 원본 이미지에 여러개의 Object가 있는 것이 아니라 하나의 Object만 있다면 좀더 좋은 결과를 얻을 수 있는 것은 명확하다.
원본 이미지에 여러개의 Object가 있는 것이 아니라 하나의 Object만 있다면 좀더 좋은 결과를 얻을 수 있는 것은 명확하다.
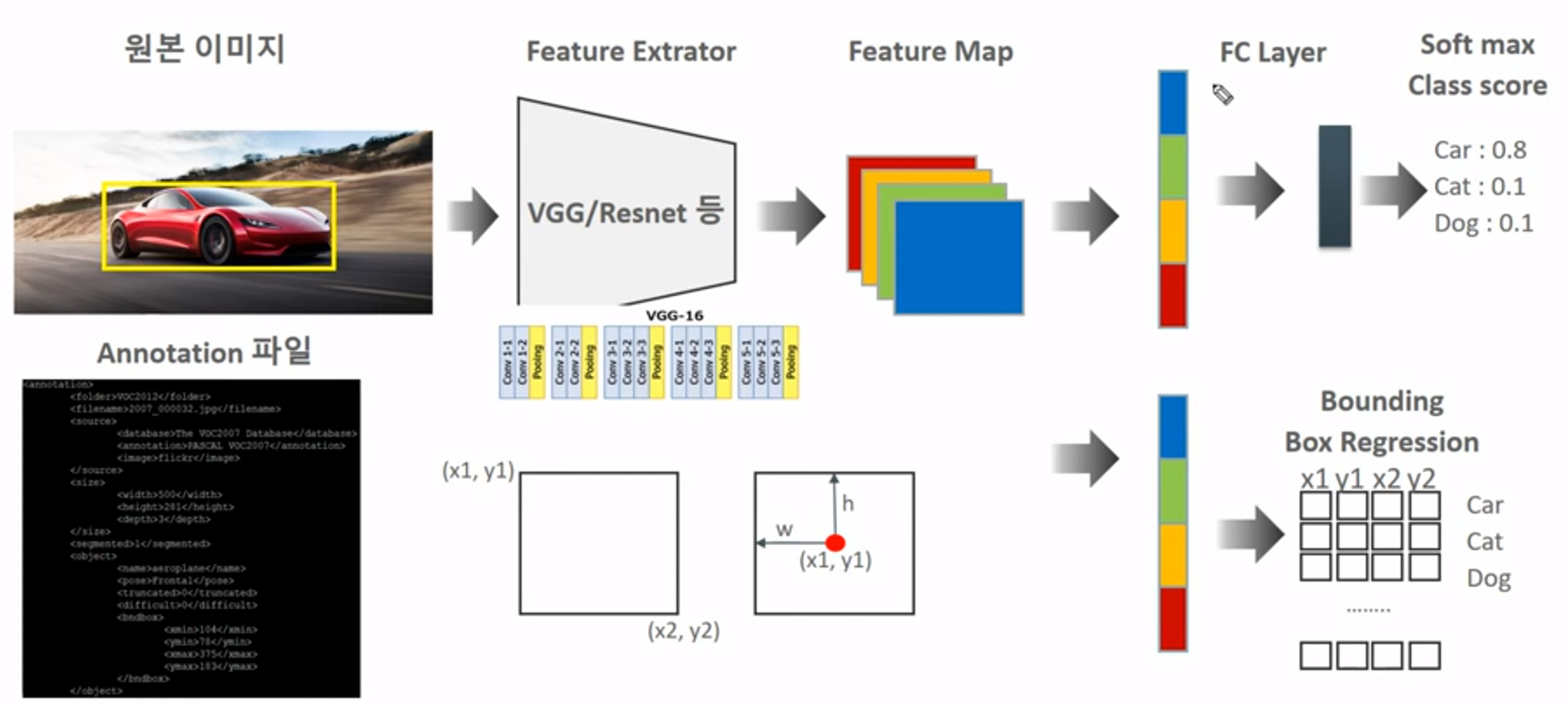
일반적으로 Classification만 진행한다면 위의 sequence만 진행하게 될 것이다. 하지만, Object localization에서는 아래의 sequence도 진행해야 한다.
