(Deeplab v1) Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully connected CRFs 논문 리뷰
이번 논문 리뷰는 Deeplab이다. 현재까지 Deeplab v3+까지 나온 것으로 알고 있다. Semantic segmentation에서 많이 사용되었고, segmentation에 대해 찾아보면 항상 있는 논문중의 하나이다. 그럼 분석을 시작해보자!
Deeplab paper : https://arxiv.org/pdf/1606.00915.pdf
Deeplab 참고 블로그 : https://m.blog.naver.com/laonple/221017461464
Abstract
"we address the task of semantic image segmentation with Deep Learning and make three main contributions that are experimentally shown to have substantial practical merit"
논문의 저자들은 Deeplab을 구현하는데 크게 3가지 방법들이 있다고 한다.
- Atrous convolution (= dilated convolution)
- Prediction task
- Control the resolution
- Restore information without amount of computation
- Atrous Spatial Pyramid Pooling (ASPP)
- Robustly segment objects at multiple scales
- fully connected Conditional Random Field (CRF)
- Improve localization accuracy performance
앞으로 이 3가지에 대해 중점적으로 설명하게 될 것이다.
1. Introduction
Deep Convolutional Neural Networks(DCNN)은 computer vision에서 많은 영향을 끼친 것은 매우 당연하다. 이를 통해 우리는 한층 classifier을 잘 할수 있게 되었다. 하지만 모든 것에는 단점이 있는 법이다.
우리가 해야할 Semantic Segmentation을 하기 위해서 DCNN만 사용하기 에는 쉽지 않다. DCNN 특성상 classification에 최적화된 Networks라서 Semantic Segmentation을 하기 위해선 뭔가를 추가해줘야 한다.
(ex. 카레를 만들때 감자, 고기(햄), 당근 등을 넣는 것과 마찬가지이다.)
그럼 DCNN이 classification에 최적화 되어 있으니 이를 이용해서 Semantic Segmentation을 할 수 있으면 좋겠다라는 것이다.
그러면 DCNN을 사용하여 Semantic Segmentation을 구현하려면 무엇을 고려해야 하는가?
-
reduced feature resolution
- feature 의 해상도가 점점 작아짐
-
existence of objects at multiple scales
- 여러 개의 scale(filters(?))에서의 객체의 존재를 찾기 어려움
-
reduced localization accuracy
- localization accuracy의 감소
- feature map size가 점점 감소하므로 이를 downsampling하면 localization accuracy가 감소할 수 밖에 없다.
1.1 Reduced feature resolution (First)
DCNN에서 우리가 down-sampling을 한다면 stride와 max-pooling을 사용한다. 우리가 나중에 사용할 spatial resolution이 계속 해서 줄어든다. 결국 마지막에 다다르면 사용할 수 있는 spatial resolution은 원본 image에 비해 매우 작아져 segmentation을 할 수가 없게 된다. 할 수 있어도 사용할 수 없을 정도이다.
(이해가 제대로 안되면 U-NET :https://velog.io/@joon10266/U-Net-Convolutional-Networks-for-Biomedical-Image-Segmentation 을 참고하고 오도록 하자.)
그렇다면 이러한 문제를 어떻게 해결할까?
"we remove the downsampling operator from the last few max pooling layers of DCNNs and instead upsample the filters in subsequent convolutional layers, resulting in feature maps computed at a higher sampling rate."
몇개의 max-pooling layer을 앲애는 대신에, up-sampling을 하는 filter을 넣자. 여기서 up-sampling 담당하는 것이 Atrous filter(=Dilated filter(convolution)) 이다. 이 Atrous 방식은 signal process에서도 자주 사용된다. 이를 deconvolution layer 라고 부르기도 한다.
