CenterNet paper : https://arxiv.org/pdf/1904.08189
centernet은 기존의 object detection model과 다른 양상을 보여주는데, 기존에는 Based-Anchor 기반으로 학습을 하였다. yolo기준으론 하나의 grid에서 n개의 anchor box를 생성하여 object가 해당 grid에 위치하고 어느정도의 size를 갖는지 예측하는 task를 진행했다. CenterNet은 Anchor free라고 하지만 n 개의 Anchor bbox를 사용하는 다른 model들과는 달리 하나의 Anchor를 사용하여 object의 localization과 size를 측정하는 task이다보니 Anchor free구조로 유명하다.
오늘은 해당 paper를 review해보려고 한다.
Abstract
해당 논문은 적은 cost(n개의 anchor를 사용하지 않았으므로 memory가 적게 들음.)로 짤린 영역에 대하여 시각적인 패턴을 분석하여 효율적인 해결책을 제시한다. 우리의 framework는 one-stage-keypoint-based detector이며 CenterNet이라 불린다. 우리는 중앙 영역에서 더 많은 인식 정보를 제공하고 좌측 상단과 우측 상단의 풍부한 영역을 수집하는 corner pooling과 center pooling이라 불리는 두 가지의 module을 설계했다. MS-COCO dataset에서 CenterNet은 47.0%에 해당하는 AP를 기록했으며 이것은 1-stage detector 중 가장 뛰어난 모델과 비교해서 4.7%만 줄어든 놀라운 AP를 기록했다.
1. Introduction
Object Detection은 특히 CNN에서 많은 향상을 이뤘다. ground-truth object를 regression하여 찾는 미리 정의된 사각형 박스들로 구성되어 있는 Anchor-based model로 이루어져있다. 이 방법론은 높은 IOU(Intersection over Union)을 위해서미리 정의된 size와 ratio로 만들어지는 많은 Anchor를 필요로 한다. 게다가 anchor는 ground-truth box내에 aligned되지 않는데, 이는 bounding box classifcation task에 도움이 되지 않는다.
===> 이 말이 의미하는 것은 Anchor box는 이미 정의된 size, ratio로 object에 적합한 사이즈에 맞게 학습되는 것이 아니라 미리 정의된 크기와 비율로 설계된 anchorbox로 인해 예측된 box 내부의 object를 classification을 해야하므로 실제 ground-truth에 정확하게 aligned되지 않는다면 box classification task에는 도움이 되지 않으며 부정확한 localization을 내보낼 수 있다는 것을 의미한다.
이 Anhcor-based 접근접에서 벗어나기 위해서는 이미 제안된 Cornernet이라 불리는 keypoint-based object detection pipeline이 필요하다. 이는 anchor box를 우회하는 각 객체의 corner keypoint로 표현한다.

CornerNet paper : https://arxiv.org/pdf/1808.01244
cornernet에는 여러가지 한계점이 있는데,
- 후처리의 문제점
- Cornernet은 물체의 좌상단과 우하단의 coordinate를 개별적으로 검출한 뒤에 이 coordinate를 짝짓는 과정이 필요하다. Matching 과정에서 많은 cost가 발생함. 여기서 cost는 계산 과정이나 메모리 증가를 의미
- corner 감지의 어려움
- small object나 noise가 많은 background의 경우 pair corner coordinate를 찾기 어려움. object가 겹쳐져 있다면 corner간의 혼동이 일어나 cost 비용은 더 늘어나게 됨.
- 속도, 효율성 down
- model이 복잡하여 메모리와 효율성 측면으로 좋지않음. real-time task에 사용하기 위해서는 cost가 많이 줄어들어야 하는데, 그렇지 못한 모델이었음.
그래서 Fig.1을 보게 되면 부정확한 bounding box를 그리게 된다.

-> background가 복잡하고 noise가 많으수록 performance가 떨어짐.
