나의 단기적인 목표는 다음과 같다.
1. Yolov1 scratch 리뷰
2. Yolov2 paper 리뷰
3. Yolov2 scratch 리뷰
4. Yolov3 paper 리뷰
5. Yolov3 scratch 리뷰
6. DMS(Driver moniotoring system) 리뷰
7. Retina Face paper 리뷰
8. Retina Face scratch 리뷰
9. Yolov5 scratch
10. Yolo 상위 버전 scratch
.
.
.
우선은 위와 같은 순서대로 진행할 예정이다.
우선 Yolov1 scratch 에 대한 전반적인 내용은 끝났고 Yolov1에서 설명하지 못한 부분들은 Yolov2와 Yolov3 등 상위 버전을 리뷰하면서 추가적으로 설명할 예정이다. 처음부터 완벽히 이해할 필요는 없다. 애초에 불가능하다. 상위버전을 공부하면서 아래 버전에 대한 내용이 저절로 이해되도 하니깐 말이다.
자 일단 Yolov2 paper 논문을 파헤쳐보자.
Yolov2의 경우 제목이 좀 신기하다. YOLO9000으로 되어 있기 때문이다. 9000에 대한 내용은 부제에 이유가 있다. (Better, Faster, Stronger에서 Stronger에서 설명하도록 하겠다.)
1. Better
YOLOv2의 경우 딱 세가지만 집중있게 보면 된다. Better, Faster, Stronger 이 세가지 말이다.
우선 Better에서 저자가 말하고 싶은 내용은 크게 4가지이다.
- Batch Normalization
- High Resolution Classifier
- Convolutional with Anchor Boxes
- Dimesion Clusters
- Direct location prediction
- Fine-Grained Features
우선 이 내용에 대해 깊게 들어가기 전에, YoloV1에서 공부했던 내용을 복기해보자.
Yolov1의 Loss Funcion을 생각해보자.
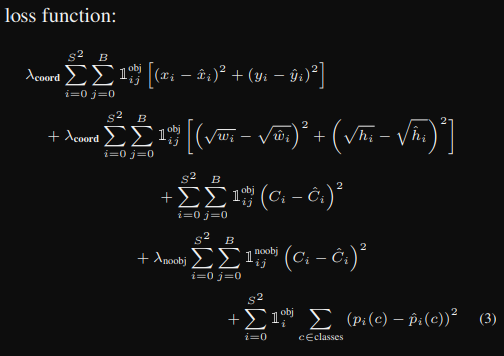
Yolov1에서 λcoord에 5를 주었던 것을 기억하는가? 왜 첫번째와 두번째의 수식에 λcoord를 곱했을까? 그 이유는 Localization에 있다. 저자는 Yolov1이 classification보다 Localization에 초점을 두고 architecture를 만들었다는 것이다.
Localization이 뭔데?
Object Detection에서 Localization은 이미지에서 객체의 정확한 위치를 찾는 것을 의미한다. 이미지 속 객체의 위치와 크기를 나타내는 바운딩 박스를 예측하는 과정을 포함한다.
Yolov1의 Loss Function에서 첫번째 수식과 두번째 수식을 자세히 살펴보자.
첫번째 수식은 bounding box의 중간 상대 좌표 x, y에 해당한다.
두번째 수식은 bounding box의 width height의 크기에 해당한다.
이 두 개의 수식은 Localization과 관련이 깊다는 것을 알 수 있다.
하지만 YoloV1의 경우 λcoord를 통해 Localization의 영향력을 더 부여했음에도 불구하고 Recall 값이 떨어져서 성능이 좋지 않았다.
1. Batch Normalization
원래 기존의 Yolov1에서는 원래 Batch Normalization을 사용하지 않았다. yolov1 scratch에서는 사용했었느나 원래는 사용하지 않았다는 것.
그럼 Batch Normalization이 뭐냐?
Batch Normailzation은 어떻게 보면 vanishing Gradient를 해결하기 위한 과정이다. Relu를 생각해보면 입력값이 모두 음수라면 어떻게 되는가? 출력은 0이 나오고 vanishing Gradient에 빠지게 된다. 일단 Leaky Relu로 그 예를 들어보자.
input은 빨간색이다. 평균의 절대값은 같고 분산은 같다고 가정했을때,어때보이는가? 잘 학습될 것 같은가? 학습은 잘된다. 왜냐면 음수여도 Leaky Relu를 사용했기 때문에, vanishing gradient가 발생하지 않기 때문이다. 그러나 그건 반쪽자리에 불과하다.