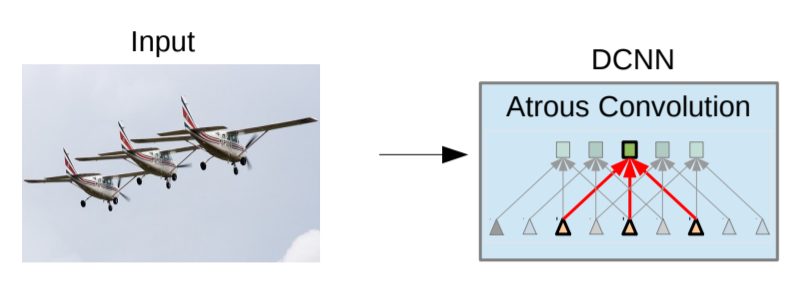
==> 일반적인 convolution과 비교하면 parameter와 computation이 증가하지 않고 효율적으로 넓은 공간을 탐색할 수 있게 된다.
1.2 Existence of objects at multiple scales (Second)
Input_image를 DCNN에 넣으면 Input_image에 대한 여러가지 rescaled된 filter들이 나오게 된다. 이 filter들의 feature와 score map을 종합하여 existence of object를 탐지한다.
--> 이 같은 경우 이를 만들기 위해 엄청나게 많은 계산들이 이루어져야한다. 그렇게 되면 속도 측면에서의 performance가 매우 떨어진다.
이를 해결하기 위한 방안이 "Spatial Pyramid Pooling"이다.
"This amounts to probing the original image with multiple filters that have complementary effective fields of view, thus capturing objects as well as useful image context at multiple scales."
상호 보완적인 유효 시각을 가진 여러개의 filter를 사용하여 원본 이미지를 조사하는 것과 같으므로 여러 개의 규모에서 사용될 이미지 정보를 가져와 객체를 가져온다.
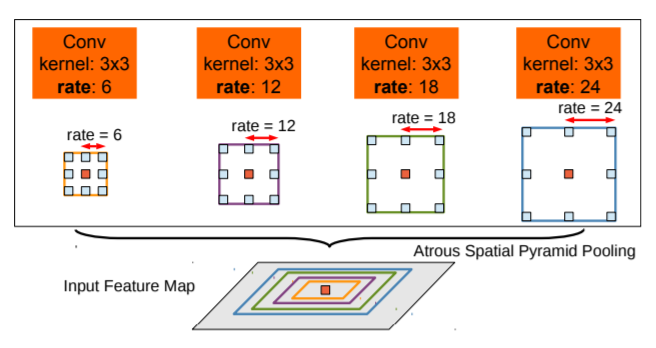
그냥 단순히 resampling 하는 것보다 multiple parallel atrous convolutional layer을 사용하여 효과적으로 구현한다.
이를 "Atrous Spatial Pyramid Pooling(ASPP)"라 부른다.
1.3 Reduced localization accuracy
"CRFs have been broadly used in semantic segmentation to combine class scores computed by multi-way classifiers with the lowlevel information captured by the local interactions of pixels and edges [23], [24] or superpixels [25]."
CRF는 semantic segmentation에서 사용되며 multi-way classifier에 의해 계산된 클래스 점수를 픽셀과 에지 또는 슈퍼픽셀의 로컬 상호작용에 의해 저장된 low-level 정보와 결합한다. 라고 하는데, 솔직히 지금은 이해 안간다. 본론에서 CRF에 대해 자세히 설명하므로 궁금증은 잠시 접어두자.
2. Method
논문의 저자들은 3가지 방식을 제안했다고 말했다. Introduce에서 설명한 3가지 방법을 깊게 파헤쳐보자.
2.1 Atrous Convolution for Dense Feature Extraction and Field-of-View Enlargement
이들은 Atrous Convolution방식을 사용하여 사용한다.
