본격적으로 YOLOv1에 대해 논문 리뷰를 시작하도록 하겠다. 잠깐만! 시작하기 전에 YOLO의 full name부터 보고 가자. YOLO = You Only Look Once (넌 오직 한번만 본다) 귀여운 제목이다. 각설하고 시작하자.
YOLO paper : https://arxiv.org/pdf/1506.02640.pdf
1. Abstract
YOLOv1이 나오기 시작할 땐 2015년이다. 그 전에는 2-stage 방식인 R-CNN, Fast R-CNN이 있었다. YOLO는 2-stage 방식이 아니라 1-stage 방식으로 전체적인 Detection pipeline이 단순한 Network 구조로 되어있다. 하나의 Network 구조로 되어 있어 end-to-end 방식을 사용할 수 있고 detection performance에도 탁월하다.
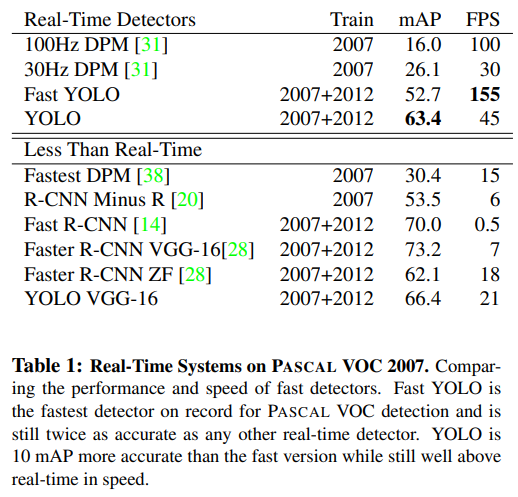
YOLO의 장점은 속도에도 있는데, 다른 detector model에 비해 mAP도 2배가량 높기도 하다. 155 frame 까지 나온다고 하는데, 파이썬으론 불가능하고 C++로는 가능하다고 한다.
(mAP가 뭔지 모른다고? https://velog.io/@joon10266/Objection-Detection-mAP%EB%9E%80 참고하라!)
또한, YOLO는 localization error을 더 많이 발생시키지만 틀린 검출을 할 가능성은 적다고 한다.
2. Introduction
인간의 눈은 매우 빠르고 정확하며 운전과 같은 복잡한 업무도 해낼 수 있다. R-CNN과 Fast R-CNN같은 경우에 detection을 수행할 때 classifier를 사용한다. 이때 균일한 간격으로 실행하는 sliding window를 사용하는 DPM도 있다. 우선 YOLO와 차별점을 가장 많이 두는 2-stage인 R-CNN을 알아보자
잠시 R-CNN의 방식을 살펴보자.
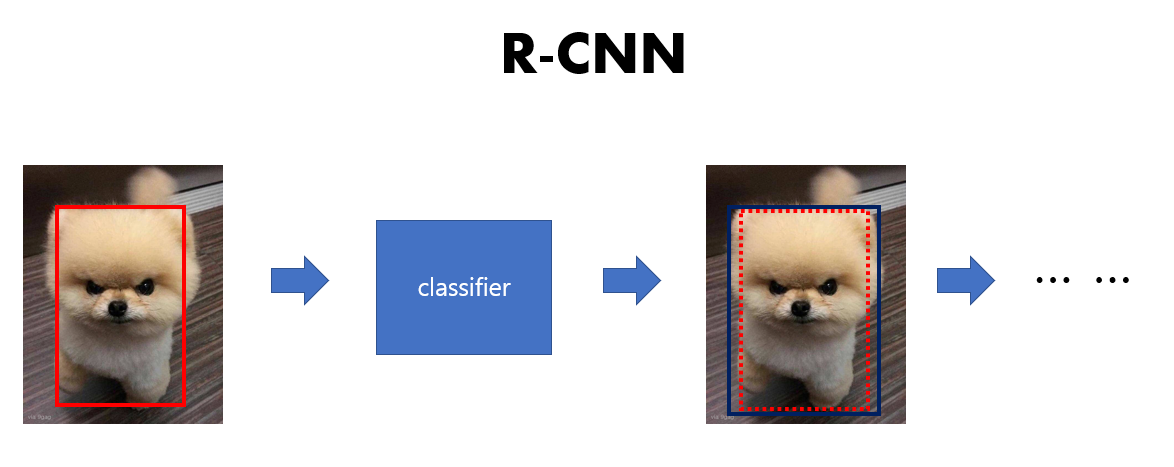
과정을 살펴보기 전에 그림에 그려진 bounding box는 sliding window가 아니라 region proposal을 거쳐 나온 것중에 IoU가 높은 것들만 나온 bounding box이다. 이에 대해선 mAP 리뷰에 대해 보고 오면 좀더 이해하기가 수월할 것이다.