우리는 이러한 문제를 해결하기 위해서, 제안된 영역내에 시각적인 패턴을 인지하는 능력을 cornernet에 넣어야 한다고 생각했다. 이 방법론은 bounding box 스스로 correctiness를 식별할 수 있도록 도와준다고 생각했다. 따라서 저자들은 하나의 keypoint를 사용한 기하학적인 중앙점을 찾아가고 적은 cost를 가지며 효율적인 해결책인 CenterNet을 발표했다. 그들의 직관은 ground truth box내의 높은 IoU를 갖는 bounding box를 예측하고 중앙 지역에 center keypoint의 probability를 부여했다. 따라서, 추론 동안에 corner keypoint로 생성된 객체 후보가 유효한 객체인지 확인하기 위해, bounding box 중심 여역에 동일 클래스의 center keypoint가 존재하는지를 검사한다.
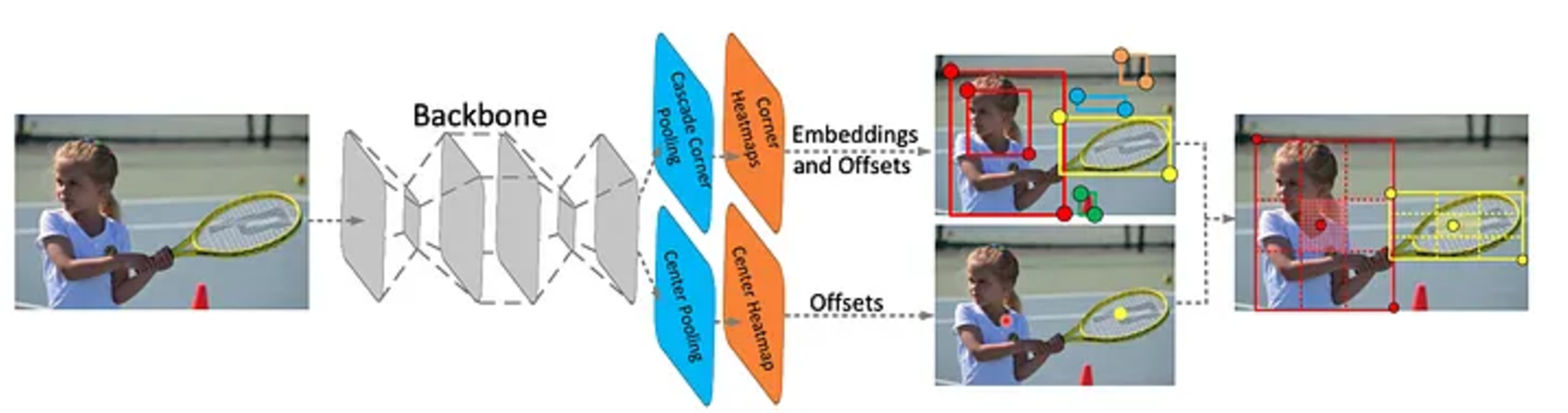
두가지의 task를 진행한다. Cascade Corner pooling을 통해 object의 corner 영역을 찾고 Center pooling을 통해 object의 center를 추적한다.
Center Pooling이란?
- center keypoint를 예측하기 위한 branch이다. center pooling은 제안된 중심 영역을 보다 쉽게 인지하기 위해서 객체내의 더 인지하기 쉬운 시각적인 패턴을 확보하기 위해서 도움을 준다.저자들은 예측하는 center keypoint를 위해 feature map의 center keypoint의 수직, 수평 방향에 대한 최대값을 합하여 이 task를 진행한다.
즉, 하나의 center point에 object coordinate가 2개의 쌍이 존재한다고 가정할때, center keypoint의 최소값보단 최대값에 민감하게 학습한다는 뜻이다. 위의 그림을 보는 person이라는 class를 inference한다고 가정한다면 face 부분의 bounding box와 person 부분의 bounding box의 두가지에 대해서 task를 진행한다고 했을때, face 부분도 person 영역이긴 하나 max sum calculate 과정에서 제외된다는 것을 의미한다. 더 큰 영역의 probability가 더 높고 작은 영역에 대한 probability가 더 낮다는 것인데, 이는 코드를 보면서 좀더 이해가 필요해보임. 결국에 큰 영역에 대해서 penalty를 부여하고 학습을 한다는건데, small object에 대해선 좋은 성능을 보일진 아직 잘 모르겠음.
Cascade corner pooling이란?
- 이는 이미 발표된 내용이긴 한데, 내부 정보를 인지하는 일반적인 corner pooling을 적용한다. 이 또한, 예측된 feature map의 객체 내부와 경계에 최대 값을 계산하여 값을 내뱉는다.
