(Deeplab V3+) Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation 논문 리뷰

저번 시간의 Deeplab V1의 논문 리뷰를 이어서 Deeplab V3+에 대한 논문을 리뷰해보려고 한다. Deeplab V3+는 최근에 2018년도에 나온 논문이고 현재에도 segmentation task를 담당하기도 한다. 요즘에는 더 좋은 모델이 나오기도 하겠지만 말이다.
Deeplab v3+ paper : https://arxiv.org/pdf/1802.02611.pdf
Abstract
"Specifically, our proposed model, DeepLab V3+, extends DeepLabV3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries."
Deeplab V1에서 그랬듯이 Spatial pyramid pooling module과 encode-decode structure 방식이 사용되었다. 기존의 Deeplab V3에서 확장하여 object boundaries를 따라 segmentation 결과를 개선하기 위해 decoder module을 추가하여 Deeplab V3+가 나오게 된 것이다.
또한, Xception model에 대해 알아보고 Atrous Spatial Pyramid Pooling, decoder module에 깊이별 분리 가능한 convolution을 적용하여 더 빠르고 강력한 encoder-decoder network를 만들어 냈다고 한다.
이번 Deeplab V3+ paper의 Abstract를 통해 우리가 관심있게 봐야할 논점은 이것들이다.
- Xception model
- decoder module
- Atrous Spatial Pyramid Pooling
- depthwise separable convolution
이 4가지에 대해 완벽히 이해하도록 하자!
1. Introduction
Abstract에서 간략하게 소개한 내용들이 다시한번 반복된다. 아직 서론이기 때문에, 자세한 동작원리는 후에 설명하겠지만, Abstract에 나온 내용들이 Introduction에 다시 반복될 만큼 매우 중요하다.
- We propose a novel encoder-decoder structure which employs DeepLabv3 as
a powerful encoder module and a simple yet effective decoder module.- In our structure, one can arbitrarily control the resolution of extracted encoder features by atrous convolution to trade-off precision and runtime, which is not possible with existing encoder-decoder models.
- We adapt the Xception model for the segmentation task and apply depthwise separable convolution to both ASPP module and decoder module, resulting in a faster and stronger encoder-decoder network.
결국엔 Abstract에 소개한 4가지를 다시 반복하는 셈이다.
우리가 Deeplab V1을 공부하면서 Spatial Pyramid pooling에 관해 공부를 했었는데, 이는 각각 다른 resolution에서 pooling feature에 의해 풍부한 문맥적 정보를 얻을 수 있어 segmentation에 유리한 것으로 알고 있다. 또한, encoder-decoder 구조를 통해 선명한 객체 경계를 얻을 수 있었다.
이제 여기서 더 나아가 Deeplab V3에서는 parallel atrous convolution 과 PSPNET을 통해 구현이 되었다.
근데 뭐가 문제이기에 이를 upgrade한 Deeplab V3+가 나오게 된 것일까?
1) 엄청나게 많은 정보를 갖고 있는 semantic information은 Network backbone을 통해 학습되어지면 stride를 사용하는 Pooling과 Convolution으로 인해 정보가 사라지는 문제가 발생하는 것이다.
2) 이를 해결하기 위해 Atrous Convolution을 사용하여 정보의 소실을 최대한 줄여보았지만 이조차도 문제가 발생한다.
3) 논문에서는 이를 Resnet-101 backbone을 통해 설명을 하는데, input에 비해 16배 작은 output을 얻기 위해서는 Residual block 3개 (layer 9개)의 특성을 확장시켜 주어야 한다. 또, 8배 작은 output을 output을 얻기 위해서는 26개의 Residual block의 특성을 확장시켜 주어야 한다. 이렇게 되면 또 계산이 몰리는 현상이 발생한다.
4) 다만 encoder-decoder 구조를 통해 encode path에는 더 빠른 계산(확장하는 기능이 없음)을 할 수 있고, decode path에는 선명한 객체 경계를 점진적으로 복구할 수 있도록 한다.
이를 그림으로 보면 다음과 같다.