1. region proposal method을 사용하여 potential bounding box를 그린다.
2. classifier에 potential bounding box를 run한다.
3. 1,2과정 후에 bounding box를 수정하고 중복 detection을 제거하며 다른 object를 찾아 rescore를 매긴다.
이 과정들이 계속 반복되는 것이다. 하지만 이 method는 매우 복잡한 pipeline이며 느리고 각각의 요소들을 부분적으로 훈련시켜야만 해서 최적화하기가 매우 까다롭다. (정확도가 높다고 장땡이 아니다. 높은 frames에도 높은 정확도가 나와야 하지만 R-CNN과 Fast R-CNN은 그렇지 못하다.)
그러면 YOLO는 어떤식일까?
연구자들은 말한다.
"We frame object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities."
자신들은 객체 감지를 이미지에서 bounding box 좌표 및 class 확률까지 단일 회귀 문제로 생각한다. 이 말이 뭔지 모르는게 당연하다 아직 본론에 대한 내용은 하나도 없으니 차근차근 알아보자.

그들은 single convolutional network로 동시에 여러개의 bounding box와 class 확률도 예측한다고 한다. 또한 YOLO가 다른 object detection에 비해 몇개의 benefits가 있다고 한다. 하나씩 보자.
1. YOLO is extremely fast. (YOLO는 매우 빠르다.)
- paper을 보면 다른 model과 비교하여 YOLO가 어떤 performance를 내었는지 비교하고 있다.
- real-time에서 다른 모델들에 비해 mAP가 두배 이상 나왔다고 한다.
2.YOLO reasons globally about the image when making predictions.
->(YOLO는 예측을 할때 이미지에 대해서 전체적으로 추론한다.)
- 2-stage 방식은 sliding window와 region proposal방식을 사용한다.(아까도 말했듯이 느리다.ㅜㅜ)
- 1-stage 방식인 YOLO는 Implicity encodes contextual information이라 기술한다. 즉, 암묵적으로 문맥적인 정보를 변형한다는 것인데 이는 본론을 살펴봐야 제대로 이해할 수 있을 것이다.
- Fast R-CNN의 경우 background patches에서 실수를 발생한다고 한다. 즉, 배경을 객체로 인식하는 실수를 하게 된다.(selective search의 한계) 하지만 YOLO는 이미지 전체를 이용하여 class와 객체 출현에 대한 contextual information까지 이용할 수 있다.
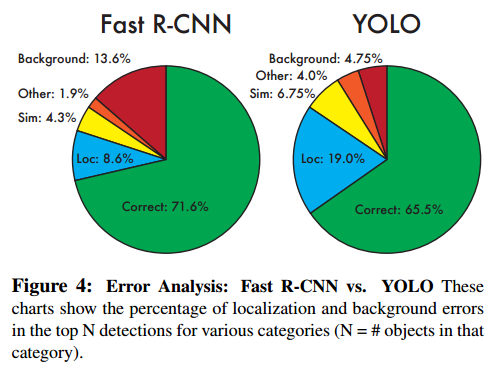
3. YOLO learns generalizable representations of objects. (YOLO는 객체의 일반화할수 있는 표현을 학습한다.)
- 특징있는 부분만 추출하여 학습하는 것이 아닌 일반화할 수 있는 표현도 학습할 수 있다.(물론 진짜 이상한 것들 말고 어느정도 상식선에서 말이다.)