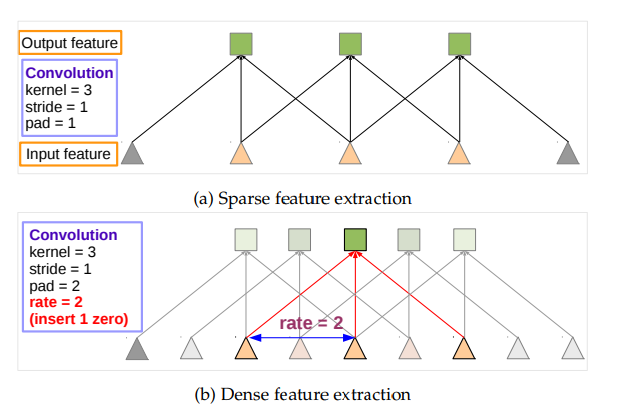 atrous convolution 참고 블로그 : https://better-tomorrow.tistory.com/entry/Atrous-Convolution
atrous convolution 참고 블로그 : https://better-tomorrow.tistory.com/entry/Atrous-Convolution
우리가 알고 있는 일반적인 CNN 방식은 위의 Sparse feature extraction방식을 따른다. 해석을 해보면 부족한 특징 추출이다. 무엇이 부족할까? 앞서 말했듯이 일반적인 CNN은 Classification을 하는데 정말 탁월한 성능을 보여준다. 하지만 이는 resloution(해상도)을 계속해서 줄여나가는 방법을 취한다(down-sampling).
일반 Sparse feature extraction 방식인 표준적인 CNN에 up-sampling을 적용시켜도 높은 resolution을 기대하기는 어렵다. 정말 어렵다... 그래서 이에 대한 방안으로 Dense feature extraction이 나오게 되었다.
Dense feature extraction 방식은 atrous convolution방식으로 알려져있다. 기존 논문에서는 hole algorithm으로 불리지만, deeplab V2이상 부터는 atrous convolution으로 불리니 그냥 atrous convolution으로 알고 있으면 된다. 그렇다면 atrous convolution이 어떤 것을 해결할까?
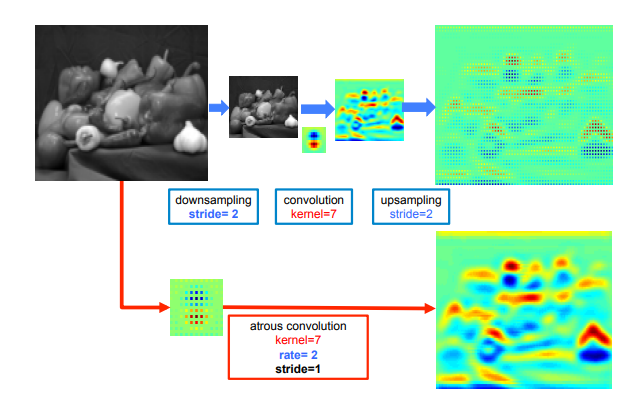 위의 그림은 기존의 CNN 방식에서 up-sampling을 진행한 결과이고 아래의 그림은 atrous convolution을 사용하여 얻어낸 결과이다. 확실히 높은 resolution을 뽑아낸 것을 알 수 있다.
위의 그림은 기존의 CNN 방식에서 up-sampling을 진행한 결과이고 아래의 그림은 atrous convolution을 사용하여 얻어낸 결과이다. 확실히 높은 resolution을 뽑아낸 것을 알 수 있다.
 atrous convolution의 수식이다.
atrous convolution의 수식이다.
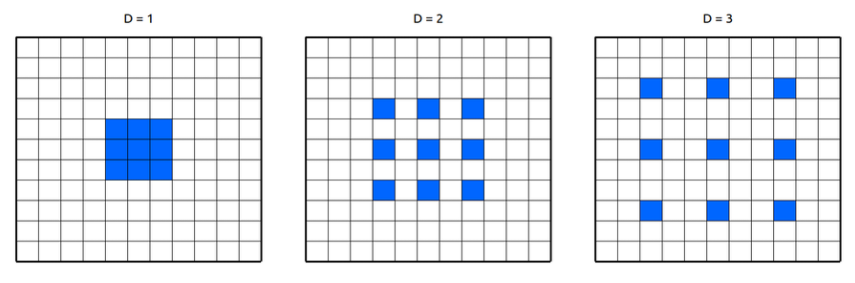 "If you insert the resulting feature map into the original image coordinates, you will see that you only get responses at 1/4 of the image positions."
"If you insert the resulting feature map into the original image coordinates, you will see that you only get responses at 1/4 of the image positions."
이를 해석하면 "결과 feature map을 원본 이미지에 삽입하면 이미지 위치의 1/4에서만 응답을 얻었다."라는 것인데, 이게 무슨 말일까?
