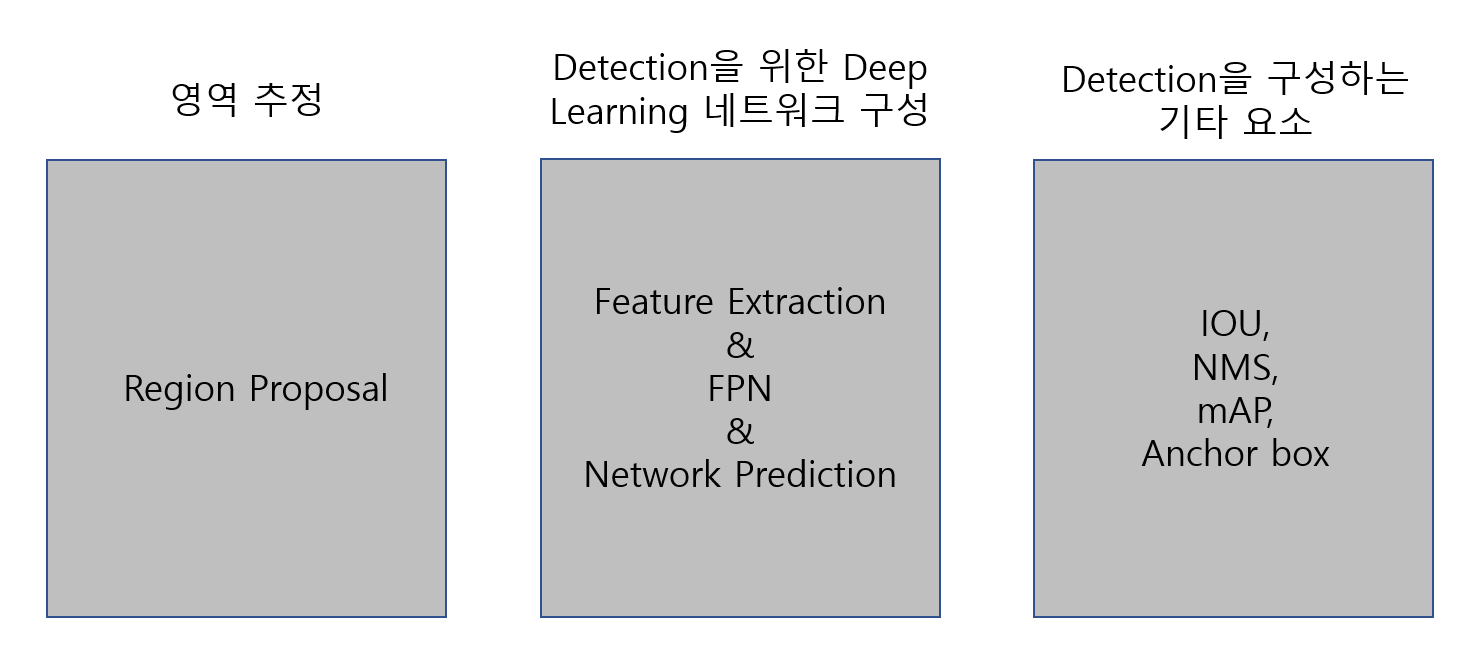
영역 추정에는 Region Proposal이 있다.
Detection을 위한 Deep Learning 네트워크 구성을 살펴보면 다양한 것들이 있다. 우선 Feature Extraction + classification layer를 합쳐서 물체를 분류하는 역할을 한다. Feature Extraction을 다른 말로 Backbone이라 하기도 한다. (Backbone은 YOLO에서 자주 사용하는 Darknet도 있으며, Resnet, VGGNet등이 있다.)
Network Prediction을 보면 classification을 하기도 하며, regression 역할도 하기도 한다. FPN은 Feature Extraction과 Network Prediction을 연결해주는 Neck라 하기도 하며, Network Prediction을 Head라고 부르기도 한다.
Detection을 구성하는 요소에서는 IOU, NMS, mAP, Anchor Box등이 있는데, 이는 추후에 자세하게 설명하도록 하겠다.
우선 하나의 이미지가 있다고 가정을 하자.