원본 이미지에서 초기 학습에서는 object의 bounding box인 경우에는  그림처럼 bounding box가 object에 멀게 형성되는 경우도 있지만, 이 또한, backbone을 통해 학습을 진행하면서 점점 object에 가깝게 형성되는 것을 볼 수 있다.
그림처럼 bounding box가 object에 멀게 형성되는 경우도 있지만, 이 또한, backbone을 통해 학습을 진행하면서 점점 object에 가깝게 형성되는 것을 볼 수 있다.
첫 그림을 다시 확인해보면 Bounding box Regression 부분에서 x1, x2, y1, y2의 좌표값이 나오게 되는데, 이것이 학습이 되면서 weight가 update되며 object에 맞게 형성되는 것을 알 수 있다.
앞서 보았듯이, 우리는 Object Localization에 대해 알 수 있었다. 하지만 이것만 하면 Object Detetction에서 문제가 발생한다. 위의 원본 이미지 처럼 하나의 Object만 있으면 문제가 없지만, 여러개의 Object가 있을 경우에는 문제가 발생한다. bounding box만 주고 해당되는 여러 개의 Object에서 학습을 진행하면 결국엔 엉뚱한데에 bounding box를 치는 문제가 발생한다. 따라서 저번에 말했듯이, Region proposal을 통해 해당 Object가 어디에 위치해 있는지 hint를 주고 학습을 진행해야 원하는 결과가 나오는 것이다.
Region Proposal(영역 추정)의 이해와 슬라이딩 윈도우와의 비교
Sliding Window
예전에 Sliding window 방식을 자세하게 설명했었으나, 다시 한번 상기시켜보자.
Sliding window를 해석하면 미끄러지는 window로 보면된다. 즉 왼쪽 상단에서 오른쪽 하단으로 이동하면서 Object를 detection하는 방식이라고 생각하면 된다. 방법은 두가지가 있는데, 1) 다양한 형태의 window를 각각 sliding 시키는 방식이다. 2) window scale은 고정하고 scale을 변경한 여러 이미지를 사용하는 방식이다.
이 방식은 Object Detection의 초기 기법으로 사용되었다. 오브젝트 없는 영역도 무조건 슬라이딩을 하는 방식이며 여러 형태의 window와 여러 scale을 가진 이미지를 스캔해서 검출해야 하므로 수행시간이 오래 걸리고 검출 성능이 상대적으로 낮다. 실시간 Object detection에서는 매우 치명적이다.
Region Proposal(영역 추정) 방식
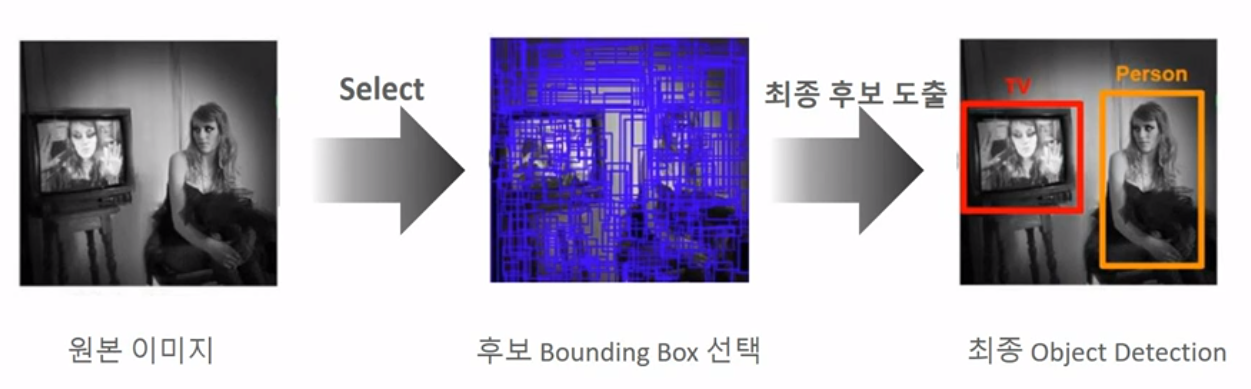
위에 설명했던 Sliding window 방식 같은 경우에는 좋은 방법이 아니다. 그 이유는 위에 설명했었다. 그럼 어떤 방법을 사용하면 좋을까?