우리가 rate parameter = 2로 주면 위의 그림에서 중간 과정처럼 작동을 한다. (파란색 부분이 filter이다. 첫번째 그림의 filter size = 3x3, 두번재 그림의 filter size = 5x5, 세번째 그림의 filter size = 7x7) 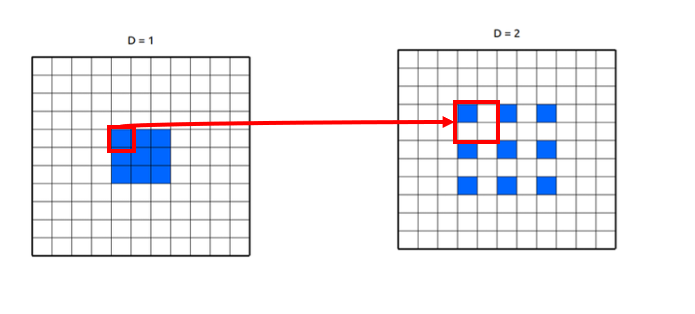 이 그림을 보면 저 위의 말이 이해가 될까? 의미 있는 값을 갖고 있는 것은 파란색 pixel뿐이다. rate parameter가 커져도 우리에게 필요한 부분은 의미를 갖는 non-zero(파란색 픽셀)부분만 보면 된다. 다른 부분은 다 0으로 채워져 있기 때문에, 당연히 연산량은 늘지 않고 up-sampling 효과를 불러 일으킨다.
이 그림을 보면 저 위의 말이 이해가 될까? 의미 있는 값을 갖고 있는 것은 파란색 pixel뿐이다. rate parameter가 커져도 우리에게 필요한 부분은 의미를 갖는 non-zero(파란색 픽셀)부분만 보면 된다. 다른 부분은 다 0으로 채워져 있기 때문에, 당연히 연산량은 늘지 않고 up-sampling 효과를 불러 일으킨다.
또한 논문의 저자들은 이 atrous convolution을 어디에 넣어야 할지 고민을 하고 끝내 어디 부분이 가장 문제가 있었는지 발견했다. VGG-16 과 Resnet-101같은 경우 Pool5와 conv5_1에서 resolution이 감소하는 것을 발견했다. 이를 atrous convolution으로 rate parameter = 2를 주어 대체하였다. 이러한 방법을 네트워크 전체에 적용하면 원래 이미지 해상도에 접근할 수 있겠지만, 이는 비용이 너무 많이 든다. 즉, 시간적인 부분에 대한 risk가 너무 크다.
그럼 atrous convolution으로만 해결이 안된다면 무엇으로 해결해야 하는가?
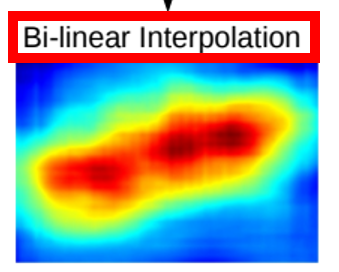 바로 bilinear interpolation(쌍선형 보간법)을 사용하는 것이다. 이는 atrous convolution보다 속도가 매우 빠르다. 앞서 배웠듯이, atrous convolution을 사용하면 feature map 커지는 것을 알게 되었을 것이다. 이를 bilinear interpolation을 통해 feature map을 확장하는 것이다.
바로 bilinear interpolation(쌍선형 보간법)을 사용하는 것이다. 이는 atrous convolution보다 속도가 매우 빠르다. 앞서 배웠듯이, atrous convolution을 사용하면 feature map 커지는 것을 알게 되었을 것이다. 이를 bilinear interpolation을 통해 feature map을 확장하는 것이다.
atrous filter의 계산 방법
보통 우리가 DCNN에서 사용하는 kernel의 크기는 3x3이다. 이는 포함된 매개변수의 계산과 파라미터 수를 유지하기 위해 DCNN에서 자주 사용한다. atrous filter size는 rate parameter = 2 라면 그들 사이에 r - 1에 0을 넣는 방식을 취한다.