- 그렇다 보니 new domain 및 unexpected input이 들어와도 잘 대응한다.
3. Unified Detection
"We unify the separate components of object detection into a single neural network"
이 말은 즉슨, complex pipline 구조가 아닌 single neural network 구조로 unify했다는 뜻이다.
- 자신들의 network는 전체 이미지의 특징을 사용하여 각각의 bounding box를 예측한다.
- 이미지에 대한 모든 class의 모든 bounding box를 동시에 예측한다.
위의 방법들은 결국 처음에 말했던 YOLO가 이미지안의 모든 객체와 이미지를 전체적으로 추론한다는 것을 뒷받쳐준다. (기억이 안난다면 2.Introduction부분의 benefits 2번을 확인해보자.)

1. input 이미지를 S x S grid에 투영한다.
2. object의 중심이 grid cell에 있으면 그 grid cell은 obejcet를 탐지한다.
3. 각 grid cell은 B개의 bounding box와 그 bounding box의 confidence score를 예측한다.
https://velog.io/@joon10266/Objection-Detection-mAP%EB%9E%80
뒤에 나올 IoU와 confidence score에 대해 설명했습니다. 꼭 봐주세요 ㅠ.. 안보시면 이해 못합니다. 이에 confidence score는 설명하지 않겠습니다.
4. 각 bounding box는 5개의 예측값들로 구성되어 있다. x, y, w, h 와 confidence로 구성되어 있다.
(x, y)는 bounding box의 중심점이다. w와 h는 width와 height의 약어이며 전체 이미지에 상대적인 값이다. confidence는 예측된 bounding box와 진짜 박스 사이의 IoU이다.
5. 각 grid cell들은 class 확률을 예측한다.
즉, grid cell들은 bounding box에도 영향을 미치고 class 확률에도 영향을 미친다.
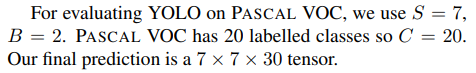 예측값은 (S x S x (B * 5 + C)) 크기의 tensor를 갖는다. 논문에서는 7 X 7 X 30 tensor를 갖는다.
예측값은 (S x S x (B * 5 + C)) 크기의 tensor를 갖는다. 논문에서는 7 X 7 X 30 tensor를 갖는다.
6. non-max suppression을 거쳐서 최종 bounding box를 select한다.
(이 부분은 뒤에 나옵니다. Introduction의 YOLO 그림을 보면 3번에 명시되어 있습니다.)
3.1 Network Design
조만간 GoogleNet에 대한 논문 리뷰도 해야겠다. 생각보다 많이 나오네 ㅠㅠ,,,,

위는 YOLO를 구현하기 위한 Network이다. YOLO 연구자들은 이미지 분류를 위한 GoogleNet에 많은 영감을 받았다고 한다.
그들의 Network는 24개의 Convolutional layer와 2개의 fully connected layer가 있다고 한다. 또한 GoogleNet에 사용한 inception model 대신 1 x 1 convolution layer을 사용한단다. (1 x 1 convolution layer의 역할은 Resnet 논문 리뷰할때 잠시 설명했다. (Resnet 논문 리뷰 https://velog.io/@joon10266/Resnet-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0))
그들은 또한 말한다. fast version의 YOLO는 24개의 convolution layer에서 9개만 사용하여 design하였다고 말이다. 하지만 네트워크의 크기를 줄였다고 해서 모든 훈련 및 테스트 매개변수는 YOLO와 Fast YOLO는 동일하다고 말한다.
결론 : YOLO는 Convolution layer을 통해 features을 추출하고 fully connected layer을 통해 Class의 확률과 Bounding box의 위치(좌표)를 예측한다.