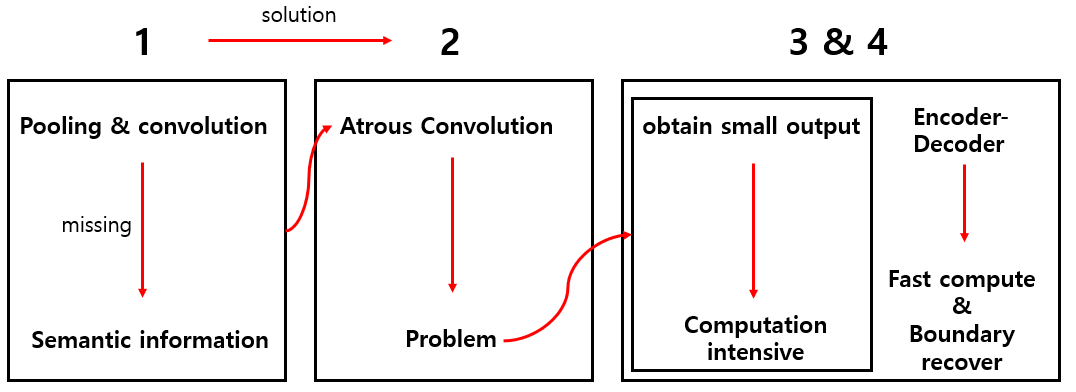 따라서 기존의 1, 2, 3, 4와 같은 Deeplab V3 방식에서 좀더 나아가 소실되는 정보도 줄이고 계산적인 부분도 해결하며 encoder-decoder 부분도 살짝 바꾸어 기존의 Deeplab V3 방식보다 높은 performance를 보여주었다.
따라서 기존의 1, 2, 3, 4와 같은 Deeplab V3 방식에서 좀더 나아가 소실되는 정보도 줄이고 계산적인 부분도 해결하며 encoder-decoder 부분도 살짝 바꾸어 기존의 Deeplab V3 방식보다 높은 performance를 보여주었다.
2. Related work
논문에서 이 부분에 대해서는 3가지를 말하고 있다. 계속 반복적으로 나오는 부분인 만큼 중요하다는 것!
Spatial Pyramid Pooling
Deeplab V3+에서는 Deeplab V3에 사용되었던 PSPNet과 Deeplab v1부터 사용되었던 Spatial Pyramid Pooling, Atrous Spatial Pyramid Pooling(ASPP)을 통해 좀더 upgrade된다.
Encoder-decoder
Segmentation을 하기 위해서는 일반적으로 Encoder-Decoder 구조를 갖어야 한다. Segmentation으로 유명한 FCN 논문을 참고하면 이도 어떻게 보면 Encoder-Decoder의 구조를 같는다.
(FCN 논문 리뷰 참고 :https://velog.io/@joon10266/FCN-Fully-Convolutional-Networks-for-Semantic-Segmentation-%EB%A6%AC%EB%B7%B0)
Deeplab V3+에서는 Encoder module은 deeplab V3와 동일하지만, 더 선명한 segmentation 정보를 얻기 위해 기존의 Decoder module에 효과적인 module를 추가한다. 우선 다시 한번 Encoder-Decoder를 이해하고 넘어가도록 하자.
- Encoder : 점차적으로 feature map을 감소하는 대신 높은 semantic 정보를 갖는다.
- Decoder : 점차적으로 spatial 정보를 회복한다.
Depthwise Separable Convolution
Depthwise Separable Convolution 같은 경우에는 Computation cost와 number of parameter를 줄이기 위해 고안된 강력한 operation이다. 이를 기반으로 Xception model이 나오게 되었다.
3. Methods
3.1 Encoder-Decoder with Atrous Convolution
Atrous Convoltion 같은 경우에는 Deeplab V1 논문 리뷰를 참고하도록 하자.
(Deeplab V1 논문 리뷰 : https://velog.io/@joon10266/Deeplab-Semantic-Image-Segmentation-with-Deep-Convolutional-Nets-Atrous-Convolution-and-Fully-connected-CRFs-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0)
하지만 이해가 되지 않는다면 이 블로그에 대한 내용도 같이 참고하여 이해하면 좋다.
(다양한 Convolution 기법 : https://eehoeskrap.tistory.com/431)
3.2 Depthwise Separable Convolution
Depthwise Convolution 같은 경우에는 아래의 그림과 같이 작동한다.