위의 그림을 잠시 보면 사람과 티비가 있는 것을 볼 수 있다. 우선 사람을 먼저 보자. 사람은 뒤의 background와 달리 다른 픽셀 값을 갖는다.음.. background와 다른 무늬, 윤곽선, 조도 등에 의해 기존의 background와 다른 값을 갖게 된다. 이를 Selective Search라는 알고리즘 기법을 통해 Object가 있을 만한 후보 영역을 찾게 되는 것이다.

Selective Search 방식을 잠시 보게 되면, 다음과 같다. 원본 이미지에서 최조 Segmentation을 진행한다.
- 빠른 Detection과 높은 Recall 예측 성능을 동시에 만족하는 알고리즘
- 컬러, 무늬, 크기, 형태에 따라 유사한 Region을 계층적 그룹핑 방법으로 계산
- Selective Search는 최초에는 Pixel Intensity를 기반한 graph-based segment 기법에 따라 Over Segmentation을 수행한다.
Over Segmentation을 통해 bounding box를 만들어 낸다. 이렇게 하여 후보 objects bounding box를 우선 검출한다. 근데 이렇게 되면 너무 많이 검출되는 문제가 발생하는데, 이를 해결하는 것이 계측적 그룹핑 방법으로 합친다.
유사한 Region을 계층적 그룹핑 방법으로 계산한다. 
즉, 비슷한 부분을 계속 합쳐서 segmentation을 그룹핑하는 것이다.
이러한 방법이 Selective Search 알고리즘이다.
Object Detection 성능 평가 Metric - IOU
https://velog.io/@joon10266/Objection-Detection-mAP%EB%9E%80
IOU 관련해서 따로 정리한 글이 있는데, 요약하자면 다음과 같다.
ground truth bounding box와 predicted bounding box의 차이가 얼마나 나냐가 포인트이다. 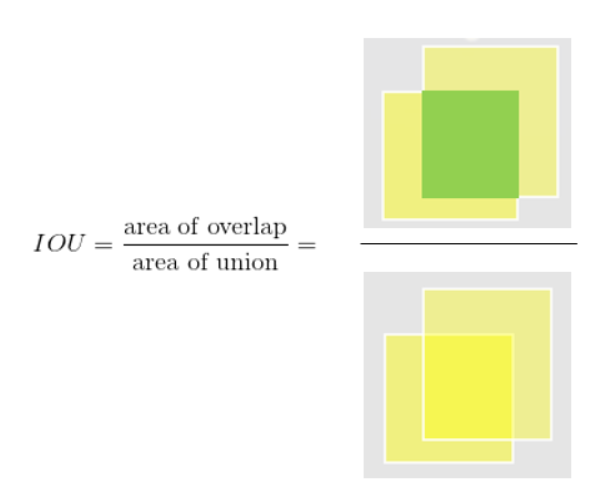 전체 bounding box의 합집합과 교집합에 대한 값이다.
전체 bounding box의 합집합과 교집합에 대한 값이다.