머신러닝, 딥러닝이 뜨기 시작한건 linearity를 해결했기 때문이 아니라 non-linearity를 해결했기 때문에 뜨기 시작했다. 즉, Leaky Relu에서 입력값이 모두 음수이거나 양수라면 해당 모델은 linearity로 학습할 수 밖에 없다는 것을 의미한다. 즉, linear activation function을 사용한 것과 같은 동작을 한다는 것을 의미한다.
이를 방지하기 위한 목적으로 Batch Normalization을 사용한다. 입력값이 non_linearity값을 모두 가질수 있고 적절하게 분포되어 있으면 학습에 더 용이하기 때문이다.
즉, 이와 같이 입력값을 분포하게 만들어 주는 작업이 Batch Normalization이다. 일반적으론 평균은 0, 분산은 1로 만들어서 적절하게 non-linearity 값을 가질 수 있도록 하는게 핵심이다.
저자는 Batch Normalization을 통해서 Dropout을 사용하지 않다고 했다. 결국에 Dropout을 사용한 이유는 overfitting, Vanishing Gradient를 막기 위함이니, Batch Normalization이 큰 기여를 했다고 볼 수 있다.
2. High Resolution Classifier
크게 중요한 내용은 아니다. Yolov1의 경우 Darknet을 224224 크기로 pretrain 했으나 실제 detection에서는 448448로 진행했다는 것을 의미한다.
Yolov2의 경우에는 448*448크기로 pretrain 시켜서 mAP를 상승시켰다는 것을 의미한다.
이건 너무 당연한 내용이다. 이미지의 크기가 클수록 객체의 정확성, 명확성이 두드러지기 때문이다. 따라서 Localization에서도 성능에 두각을 일으켰을 가능성이 매우 높아진다.
3. Convolutional with Anchor Boxes
yolov1 scratch 했을때 기억이 나는가? Yolov1 model의 output tensor shape는 다음과 같다.
(BATCH_SIZE, S, S, C + B * 5)
여기서 S = split_size, C = num of classes, B = num of Boxes를 의미하는데, B는 하나의 cell에서 bounding box의 개수를 의미한다. 즉, 하나의 cell에서는 오직 정해진 갯수인 B=2인 bounding box 2개의 정보만 가져올 수 있다는 것을 의미한다.
하지만 Yolov2의 경우에는 Faster RCNN에서 사용한 Anchor 방식을 가져와서 성능을 높였다. 448448이미지를 416416으로 바꾼 이유에 대해서는 마지막 feature map을 홀수로 만들어 하나의 중심 cell이 존재할 수 있도록 하기 위함이다. 큰 객체가 이미지에 있다면 일반적으론 해당 객체는 중심에 위치하기 때문이다. (결국 더 잘 찾기 위해서 feature map을 홀수로 만든 것)
anchor box를 사용하지 않을 경우에는 69.5mAP와 81% recall 값을 얻었지만 anchor Box를 사용한 경우에는 69.2mAP와 88% recall 값을 얻어냈다. 즉, anchor box를 사용하면 mAP는 0.3하락했지만 recall값은 대폭 상승했다.
Object Detection에서 recall값이 높다는 것은 모델이 실제 객체의 위치를 예측한 비율이 높음을 의미한다. yolov1의 경우 하나의 cell에 대하여 bounding box가 2개였지만 yolov2의 경우 anchor box로 인해 더 많은 수의 bounding box를 예측할 수 있으므로 recall 값이 상승하고 Localization 성능도 높아질 수 있다.
4. Dimesion Clusters
Anchor box도 같이 학습하기 때문에 모델을 학습하면서 Anchor box도 계속해서 수정된다. 그렇기 때문에 초기 Anchor box 영향이 크게 되는데, 이때 k-means clustering을 사용한다.자세한 내용은 코드를 보면서 설명하는게 빠르니 yolov2 scratch 포스트를 참고하길 바란다.
