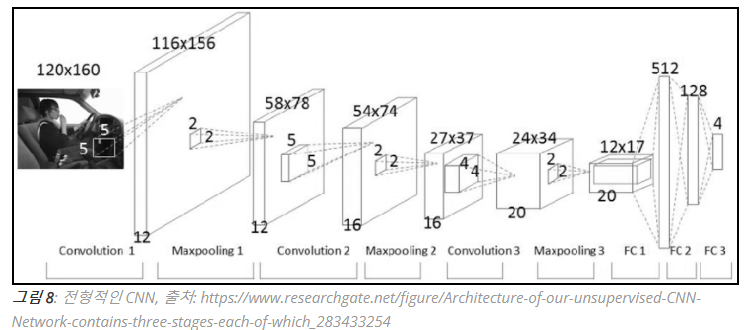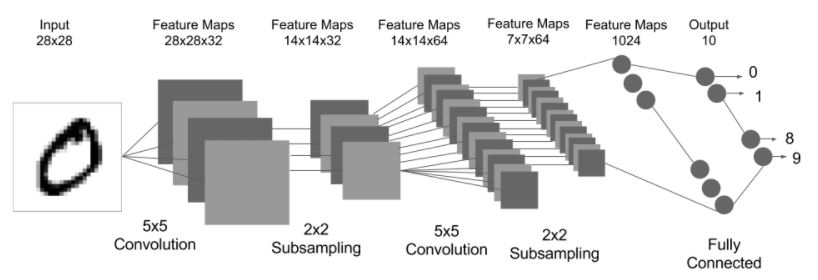
Object Detection을 제대로 알기 위해선 CNN에 대한 기본적인 구조를 정확히 알아야 한다. Convolutionl Network를 응용하여 사용하는 경우가 많기 때문이다.
CNN에 대해 정말 기초적이고 자세하게 설명한 곳은 김태완님의 블로그일 것이다.
http://taewan.kim/post/cnn/
그 과정을 다시한번 짚고 넘어가자.
CNN에는 여러 용어가 있다.
- Convolution (합성곱)
- channel (채널)
- filter (필터)
- kernel (커널)
- stride (보폭)
- padding (패딩)
- feature map (피처맵)
- activation map (활성맵)
- Pooling (풀링)
위 용어들에 대해 자세히 알아보자.
1. Convolution (합성곱)
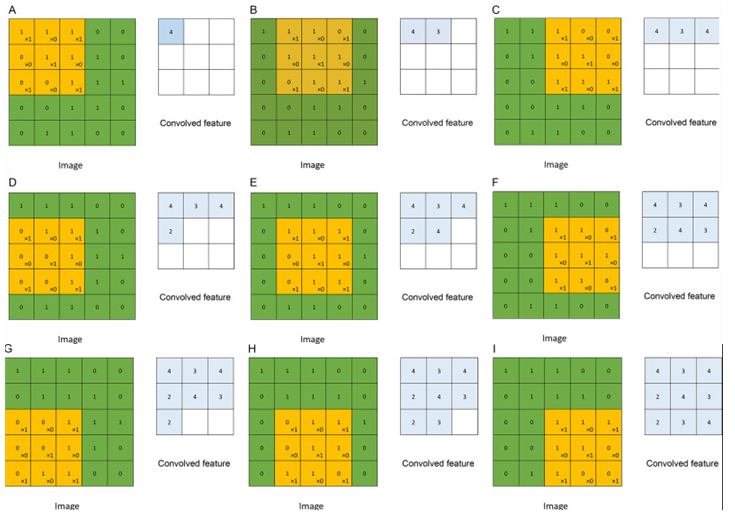
(5 x 5) Data를 (3 x 3) kernel(filter)로 합성곱을 단계적으로 수행하는 과정을 보여준다.
2. Channel (채널)
 image pixel은 실수로 이루어져 있다. 디스플레이 패널을 보면 Red, Green, Blue로 이루어진 아주 작은 LED로 다채로운 색을 만들어 낸다. 이 역시 Color image에서 RGB는 모두 실수로 이루어져 있으며 각각이 합쳐져서 나타난다. Color_image는 Red, Green, Blue를 각각 1개의 channel을 갖고 있으며 총 3개의 channel을 갖는다.(따라서 3차원 데이터라고 불리기도 한다.) 흑과 백으로만 이루어진 grayscale_image는 2차원 데이터로 1개의 channel로 구성된다.
image pixel은 실수로 이루어져 있다. 디스플레이 패널을 보면 Red, Green, Blue로 이루어진 아주 작은 LED로 다채로운 색을 만들어 낸다. 이 역시 Color image에서 RGB는 모두 실수로 이루어져 있으며 각각이 합쳐져서 나타난다. Color_image는 Red, Green, Blue를 각각 1개의 channel을 갖고 있으며 총 3개의 channel을 갖는다.(따라서 3차원 데이터라고 불리기도 한다.) 흑과 백으로만 이루어진 grayscale_image는 2차원 데이터로 1개의 channel로 구성된다.