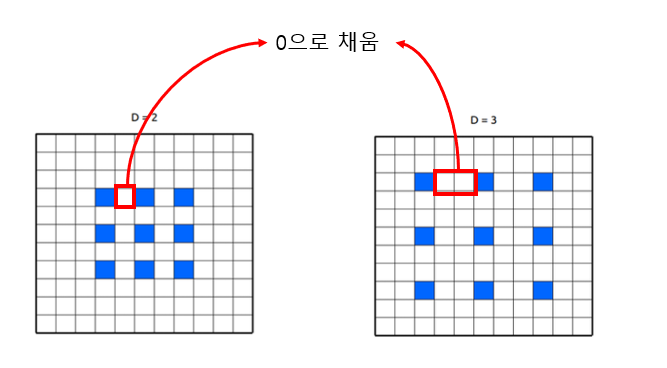 파란색 pixel사이에 흰색 부분에 0이 들어간다고 생각하면 된다. 여기서 rate parameter = 2라면 r = 2이기 때문에, r - 1 = 2 - 1 = 1로 계산되어 파란색 pixel 다음 1칸에 0을 넣는 것이다. 만약 rate parameter = 3이라면 r - 1 = 3 - 1 = 2로 계산되어 파란색 pixel 다음 1칸과 2칸에 0으로 채운다. 이를 수식으로 표현하면 다음과 같다.
파란색 pixel사이에 흰색 부분에 0이 들어간다고 생각하면 된다. 여기서 rate parameter = 2라면 r = 2이기 때문에, r - 1 = 2 - 1 = 1로 계산되어 파란색 pixel 다음 1칸에 0을 넣는 것이다. 만약 rate parameter = 3이라면 r - 1 = 3 - 1 = 2로 계산되어 파란색 pixel 다음 1칸과 2칸에 0으로 채운다. 이를 수식으로 표현하면 다음과 같다.
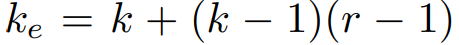 여기서 k는 kernel size로 일반적으로 우리가 kernel size를 3 x 3으로 두었다면 k에 3을 넣고 계산하면 된다.
여기서 k는 kernel size로 일반적으로 우리가 kernel size를 3 x 3으로 두었다면 k에 3을 넣고 계산하면 된다.
그들은 rate parameter = 12까지 했음에도 성공적인 performance를 얻었다고 한다.
atrous filter의 효율적인 사용법
- kerneal에 hole을 추가하여 feature map을 샘플링 (지금까지 위에서 설명한 방식)
- input feature map을 rate parameter만큼 sub sampling
- r^2만큼 감소된 resolution을 얻기 위해 deinterlacing
- 중간 feature map에 표준 컨볼루션을 적용해 원래 이미지 해상도로 reinterlacing
deinterlacing 이란 : interlaced image를 deinterlacing으로 바꿔 화질을 개선한 것
interlaced image 란 : 텔레비전과 같은 영상체널에 아날로그 BW를 높이지 않고 표시할 영상 품질을 개선하기 위한 방식으로 홀수줄, 짝수줄을 번갈아서 출력하는 개념
(자세한 내용 https://jlog1016.tistory.com/86 참고 )
본 논문에서는 atrous convolution에 적용하기 위해 input feature map을 각 구역에 따라 sub sampling했다는 뜻으로 deinterlacing이란 용어를 사용한 것 같다고 한다.
[출처] https://blog.naver.com/cococindy98/222438687587
2.2 Multiscale Image Representations using Atrous Spatial Pyramid Pooling
이 과정은 Semantic Segmentation에서 이미지 규모의 다양성을 다루기 위해 제시된 2가지 방법이다.
-
동일한 parameter을 공유하는 병렬 DCNN 분기를 사용하여 원본 이미지의 여러 크기에서 DCNN score map을 추출한다. 최종 결과를 생성하기 위해서 병렬 DCNN 분기에서 원래 이미지 해상도로 upsampling하기 위해 bilinear interpolation을 적용하고 각 위치에서 서로 다른 scale에서 최대 응답을 취하여 융합한다.