5. Direct location prediction
위의 anchor box를 활용한 방법은 좋은 방법이지만 바운딩 박스의 위치를 제안하지 않기 때문에 이미지의 임의의 위치에 위치할 수 있는 리스크가 존재한다. 이 리스크를 방지하기 위해 저자는 sigmoid 함수를 사용하여 해당 박스의 offset의 범위를 0~1로 제한한다.
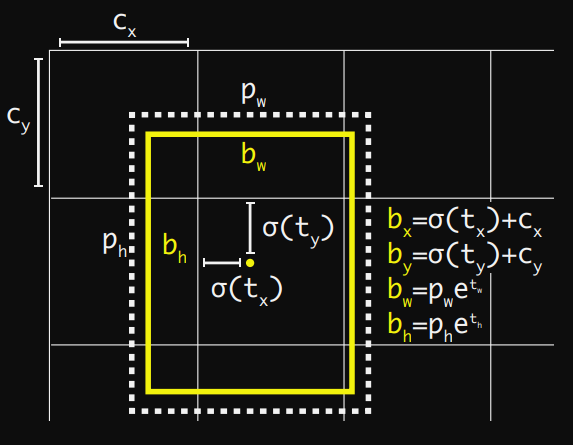
cx = 좌측 상단에서 grid cell의 x좌표
cy = 좌측 상단에서 grid cell의 y좌표
pw = 이전 바운딩 박스의 너비
ph = 이전 바운딩 박스의 높이
6. Fine-Grained Features
passthrough layer에 대한 설명인데, 2626 feature map을 1313 feature map 4개로 쪼개어 필터의 갯수를 늘려 concatenate하여 학습하는 방식이다. 해당 방식이 좋은 성능을 보이는 이유는 tiny object의 detection 성능이 상승하는데에 있다.

보다 큰 stride=2를 적용하거나 maxpooling을 적용하면 feature의 정보가 손실되는 경우가 있으나 해당 방식은 feature의 정보 손실도 없고 고해상도 이미지에서 정보를 추출할 수 있으므로 작은 객체에 대해서 성능이 높아짐을 보였다.
2. Faster
Yolov2의 Darknet-19 architecture에 대한 소개이다.
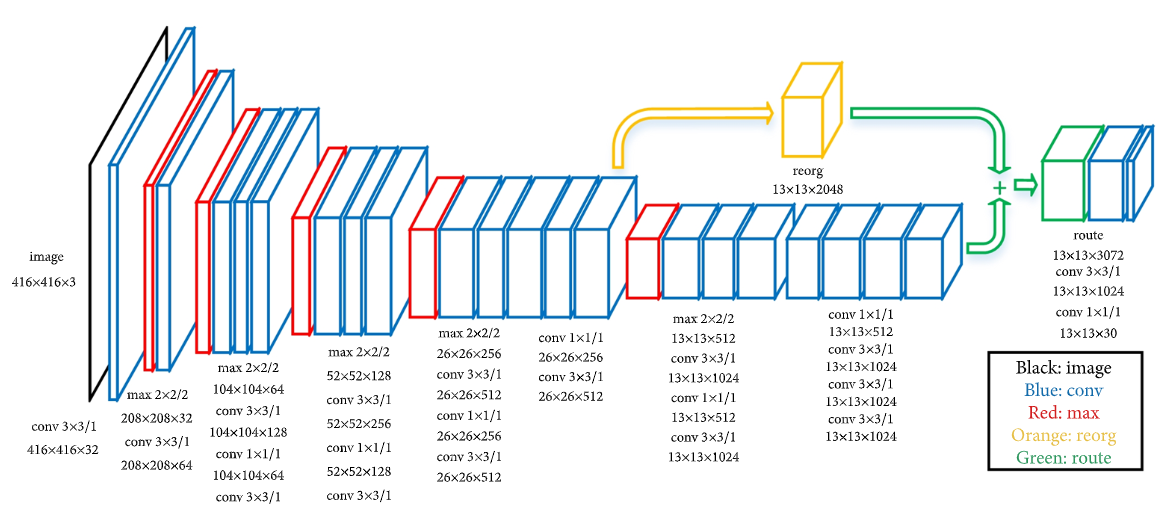
3. Stronger
해당 내용은 Yolov2 코드를 보며 관련 내용을 설명해보도록 하겠다. 글로만 보면 이해가 안되는 부분이 있기 때문에,,