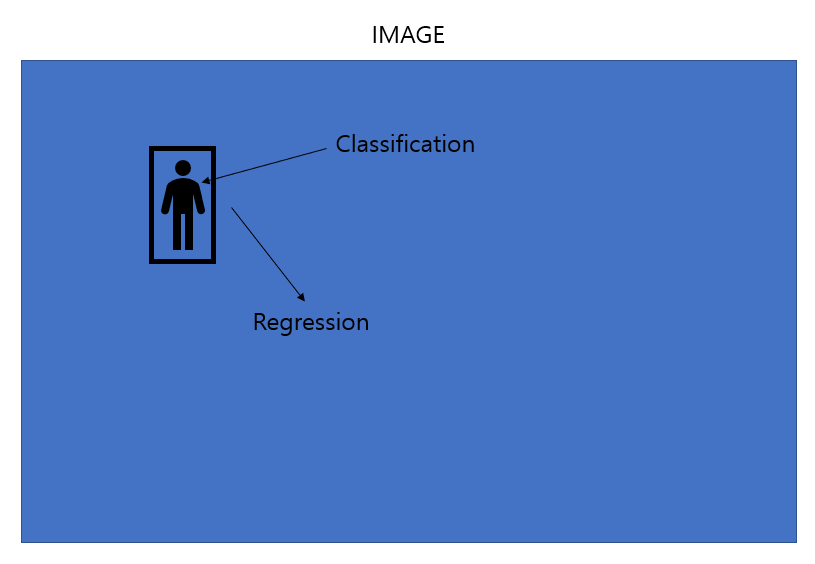 이미지 안의 object bounding box는 regression을 통해 찾아내고, bounding box의 내부는 Classification을 통해 찾아낸다.
이미지 안의 object bounding box는 regression을 통해 찾아내고, bounding box의 내부는 Classification을 통해 찾아낸다.
과거에는 딥러닝을 통해 object 위치를 주지 않고 bounding box만 주고 학습을 시켰으나, loss만 커지고 제대로 학습되지 않는 상황이 발생하였다. 적어도 object 위치의 hint는 주어야 한다는 점에서 Region Proposal이 쓰인다.
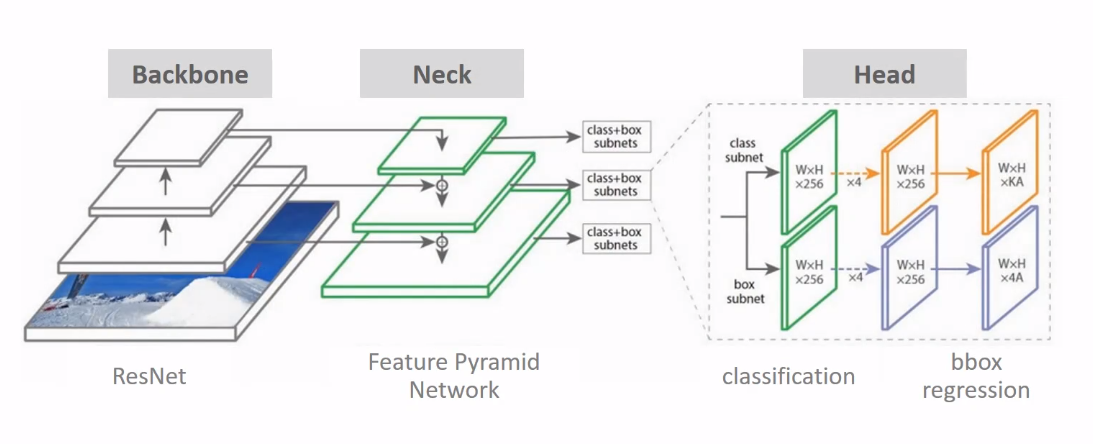
Resnet은 Feature Extraction이므로 Backbone에 해당한다. object detector는 Deep Conv이므로 보통 점점 깊어질수록 downsampling 과정을 통해 작아지게 되어 작은 물체를 탐지하게 되는 문제가 발생한다. Neck가 없을때에는 이런 작은 물체에 대한 정보로만 학습을 하게 되었으나, Neck 역할을 하는 Feature Pyramid Network를 통해 좀더 체계적으로 학습을 할 수 있게 되었다. Head 부분에서는 윗 부분이 class에 대한 분류, 아랫부분이 좌표에 대한 regression이 진행된다.
Object Detection이 일반적인 image Classification보다 어려운 이유는 classification만 하는 것 뿐만 아니라 Regression과 loss, detect 시간, 다양한 크기의 유형, 명확하지 않은 이미지, 데이터 세트의 부족등에 의해 어려운 점이 많다.
참고자료: [개정판] 딥러닝 컴퓨터 비전의 완벽 가이드 - 권철민