3.2 Training
연구자들은 ImageNet 1000-class competition dataset을 사용하여 pretrain(사전 훈련)하였다. 20개의 Convolution layer와 그 뒤를 잇는 average-pooling과 fully connected layer을 사용하여 (무려 1주동안;;;) 학습시켰다고 한다.그들은 Darknet framework를 사용하여 훈련과 추론을 했다고 한다.(Darknet이 무엇인진 나중에...;)
 그들은 pretrained model에서 4개의 Convolutional layer와 2개의 connected layer을 덧붙여 사용하여 성능을 향상시켰다고 기술한다.
그들은 pretrained model에서 4개의 Convolutional layer와 2개의 connected layer을 덧붙여 사용하여 성능을 향상시켰다고 기술한다.
paper안에 이러한 내용이 기재되어 있는데," Detection often requires fine-grained visual information so we increase the input resolution of the network from 224 × 224 to 448 × 448." 이 말은 탐지를 위해서 해상도를 높였다는 것인데, 이게 뭔가 이해가 안되었다.
내 생각: 굳이 그래야 하나 싶은데 3.1의 Network design 에서의 설명을 보자. 원래 이미지 (448 x 448)에서 절반을 한 (224 x 224) 이미지를 pretrained으로 학습시켰다. 그러다 보니 원본이미지에 맞추기 위해
(448 x 448)로 해상도를 증가시키는 것이 아닐까 생각한다. 논문에서는 탐지를 하는데 있어 미세한 시각정보를 요구함으로써 해상도를 증가한다고 하는데, 본인의 생각은 연구자들의 생각 + 원본 이미지에 맞추기 위한(?) 뭐 그런 작업이 아닐까 싶다. 이미지가 크면 클수록 feature을 뽑기는 쉬우나 작은 원본 이미지의 해상도를 의도적으로 늘려서 사용하는 방식이 detection에 도움을 주는지는 아직 잘 이해가 안간다.
마지막 layer는 class의 확률과 bounding box의 좌표를 예측한다. (fully connected layer의 역할)
그들은 bounding box의 너비와 높이를 이미지의 너비와 높이로 정규화 하여 0~1사이가 되도록 한다. (상대적인 기법) bounding box의 x와 y좌표를 특정 grid cell의 offset으로 매개변수화하여 0~1사이의 경계가 되도록 한다.
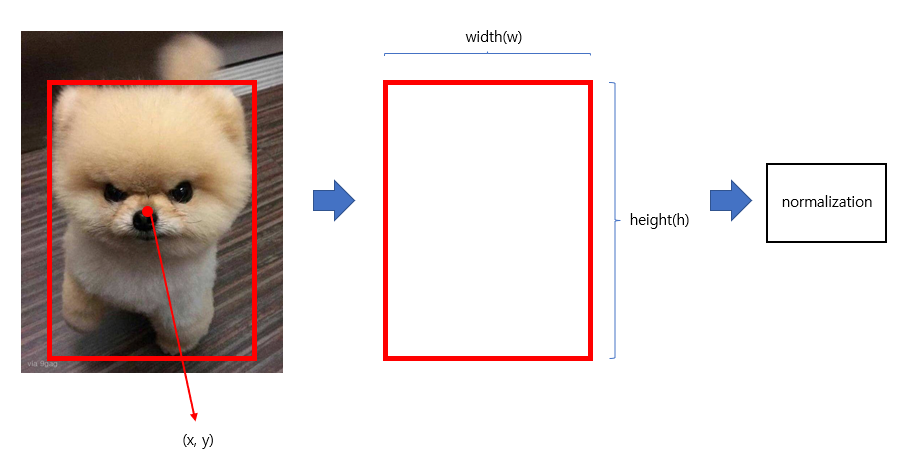 이미지의 크기가 1이라면 그에 맞게 bounding box가 0~1사이에 위치하게 되도록 한다(?).라는 느낌을 가지면 될 듯하다.
이미지의 크기가 1이라면 그에 맞게 bounding box가 0~1사이에 위치하게 되도록 한다(?).라는 느낌을 가지면 될 듯하다.
그들은 마지막 layer에 linear activation function을 넣었고 다른 모든 layer에는 leacky rectified linear activation을 넣었다.

