C2f Module은 CSPnet에서 업그레이드(?)된 모듈이라고 보면 된다. 성능은 그대로이지만 계산량과 메모리를 줄여 실시간 성능을 극대화 하였다.
출처 : https://abintimilsina.medium.com/yolov8-architecture-explained-a5e90a560ce5
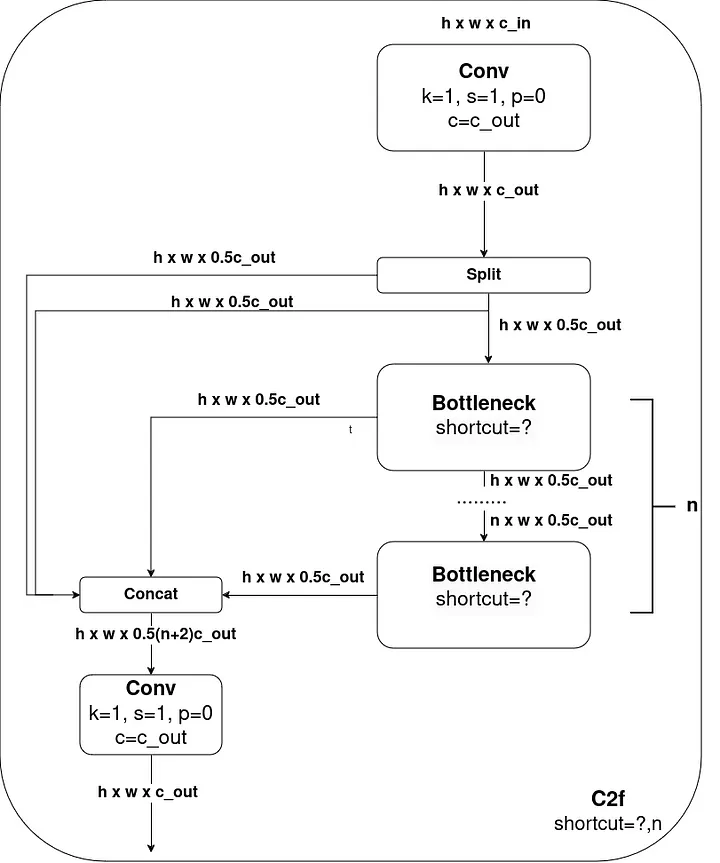
C2f 모듈은 이와 같이 생겼는데, 매우 직관적으로 flow를 그려놔서 이해하기가 쉽다.
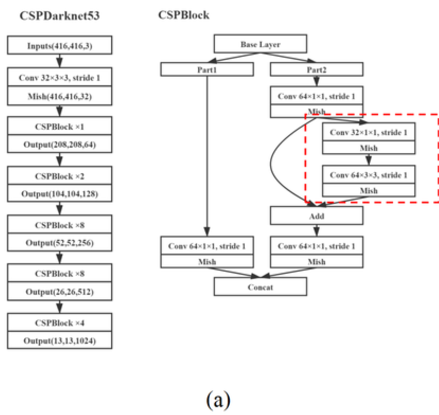
참고 : https://velog.io/@joon10266/CSPnet%EC%9D%98-%EC%9D%B4%ED%95%B4
Yolov4의 CSP 모듈과 비교하면 큰 차이점이 있는데, Yolov4는 CSP모듈을 여러번 반복하지만 YoloV8의 경우에는 CSP 모듈 내의 Bottleneck을 여러번 반복하는 방식을 채택하였다.
이는 Mobilenet의 모델의 경량화, 메모리를 줄이는 구조랑 매우 비슷한데, 1*1 convolution을 통해 계산량을 줄이고 채널을 절반으로 줄여 계산량은 줄이는 방식이 매우 비슷하다. (**아마 Yolov4 저자가 mobilenet model 구조를 참고하여 설계하지 않았을까 싶다.) 요약하면 다음과 같다.
YoloV4 와 Yolov8의 차이점 (C2f 모듈 기준)
| Yolov4 | Yolov8 | |
|---|---|---|
| CSP 반복 횟수 | 여러번 반복 | 한번 반복 |
| Bottleneck 여부 | X | O |
| Bottleneck 반복 횟수 | X | 여러번 반복 |
| residual 사용 | O(필수) | O(custom) |
이처럼 조금 다른 구조를 갖고 있지만 C2f는 CSP module과 매우 비슷하기 때문에, 쉽게 코드를 구현할 수 있을 것 같다.
import torch
from torch import nn
class CNNBlock(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(CNNBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
def __init__(self, in_channels, out_channels, shortcut=None):
super(Bottleneck, self).__init__()
self.block = nn.Sequential(
CNNBlock(in_channels, out_channels // 2, kernel_size=3, stride=1, padding=1),
CNNBlock(out_channels // 2, out_channels, kernel_size=3, stride=1, padding=1),
)
self.shortcut = shortcut and (in_channels == out_channels)
def forward(self, x):
residual = x
output = self.block(x)
return residual + output if self.shortcut else output
class C2f(nn.Module):
def __init__(self, in_channels, out_channels, repeat, shortcut):
super(C2f, self).__init__()
self.f_conv1x1 = CNNBlock(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
self.block = nn.ModuleList([
Bottleneck(out_channels, out_channels, shortcut=shortcut) for _ in range(repeat)
])
self.l_conv1x1 = CNNBlock(out_channels * (repeat + 1), out_channels,
kernel_size=1, stride=1, padding=0)
def forward(self, x):
output = [self.f_conv1x1(x)]
for block in self.block:
output.append(block(output[-1]))
output = torch.cat(output, dim=1)
f_output = self.l_conv1x1(output)
return f_output
if __name__ == "__main__":
c2f = C2f(in_channels=64, out_channels=128, repeat=3, shortcut=True)
x = torch.randn(1, 64, 32, 32)
output = c2f(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")
전체적인 C2f Module Diagram인데, 위의 코드에 맞게 그린 Diagram이라 Bottleneck의 갯수를 3개만 그리긴했는데, 실제론 Bottleneck의 갯수는 custom에 맞게 늘어나거나 줄어든다.
output.append(block(output[-1]))그래서 코드 자체도 output이라는 list를 만들고 block의 마지막을 계속 채운 후에 (모든 for문이 돌아간 후) torch.cat()하여 정상적으로 작동할 수 있도록 한다.