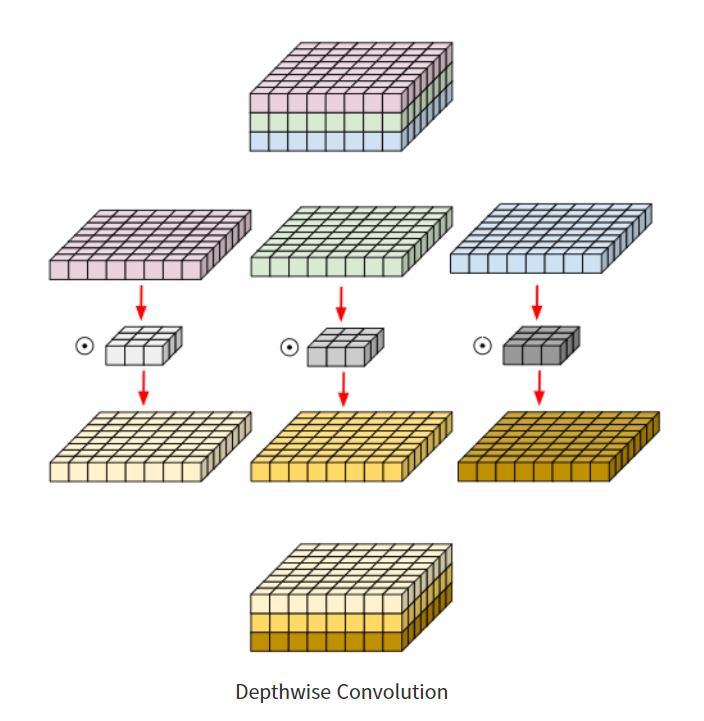 보통 우리가 Convolution을 진행하게 되면 Convolution filter는 모든 channel에 영향을 준다. RGB 영상이라고 한다면 하나의 filter가 모든 RGB에 대한 특징을 갖고 있는 것이다. 하지만 Depthwise Convolution은 다르게 동작한다.
보통 우리가 Convolution을 진행하게 되면 Convolution filter는 모든 channel에 영향을 준다. RGB 영상이라고 한다면 하나의 filter가 모든 RGB에 대한 특징을 갖고 있는 것이다. 하지만 Depthwise Convolution은 다르게 동작한다.
위의 그림을 보면 각 channel마다 다르게 동작하는 것을 볼 수 있다. 따라서 Convolution filter는 각 단일 채널에 대해서만 수행을 하다보니 연산량을 기하 급수적으로 줄일 수 있게 된 것이다.
기존의 Depthwise Convolution 에서 Atrous Convolution을 적용하면 논문에 나온 그림과 같이 작동하게 된다.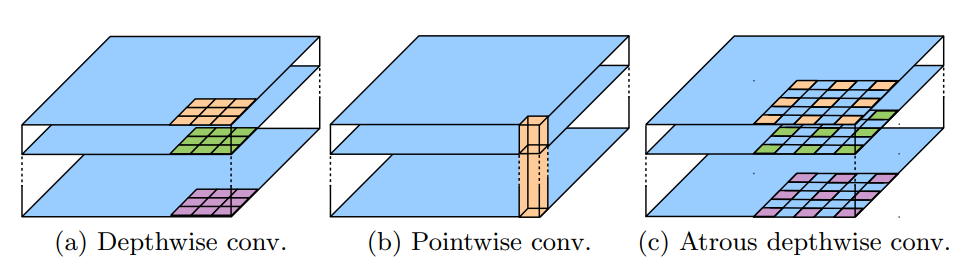 그림 C를 보면 기존의 Depthwise Convolution에서 Atrous Convolution 방식을 취하고 있는 것을 볼 수 있다. 이 이후에 Pointwise Convolution을 적용하는 것인데, 이는 1 x 1 Convolution 방식과 동일하므로 용어만 다르다고 생각하면 된다.
그림 C를 보면 기존의 Depthwise Convolution에서 Atrous Convolution 방식을 취하고 있는 것을 볼 수 있다. 이 이후에 Pointwise Convolution을 적용하는 것인데, 이는 1 x 1 Convolution 방식과 동일하므로 용어만 다르다고 생각하면 된다.
Pointwise Convolution == 1 x 1 Convolution
Resnet 논문을 분석하면 1 x 1 Convolution 방식이 무슨 역할을 하는지 알 수 있다.
(Resnet 논문 리뷰 : https://velog.io/@joon10266/Resnet-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0)
3.3 Deeplab V3 as encoder
Deeplab V3의 논문을 보면 다음과 같은 그림이 나온다.
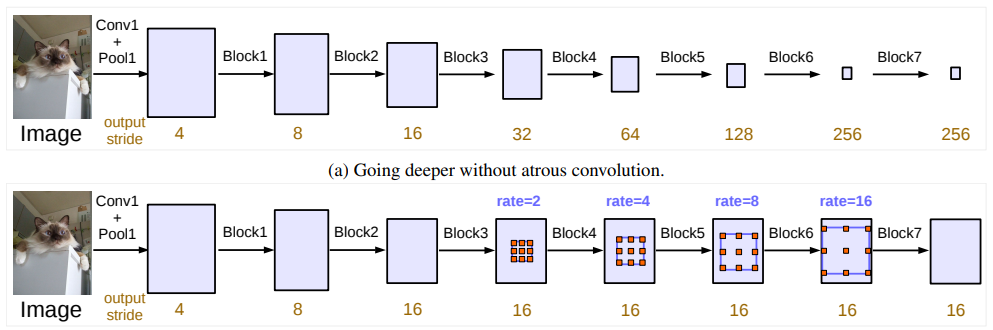 위의 그림은 Atrous Convolution을 사용하지 않은 Encoder module에만 해당된다. 아래의 그림은 Encode-Decode module이 모두 있는 구조라고 생각하면 된다.
