 객체가 (x, y) 위치에서 vx, vy 속도로 움직이고 있다면, 현재 frame의 예측 위치는 (x + vx, y + vy)로 계산된다.
assignment cost matrix는 각 detection 결과와 기존 대상의 모든 예측된 bounding box 사이의 IoU거리로 계산된다. 이건 조금 설명이 필요한 부분같다.
이 부분을 이해하기 위해서는 조금 부가적인 설명이 필요하다.
Motion model을 통해 예측된 bounding box의 이해
우선 Detection을 통해 나온 object의 bounding box가 총 4개가 있다고 가정하자. 근데 Motion Model을 통해 예측된 bounding box의 갯수는 4개 이상일 수 있다.
왜냐하면 Motion model은 추적된 객체가 (x, y)위치에서 vx, vy 속도로 움직인다고 예측하고 있으니 bounding box의 coordinate에 vx, vy를 더해주면 되므로 Motion Model또한 object의 bounding box의 위치 coordinate를 갖고 있다고 할 수 있다.
근데 왜 detection model은 4개의 객체이고 motion model의 예측된 객체는 그 이상일 수 있는가?
그 이유는 detectort가 과거에 보고 있던 frame에서는 객체가 5개 이상이었지만 현재 frame에서는 4개의 객체만 존재하기 때문이다. motion model은 사라진 객체에 대해서도 좌표를 예측하고 있기 때문에, 4개 이상의 bounding box에 대한 정보를 갖고 있는 것.
Cost Matrix의 이해
Cost matrix는 1 - IoU로 구해진다. IOU는 bounding box(detection bbox, predicted bbox)의 합집합 영역을 겹치는 영역으로 나눈 값인데, 이렇게 나온 값을 1에서 빼서 구하게 된다.
위의 예시에서 detection model이 총 4개의 bounding box를 detection했고 Motion model이 총 5개의 bounding box를 예측했다면 cost matrix는 4*5 형태의 matrix를 갖게 되며 IoU가 높을수록 비용이 낮아지도록 matrix가 구성된다.
Cost Matrix를 구한 후 Hungarian Algorithm을 통해 cost를 최소화하는 matching을 찾는다.
detection 결과와 predict 대상 간 matching cost를 최소화한다. 각 detected 결과는 하나의 predicted 결과와만 매칭될 수 있다. 만약, 어떤 결과와도 매칭되지 않으면 tracking에서 제외된다.
위의 예시에서 detector가 4개의 bounding box를 탐지했고 motion model이 5개의 bounding box를 예측했다면 Hungarian Aloorithm을 통해 Cost가 가장 낮은 값을 갖는 4개만 매칭되고 motion model이 예측한 나머지 한개의 bbox(현재 frame에선 이미 사라진 object)는 detector가 탐지한 어떤 bbox와도 매칭되지 않으므로 제외된다는 것.
또한 논문에서는 IOU 기반 단기적 가림 처리로 Occlusion 현상을 처리하였다.
motion model을 통해 예측한 bbox와 detector를 통해 나온 bbox IoU를 계산하여 매칭한다. 즉, 어떤 A라는 object가 B라는 object에 가려질 경우 A와 B의 중심으로 하나의 bbox만 detect되겠지만 motion model은 objcet A가 탐지되지 않았으므로 Motion Model로만 예측한다. 그러다 Tracking Retention Time에 따라 detect가 되지 않으면 tracking에서 제외한다.
3.4 Creation and Deletion of Track Identities
object가 frame에 나타나거나 사라질때, 고유한 ID가 생성되거나 삭제된다. detect 결과가 IoU의 최소값을 가지게 되면 새로운 object의 존재를 나타낸다고 간주한다. 이때, bbox의 geometric 정보를 사용하여 초기화하고 velocity는 0으로 설정된다.
kalman filter를 사용한 추적기는 Probationary period(시험 기간)을 거치는데, 이 기간 동안 새로운 object는 충분한 evidence가 accumulate될때까지 기다리는데, 이는 detector가 잡아야할 object가 아닌 feature가 비슷한 잡지 말아야할 object를 잡을 수 있기 때문에, detector가 연속적으로 해당 object를 잡고 있는지 시간이 필요하게 됨.
이는 False Positive 오탐지 추적을 방지하기 위해 설계했다.
track 삭제는 object가 Tlost 프레임 동안 탐지 되지 않을 경우 수행된다.
T lost란?
- object가 detection되지 않아도 tracking 상태를 유지하는 최대 frame 수를 말한다.
- object가 T lost frame 동안 연속으로 detection되지 않으면 해당 object는 tracking에서 삭제된다.
실험에서는 T lost를 1로 설정했는데, 그 이유는 Constant Velocity의 한계와 object 재식별(ReID)를 고려하지 않기 때문이다.
Constant Velocity의 한계
object가 일정한 속도로 움직인다고 가정.(이 가정은 복잡한 환경, 예측 불가한 환경에선 불가능)
이전 frame에서 (x, y)에 있던 객체가 vx, vy 속도로 이동중이라면, 다음 frame에서는 (x + vx, y + vy)에 있을 것으로 예상하는데, 그렇지 않은 환경에선 비선형적으로 움직이게 된다.따라서 T lost를 1로 설정하면 motion model에 의존하는 시간을 최소화하고 잘못된 예측을 줄일 수 있다.
object Re-identification 고려 X
해당 연구는 frame간 traking에 focus를 맞추고 있으므로 ReID는 포함하지 않았다. ReID의 경우 Occlusion으로 인해 사라졌던 object가 다시 등장했을 때 동일 object로 인식하는 작업을 말하는데, 해당 연구에서는 다시 나타난 object를 새로운 object로 간주하게 된다.
이 부분이 SORT Algorithm의 가장 치명적인 부분이다. 그래서 Deep SORT 연구가 후속적으로 나오지 않았나 싶다. tracking에서 object Re-identification은 매우 중요한 요소이기 때문에(task에 따라 다르기도 함) task에 따라서 해당 기능을 포함시킬지 말지 고민이 필요한 부분.