3.filter (필터) & stride (보폭)
매우 중요한 개념이다. 또한 그렇게 어렵지 않은 CNN에서 제대로 이해를 못하고 넘어가는 학생들이 정말 많은 부분이다. 이번 기회에 제대로 알고 넘어가자.
필터는 이미지의 특징을 찾아내기 위한 공용 파라미터이다. CNN에서 filter는 kernel 로 불린다.
CNN에서 Kernel과 filter는 같은 의미이다.
Convolution에서 보여준 그림을 다시 보자. 한 data에서 filter(kernel)을 단계적으로 합성곱을 사용하여 특징을 추출하는 것을 볼 수 있다. 아래의 그림은 하나의 filter을 사용하여 첫번째 단계를 수행할때, 어떤 식으로 계산하여 feature을 뽑아내는지 알려준다.
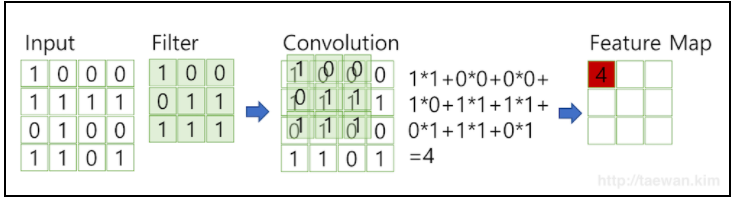 위의 그림을 좀 더 세부적으로 표현하면 다음과 같다.
위의 그림을 좀 더 세부적으로 표현하면 다음과 같다.
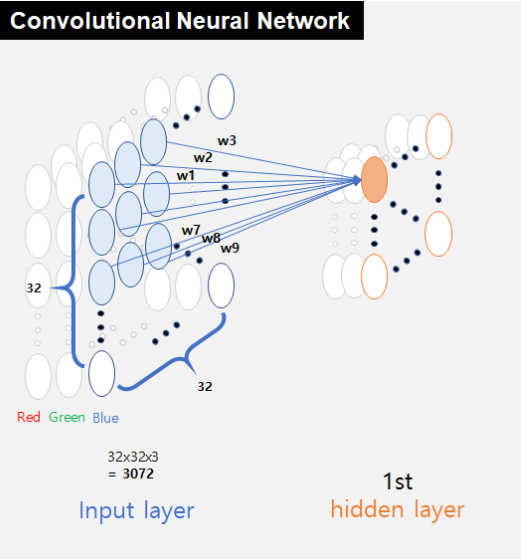 그림 참고 :https://taeu.github.io/cs231n/deeplearning-cs231n-CNN-1/
그림 참고 :https://taeu.github.io/cs231n/deeplearning-cs231n-CNN-1/
우리가 프로그래밍으로 반복적인 계산을 할때, for문을 사용하여 계산하는 방식이 일반적이다. 근데 이는 매우 느리다. 그래서 AI에서는 벡터의 내적 계산을 통해 단점을 극복했다.
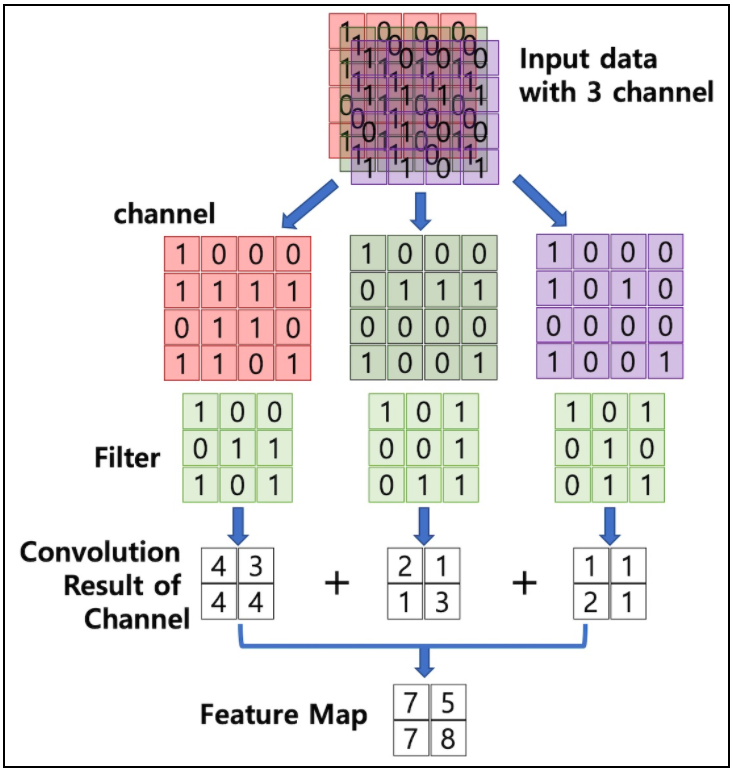 하나의 Convolution layer에 크기가 같은 여러개의 filter을 적용할 수 있다. 이 경우에 feature map은 filter의 갯수만큼 channel이 만들어진다. Convolution layer의 입력 데이터를 filter(kernel)가 순회하며 합성곱을 통해서 만든 출력을 Feature map 또는 Activation Map라고 한다.
