Face Detection model에서 SSH는 큰 기여를 한 모델인데, 여타 다른 논문 리뷰가 없다보니 이 참에 한번 해보려고 한다.
SSH 논문 : https://arxiv.org/pdf/1708.03979
해당 논문은 2017년에 나온 모델이라 나온지 꽤 된 모델이며, Face detection의 head로 많이 사용하다보니 꼭 알고 넘어가야 할 모델이라 생각했다.
최근에는 Face Detection을 Yolov8을 이용해서 detection을 하기도 하고 SCRFD 모델을 이용해서 Face Detection을 하기도 하는데, 고전 모델을 공부하고 분석해서 최근에 나오는 model들과 비교하는 것도 좋은 방법일것 같아 매우 유익한 시간이 될 것 같다.
Abstract
SSH는 'headless'이다. 논문에서 가장 중요한 것은 headless이다.
Headless란 무엇인가?
classification, detection model에서의 head는 대부분 FCN이 담당했다. Fully-connected-Network를 없애고 오직 convolution layer만을 활용하여 얼굴을 예측하는 것이 point이다.
FCN을 사용하지 않게 되면, 모델의 구조는 보다 간단하고 경량화된 구조로 설계할 수 있다는 점이다.
--> 여기서 확실히 알고 넘어가야 하는 것은 SSH의 전체 Architecture가 중요하다기보단 FCN이 없어도 CNN만으로 예측이 가능하다는 것.
1. Introduction
해당 sector도 Abstract에서 말했던 내용에 대해 말한다.
CNN 기반 detector는 1stage(yolo), 2stage(faster RCNN)로 나뉜다.
특히 2stage 얼굴 검출에서 문제점은 계산량이 많다는 것인데, selective search 처럼 미리 찍어둔 후보 영역을 CNN 모델에 통과시켜야 하기 때문이다.
SSH 모델은 1 stage 단계에서 얼굴을 검출해야 했으며 anchor box를 사용하여 얼굴이 존재할 가능성이 있는 위치를 예측한다. SSH는 Anchor Box를 사용한 Yolov3보다 먼저 나왔기 때문에 1 stage에 anchor box를 사용한 훌륭한 모델이 탄생한 셈이다.
SSH의 주요 특징
- Headless 구조
- FCN을 제거하여 가벼운 Network
- Scale 불변성
- 외부 Mulitiscale pyramid 없이도 다양한 Scale의 얼굴을 검출
- 서로 다른 stride를 가진 convolution module을 각 layer에 배치함.
- Fast 속도
- ResNet보다 5배 빠름.
- Image Pyramid를 사용해도 SSH는 성능 손실이 없음.
- Performance
- mAP 4% 향상
2. Proposed Method
2.1 . General Architecture
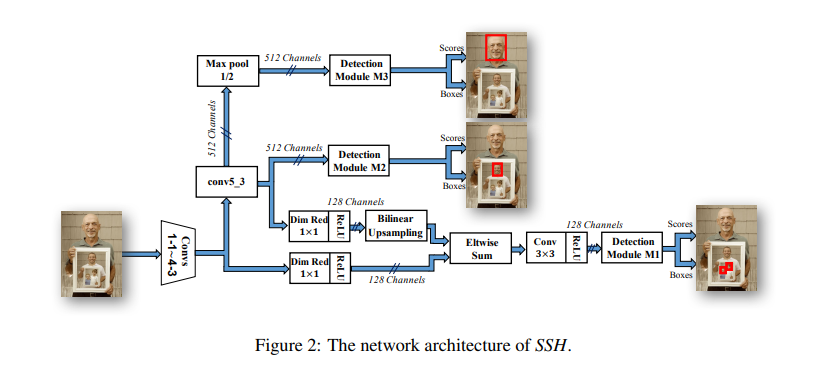
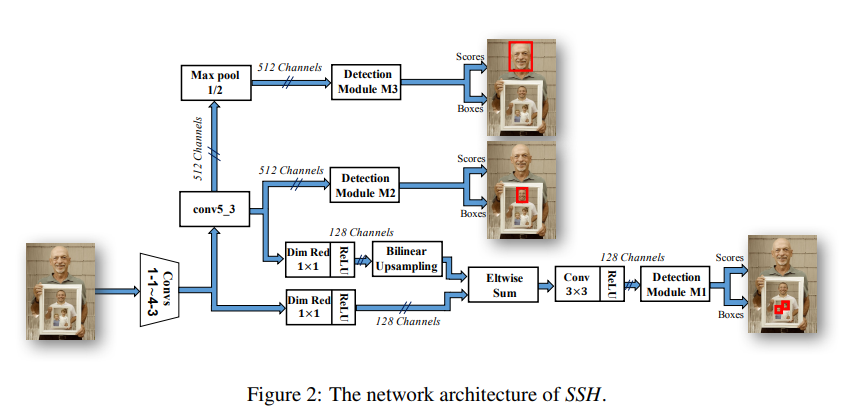
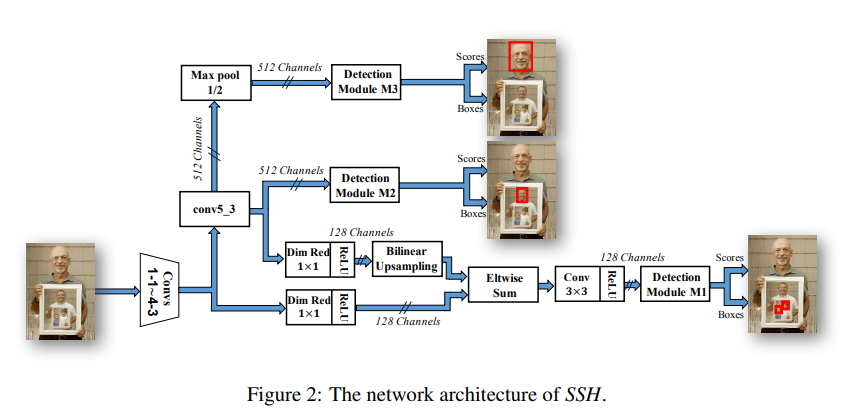
SSH의 전체적인 Architecture이다. 초기 feature map에서 얼굴을 localize하고 classify하는 작업을 수행한다.