-
R-CNN의 spatial pyramid pooling 방식에 영감을 받음. (이는 임의의 규모에 대해 정확도와 분류가 뛰어난 방식이다.) 이와 같은 비슷한 방식으로 rate parameter가 다른 여러개의 atrous convolution을 적용한다. 여기서 나온 각각의 feature 들은 각각의 분기들에 의해 융합되어 결과로 출력된다.
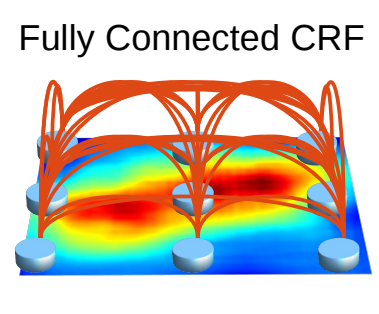
2.3 Structured Prediction with Fully-Connected Conditional Random Fields for Accurate Boundary Recovery
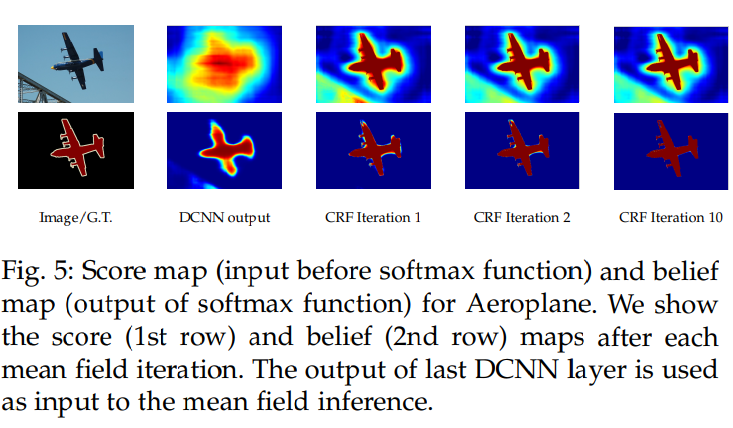
왜 CRF가 필요한가?
Semantic Segmentation은 픽셀 단위의 조밀한 예측이 필요한데, classification을 기반으로 segmentation을 구성하게 되면 계속 feature map의 크기가 줄어들기 때문에 detail한 정보를 얻을 수가 없다. 이러한 문제로 인해 FCN에서는 skip connection 방식을 채택하여 사용하였고 Deeplab에서는 마지막 pooling layer2개를 없애고 atrous convolution방식을 사용하였다.(기억안나면 다시 위를 참고!)
하지만 이러한 방식을 사용하여도 한계는 존재하기 때문에, Deeplab에서는 atrous convolution만의 방식 뿐만 아니라 CRF(Conditional random field)를 후처리 과정으로 사용하여 픽셀 단위 예측의 정확도를 더 높일 수 있게 되었다. 쉽게 말해서 이 방법은 인접 노드를 결합하여 공간적으로 근접한 픽셀에 동일한 레이블을 할당하는 것이다.
Fully connected CRF 에 관한 내용
http://swoh.web.engr.illinois.edu/courses/IE598/handout/fall2016_slide15.pdf
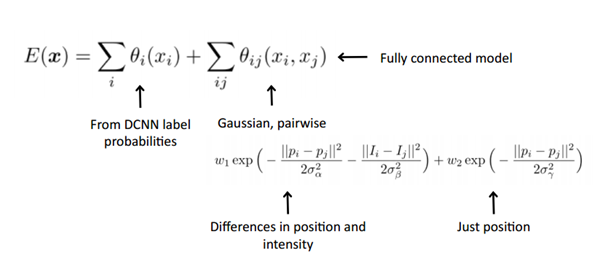 위 CRF 수식을 보면, 2개의 가우시안 커널로 구성이 된 것을 알 수 있으며, 표준편차 σα, σβ, σγ를 통해 scale을 조절할 수 있다. 첫번째 가우시안 커널은 비슷한 위치 비슷한 컬러를 갖는 픽셀들에 대하여 비슷한 label이 붙을 수 있도록 해주고, 두번째 가우시안 커널은 원래 픽셀의 근접도에 따라 smooth 수준을 결정한다. 위 식에서 pi, pj는 픽셀의 위치(position)를 나타내고, Ii, Ij는 픽셀의 컬러값(intensity)이다.