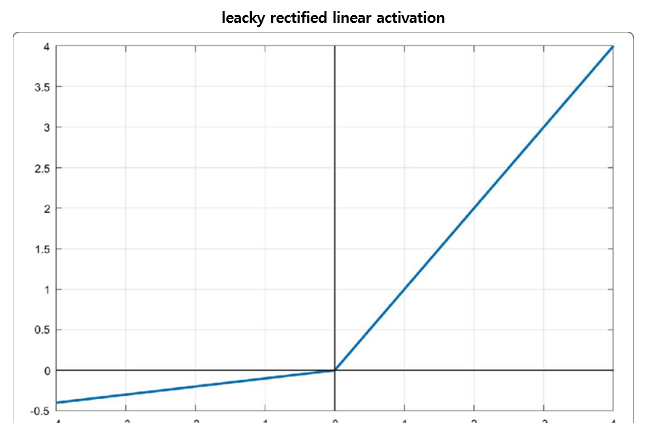
x에 값을 넣어 한번 계산해보라. 그리고 자신이 생각한 값과 graph의 모양이 일치한지 검토하자.
그들은 sum-squared error을 사용하여 optimize하였는데, 이를 사용한 이유는 optimzie하기 쉬워서라고 한다. 그들이 생각한 최대치의 mAP에는 도달하지 못했지만 말이다. 도달하지 못한 이유는 분류 오류처럼 현지화 오류를 가중시킨다고 한다.
 그림에 grid cell을 투영시켰다고 가정해보자. 강아지와 나비에 대한 객체를 담당하는 grid cell은 총 8개 정도이고 나머지는 거의 객체가 존재하지 않는다. 논문에서는 이러한 부분에 대해 안타까움을 토한다. 객체가 존재하지 않으면 confidence score는 저절로 0에 가까워지고 이 점수가 다른 cell의 gradient를 압도하게 되면 error가 발생하여 모델이 불안정해지고 train도 발산할 수가 있는 것이다.
그림에 grid cell을 투영시켰다고 가정해보자. 강아지와 나비에 대한 객체를 담당하는 grid cell은 총 8개 정도이고 나머지는 거의 객체가 존재하지 않는다. 논문에서는 이러한 부분에 대해 안타까움을 토한다. 객체가 존재하지 않으면 confidence score는 저절로 0에 가까워지고 이 점수가 다른 cell의 gradient를 압도하게 되면 error가 발생하여 모델이 불안정해지고 train도 발산할 수가 있는 것이다.
이를 해결하기 위해 bounding box coordinate predictions의 loss를 늘리고 객체가 포함되지 않는 box들의 confidence predictions를 줄였다고 한다. 이에 두가지 파라미터를 사용하였는데, 그것이 λcoord와 λnoobj를 사용하였고 각각 5와 0.5의 값을 set하였다고 한다.
Sum-squared error은 큰 bounding box,작은 bounding box 상관없이 동등한 weight error를 부여한다고 한다. 큰 bounding box의 작은 error은 작은 bounding box보다 덜 중요하다는 것을 반영해야 하므로 이 문제를 bounding box의 너비와 높이로만 해결하는 것이 아니라 bounding box의 너비와 높이의 제곱근으로 예측하게 만든다.
Sum-squared error의 한계
1. localization error 가중!
2. 동등한 weight error 부여!
YOLO는 grid cell당 여러개의 bounding box를 예측한다. 훈련 도중에 각 객체에서 가장 높은 예측을 하는 bounding box를 예측해야 하므로 이때는 Iou와 ground truth를 사용하여 가장 높은 우선위를 가지는 bounding box가 나오게 된다.
이제 다 끝나가는데 끝내기 전에 논문에 나오는 Loss function을 한번 확인해보자.