위의 그림은 Atrous Convolution을 사용하지 않은 Encoder module에만 해당된다. 아래의 그림은 Encode-Decode module이 모두 있는 구조라고 생각하면 된다.
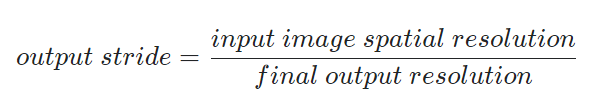
classification task에서는 output stride가 32이다. 이런 이유는 대게 spatial resolution의 final feature map은 input image resolution에 비해 32배 작다. 그래서 위와 같은 수식이 나올 수가 있게 된다.
그러나 segmentation task에서는 output stride가 16이다. 이는 32배 작게 만드는 것보다 16배가 더 나은 performace를 보여주기 때문이라고 생각한다. 이를 적용하기 위해서는 마지막에서 1, 2개의 block에서 striding을 없애고 Atrous Convolution을 적용시킨다.
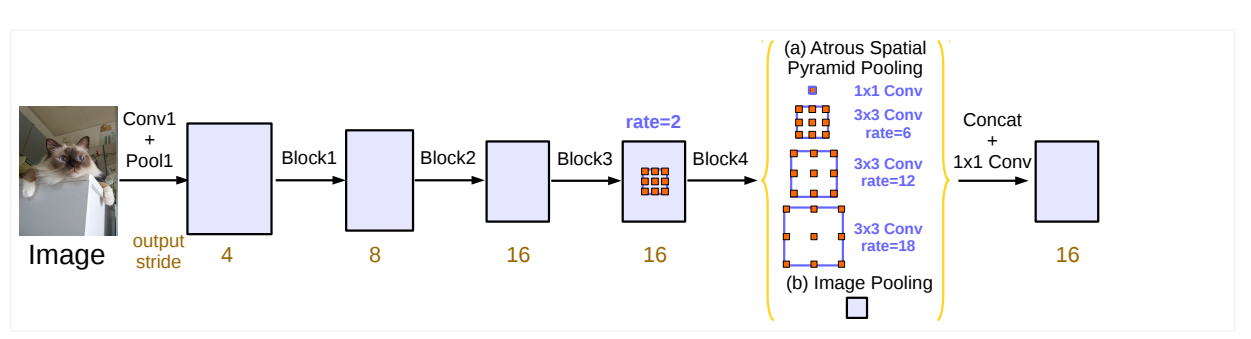 위의 Network에서 Atrous Spatial Pyramid Pooling을 적용시켜 여러 규모의 features를 조사할 수 있도록 한다.
위의 Network에서 Atrous Spatial Pyramid Pooling을 적용시켜 여러 규모의 features를 조사할 수 있도록 한다.
3.4 Proposed decoder
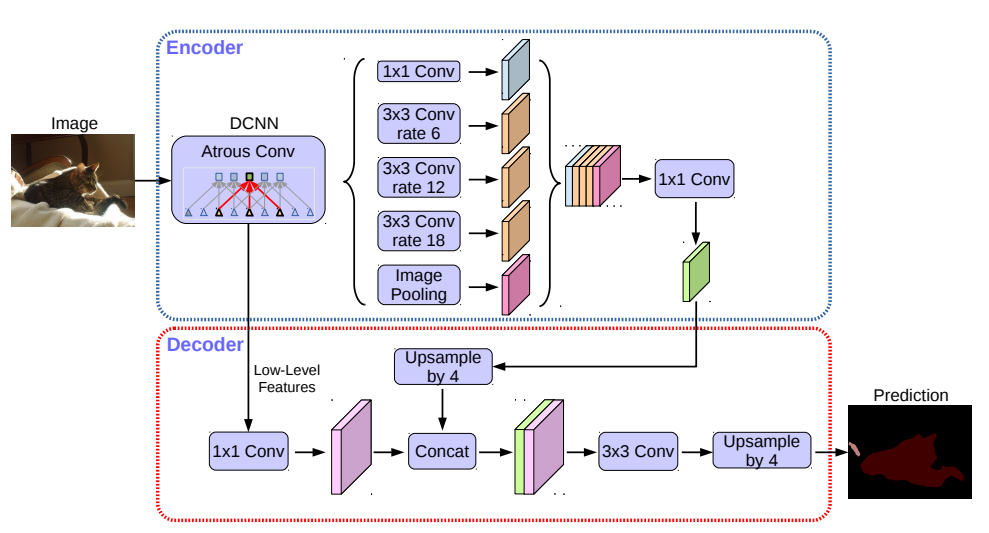 기존의 Deeplab V3에서의 encoder는 output stride = 16을 통해 나온 features는 decoder을 통해 16만큼 bilinearly upsample 되어진다. 그러나 이런 decoder는 object segmentation을 성공적으로 복구하지 못한다. 따라서 논문의 저자들은 위의 그림과 같은 형태를 가진 effective decoder module을 제시한다.