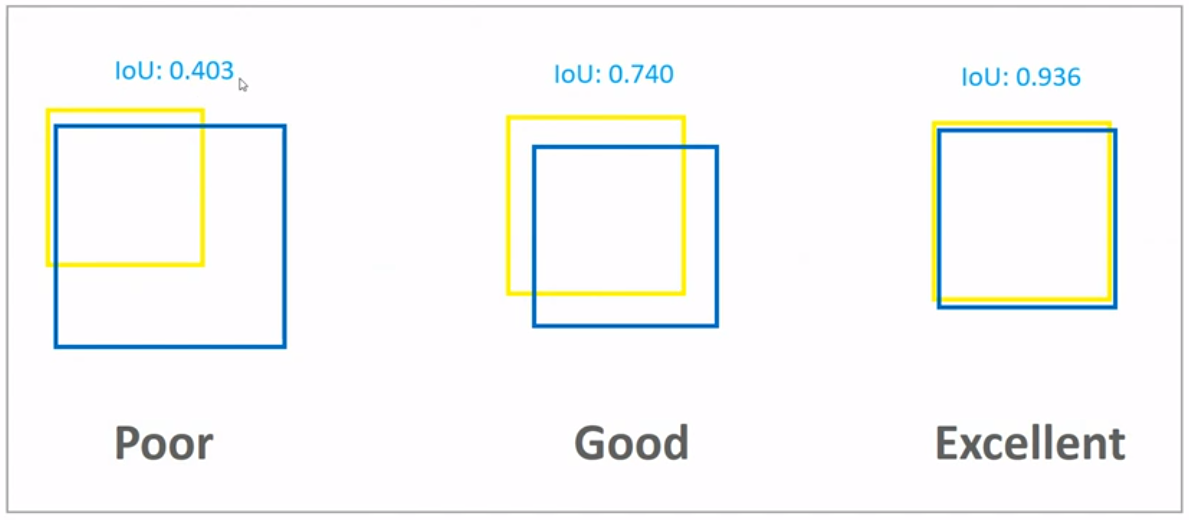
IOU score는 user마다 상대적이므로 정확한 Metric은 아니지만, 얼추 이렇다 보면 된다.
Pascal VOC dataset에서 IOU가 0.5보다 작으면 제대로 detect하지 못했다라고 평가를 한다. IOU가 0.7보다 높으면 어느정도 detect되었다고 평가한다.
MSCOCO같은 경우도 비슷하다.
NMS(Non Max Suppression)에 대해 알아보자

그림을 보면 알듯이 NMS를 거치고 나면 detect한 object 주위의 비슷한 여러 개의 bounding box가 사라지고 하나의 bounding box만 나오는 것을 볼 수 있다.
근데 여기서 의문점이 드는 것이 하나 있다. 왜 여러개의 bounding box가 나오는 것인가? 즉, 왜 object를 detect하는데, 여러 개를 detect하냐는 의문이 들 수 있다.
- object detection 알고리즘은 그러한 특성을 갖는다. selective search 같은 경우를 보면 정확하게 object가 있는 위치를 반환하는 것이 아니라 object가 있을 만한 곳을 찾아서 반환을 한다. object가 있는 곳을 놓치면 안되기 때문이다.
NMS는 Confident Score Threshold와 IOU Threshold로 구하게 된다. 결론을 먼저 말하면 Confident Score Threshold가 높을수록, IOU Threshold가 낮을 수록 많은 Box가 제거되는 것을 알 수 있다.
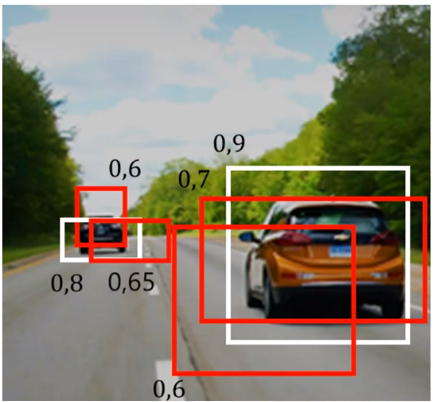
그림과 같이 Confident Score이 구해져 있다고 가정하자. 만약 Confident score Threshold를 0.55 이상으로 설정하면 다음과 같은 Bounding box가 남아 있게 된다. 두개의 object를 detect하는데, 여러개의 bounding box가 있으면 performance가 떨어지므로 이를 IOU Threshold를 통해 조절하는 두번째 방법을 사용한다.
가장 높은 Confidence score를 가진 box 순으로 내림차순 정렬하고 겹쳐있는 Bonding box를 IOU threshold를 통해 제거한다.
예를 들어 IOU Threshold가 0.3으로 설정한다고 가정하자. 0.9로 Confident Score를 갖는 하얀색 박스와 0.6의 Confident Score를 갖는 빨간색 박스의 IOU가 0.3보다 크다면 0.6의 Confident Score를 갖는 빨간색 박스는 제거된다. 이러한 과정을 통해 한 개의 Bounding box를 갖게 된다.