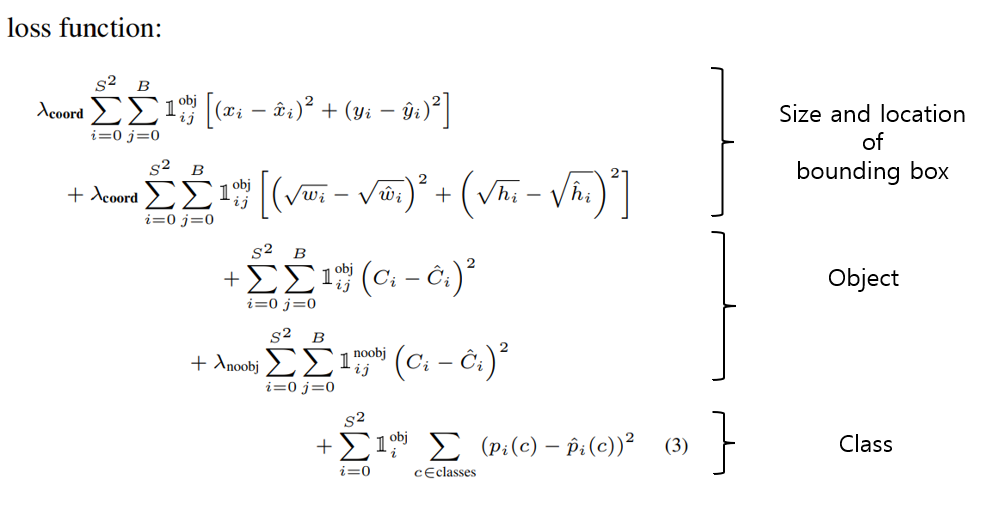 x와 y는 bounding box의 좌표라고 생각하면 되겠다.
x와 y는 bounding box의 좌표라고 생각하면 되겠다. 뭔가 식이 MSE 비슷한 느낌이 든다고..


velog 수식 어떻게 집어 넣는거지(어리둥절);;;;;;;;
하여튼 여기까지 이해하면 YOLOv1에 대한 전반적인 이해는 끝이 난다. 그 뒤로는 YOLO의 한계, 비교 등에 대한 내용이다.
YOLOv1의 한계
1. 각 grid cell은 하나의 클래스만을 예측한다. object가 겹쳐있으면 제대로 예측하지 못한다.
2. bounding box 형태가 data를 통하여 학습되므로, 새롭고 독특한 형태의 바운딩 박스의 경우 정확히 예측하지 못한다.
3. small bounding box의 loss가 IoU에 더 민감하게 영향을 준다. localization에 안좋은 영향을 미친다.
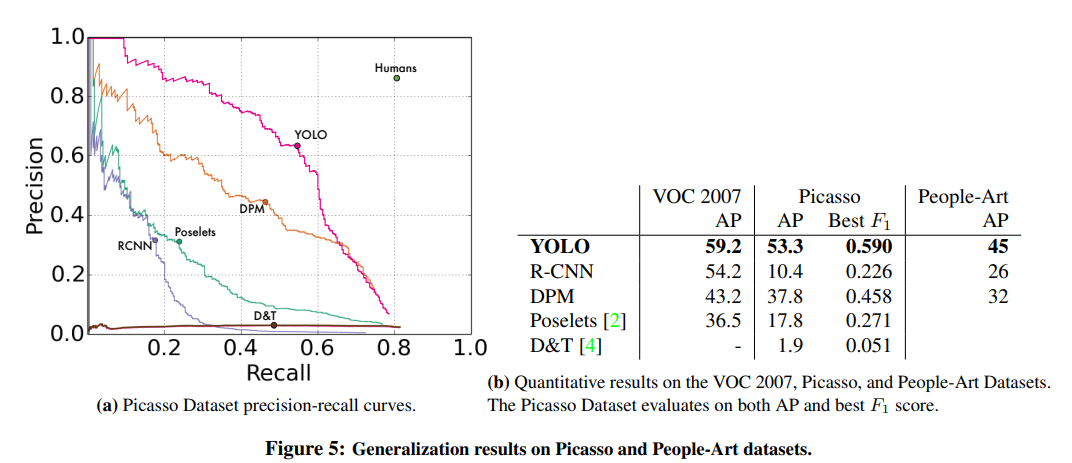
YOLOv1의 성능