기존의 Deeplab V3에서의 encoder는 output stride = 16을 통해 나온 features는 decoder을 통해 16만큼 bilinearly upsample 되어진다. 그러나 이런 decoder는 object segmentation을 성공적으로 복구하지 못한다. 따라서 논문의 저자들은 위의 그림과 같은 형태를 가진 effective decoder module을 제시한다.
1) encoder에서 나온 feature를 bilinear upsample을 통해 4배 upsample을 한다.
2) Backbone Network(Resnet-101)를 통해 나온 중간 feature map(Low-Level Features)들을 단순히 16배 bilinear upsample 하고 1 x 1 Convolution에 적용시켜 channel의 수를 줄인다.
3) 1번과 2번이 같은 해상도를 갖을 때 Concat를 적용시켜 서로 연결한 다음, 3 x 3 Convolution을 적용시킨다.
4) input image의 resolution과 같게 하기 위해서 output을 4배 upsample 해준다.
3.5 Modified Aligned Xception
Deeplab V3+에서는 Xception model을 사용했다고 한다. 이는 image classification에서 탁월한 성능을 보여주었다. 논문의 저자들을 이를 Semantic Segmentation에 적용한 것일 뿐이다. 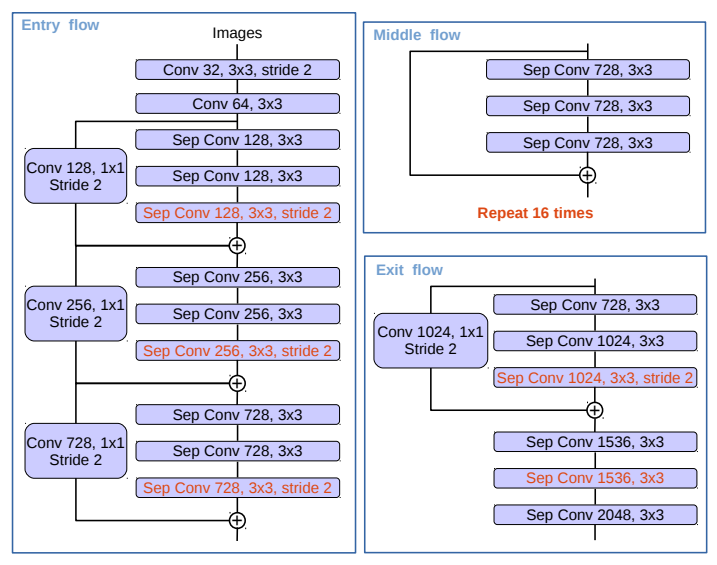 이는 원래 MSRA팀이 기존의 Xception model을 수정하여 사용하였으나 Deeplab v3+연구자들은 이를 조금 더 수정하여 사용하였다.
이는 원래 MSRA팀이 기존의 Xception model을 수정하여 사용하였으나 Deeplab v3+연구자들은 이를 조금 더 수정하여 사용하였다.
- MSRA팀의 Xception model에 빠른 계산과 메모리 효율성을 위해 진입 흐름 네트워크 구조를 수정하지 않은 점을 제외하고는 동일하다.
- all max pooling operation들을 모두 striding을 사용한 depthwise seperable convolution으로 바꾸어 사용한다.
- 3 x 3 Convolution 이후에 batch normalization과 ReLU activation 적용된다.
4. Experimental Evaluation
https://velog.io/@skhim520/DeepLab-v3#experimental-evaluation
이 부분은 이 블로그에서 설명이 잘되어 있어서 이쪽을 참고하면 좋을 것 같다. 대부분이 실험에 대한 증명 혹은 결과이다. 위의 내용을 제대로 이해했다면 이 결과에 대해서도 쉽게 이해하고 넘어갈 수 있다.