초기 feature map이라 해도 상당히 깊은 신경망이며 Conv1 ~ conv4.3까지 해당하는 상당한 양의 신경망이니 초기 feature map인데 어떻게 얼굴의 위치를 localize할 수 있는가에 대한 의문은 내려두자.
SSH는 RPN에서 앵커를 정의하는 방법과 유사한 전략을 사용하여, ground truth 박스와 일치하는 미리 정의된 bounding box를 regression한다.
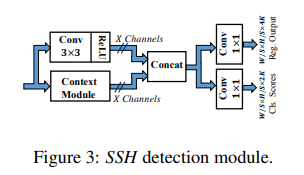
검출 모듈은 얼굴 검출과 위치 조정을 위해 feature를 추출하는 cnn 집합으로 구성된다. receptive field를 늘리기 위해 3개의 context module을 포함한다.
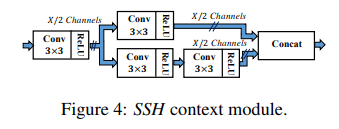
context 모듈은 위와 같다.
2.2 Scale-Invariance Design
기존 접근법은 피라미드를 형성하거나 여러 순방향 패스를 수행하는 방식은 정확도가 높지만 속도가 느리다.
SSH는 단일 Network의 단일 순방향 패스에서 작은, 중간, 큰 얼굴을 동시에 처리할 수 있다.
전체적인 내용은 Figure 2에 대한 설명이므로 패스.
2.3 Context Module
여러 논문들을 보다보면 Context에 대한 내용이 많이 나오는데, 도대체 context가 뭔지 제대로 알아보자.
Selective Search를 할때, 객체가 있는지 판단하기 위해서 여러가지 유형들을 다 살펴본다. 객체 주변의 픽셀, 배경, 형태, 관계성 등을 활용하여 여러 정보들을 살펴보는데 이런 정보들을 context 정보라고 한다.
Context 정보가 왜 중요한가?
객체를 검출한다고 할때, 해당 객체의 특징만 본다면 occlusion인 상황에선 매우 취약해진다. 배경이 복잡하거나 어두울 경우 검출 정확도가 현저하게 떨어지기 때문이다.
그러나 해당 객체 주변의 context 정보를 활용한다면 object가 위치하는지 명확하게 인식할 수 있게 된다.
그래서 사람이 맞는지 아닌지 판단하는 기준이 얼굴이 아니라 그 주변의 머리카락, 목, 어깨 등을 보고 그 안에 얼굴이 있을거라고 판단하게 되는 것이다. 만약 얼굴이라는 특징만 학습하게 된다면 얼굴이 없는 곳에도 bounding box가 그려지는 괴 현상이 발생한다.
Context Module도 (5 x 5), (7 x 7) filter을 사용하여 구성한다. filter size를 키우면 더 많은 영역을 보게 되는데, 이는 receptive field가 확장되므로 훨씬 더 많은 정보 즉, Context 정보를 얻게 된다.
논문에서는 (5 x 5), (7 x 7) filter를 사용했다고 하는데, 실제로 구현된건 ( 3 x 3 ) 2개, ( 3 x 3 ) 3개를 사용한 것과 같다.
- ( 3 x 3 ) 커널을 한 번 사용하면 receptive field는 : 3 x 3
- ( 3 x 3 ) 커널을 두 번 연속 사용하면 receptive field는 : 5 x 5
- ( 3 x 3 ) 커널을 세 번 연속 사용하면 receptive field는 : 7 x 7
이렇게 설계한 의도는 효율성과 메모리 절감에 있다.
5 x 5 커널의 한번 연산은 25의 가중치를 학습해야 하지만 3 x 3 커널 두개는 9 + 9이므로 총 18번이다. 게다가 딥러닝 프레임워크와 하드웨어는 3 x 3 커널에 최적화되어 있어 큰 커널보다 계산이 빠르다.
Retina Face에서 head에 사용한 아이디어는 이 Context module에 있는데, 크게보면 detection Module이지만 Face를 detection 하기 위해 Context 정보를 매우 중요시 했다는 것을 알 수 있다.