하나의 Convolution layer에 크기가 같은 여러개의 filter을 적용할 수 있다. 이 경우에 feature map은 filter의 갯수만큼 channel이 만들어진다. Convolution layer의 입력 데이터를 filter(kernel)가 순회하며 합성곱을 통해서 만든 출력을 Feature map 또는 Activation Map라고 한다.
또 중요한 것은 이 filter values가 어떻게 정해지냐는 건데, 내가 아는 내용을 한번 적어보겠다. 틀리면 말해주세요. 수정하겠습니다.
우선 forward로 진행할때, forwardpropagation을 통해 weight가 정해지고 backpropagation으로 weight가 점점 optimize되어가는 것으로 알고 있다. 따라서 그림을 보게되면 filter values가 0과 1로만 이루어져 있는데, 이는 사실이 아니고 저런식으로 계산한다는 것을 보여주기 위한 과정일 뿐이다. 미분을 통해 weight가 optimize되어 지는 것인데 0과 1로만 이루어진다는 것은 뭔가 이상다고 생각이 들어야 한다. 즉, 만약 weight의 크기가 100이었다면 이를 지속적인 propagation을 통해 optimize하여 결국에는 0에 가깝게 정규분포를 이루게 되는 것이다.
4. Padding (패딩)
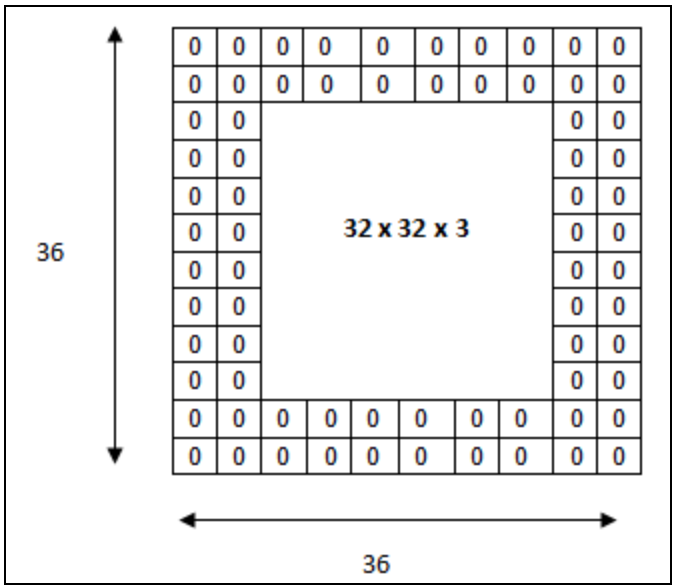 우리가 겨울에 패딩을 입듯이, padding을 사용하면 데이터 주위에 0으로 뒤덮는다. 1-stage인 YOLO는 Network를 진행하기 전에 padding=3을 준다. 그럼 전체 데이터의 크키가 각각 6씩 커진다. 그림의 경우에는 padding=2를 주어 전체적으로 4씩 커지는 과정이다.
우리가 겨울에 패딩을 입듯이, padding을 사용하면 데이터 주위에 0으로 뒤덮는다. 1-stage인 YOLO는 Network를 진행하기 전에 padding=3을 준다. 그럼 전체 데이터의 크키가 각각 6씩 커진다. 그림의 경우에는 padding=2를 주어 전체적으로 4씩 커지는 과정이다.
5. Pooling layer
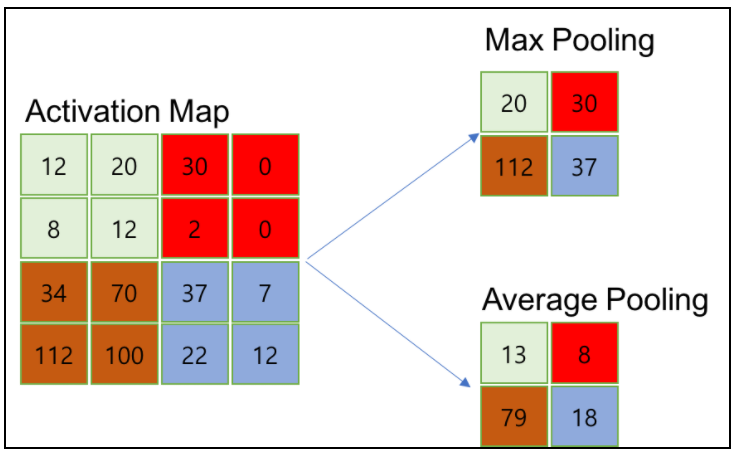
feature map 크기가 확 줄었어요.. 데이터가 너무 작아졌어! 할때 가장 먼저 확인해야 하는 부분이다. Pooling을 사용하면 데이터의 크기가 매우 작아진다. feature map을 만들때도 데이터가 줄어들지 않나요? 라고 할수도 있는데 pooling을 사용하면 상대적으로 kernel을 사용할때보다 더 작아진다.
일반적으로 kernel = 3 or 5, stride = 1 or 2를 사용하기 때문이다
CNN의 구성