위 CRF 수식을 보면, 2개의 가우시안 커널로 구성이 된 것을 알 수 있으며, 표준편차 σα, σβ, σγ를 통해 scale을 조절할 수 있다. 첫번째 가우시안 커널은 비슷한 위치 비슷한 컬러를 갖는 픽셀들에 대하여 비슷한 label이 붙을 수 있도록 해주고, 두번째 가우시안 커널은 원래 픽셀의 근접도에 따라 smooth 수준을 결정한다. 위 식에서 pi, pj는 픽셀의 위치(position)를 나타내고, Ii, Ij는 픽셀의 컬러값(intensity)이다.
이것을 고속을 처리하기 위해, Philipp Krahenbuhl 방식을 사용하게 되면 feature space에서는 Gaussian convolution으로 표현을 할 수 있게 되어 고속 연산이 가능해진다.
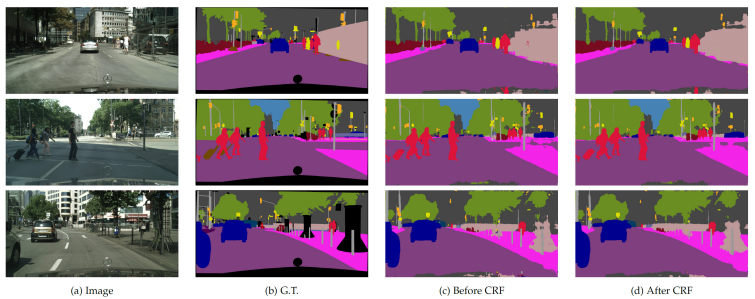
Deeplab의 동작 방식
CRF까지 적용된 Deeplab의 최종적인 동작방식은 다음과 같다.
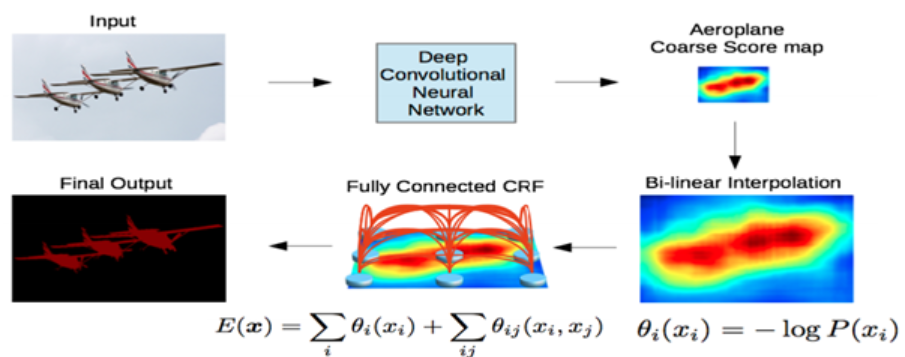 DCNN을 통해 1/8 크기의 coarse score-map을 구하고, 이것을 Bilinear interpolation을 통해 원영상 크기로 확대를 시킨다. Bilinear interpolation을 통해 얻어진 결과는 각 픽셀 위치에서의 label에 대한 확률이 되며 이것은 CRF의 unary term에 해당이 된다. 최종적으로 모든 픽셀 위치에서 pairwise term까지 고려한 CRF 후보정 작업을 해주면 최종적인 출력 결과를 얻을 수 있다.
DCNN을 통해 1/8 크기의 coarse score-map을 구하고, 이것을 Bilinear interpolation을 통해 원영상 크기로 확대를 시킨다. Bilinear interpolation을 통해 얻어진 결과는 각 픽셀 위치에서의 label에 대한 확률이 되며 이것은 CRF의 unary term에 해당이 된다. 최종적으로 모든 픽셀 위치에서 pairwise term까지 고려한 CRF 후보정 작업을 해주면 최종적인 출력 결과를 얻을 수 있다.
