1편에 이어 2편을 시작해보려 한다.
https://velog.io/@joon10266/Object-Detection1-stage-YoloV1
1편을 보지 않았다면 꼭 보길 바란다. 순서대로 보아야 이해가 빠르다.
지금부터 할 내용은 Object Detection의 꽃인 Loss에 대해서 분석해보려고 한다.
Yolo loss에 대한 깊은 고찰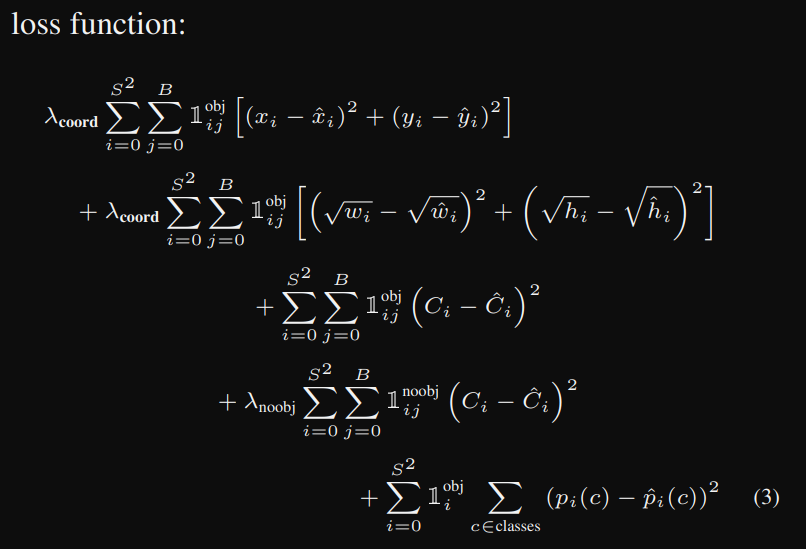
yolov1의 loss는 총 3가지로 구성되어 있다.
- coordinate prediction
- confidence
- class
이 총 3가지의 loss가 더해져서 yolov1의 전체 loss가 나오게 된다.
우선 코드부터 확인해보자. 그리고 하나씩 하나씩 파악해보자.
## yolov1_loss.py
import torch
from torch import nn
class YoloV1Loss(nn.Module):
def __init__(self, S=7, B=2, C=3):
super().__init__()
self.S = S
self.B = B
self.C = C
self.coord = 5
self.noobj = 0.5
self.mse = nn.MSELoss(reduction='sum')
def forward(self, predictions, targets):
predictions = predictions.reshape(-1, self.S, self.S, self.C + self.B * 5)
iou_b1 = intersection_over_union(predictions[..., self.C+1:self.C+5], targets[..., self.C+1:self.C+5])
iou_b2 = intersection_over_union(predicitions[..., self.C+6:self.C+10], targets[..., self.C+1:self.C+5])
ious = torch.cat([iou_b1, iou_b2], dim=0)
iou_maxes, best_box_idx = torch.max(ious, dim=0)
exists_box = targets[..., self.C].unsqueeze(3)
box_predictions = exists_box * (
best_box_idx * predictions[..., self.C + 6:self.C + 10] +
(1 - best_box) * predictions[..., self.C + 1 : self.C + 5]
)
box_targets = exists_box * targets[..., self.C + 1: self.C + 5]
# coordinate loss x, y
box_loss_xy = self.mse(
torch.flatten(box_predictions[..., 0:2], end_dim=-2),
torch.flatten(box_targets[..., 0:2], end_dim=-2),
)
# coordinate loss width, height (box loss)
box_predictions[..., 2:4] = torch.sign(box_predictions[..., 2:4] * torch.sqrt(torch.abs(box_predictions[..., 2:4] + 1e-6))
box_targets[..., 2:4] = torch.sqrt(box_targets[..., 2:4])
box_loss_wh = self.mse(
torch.flatten(box_predictions, end_dim=-2),
torch.flatten(box_targets, end_dim=-2)
)
# object loss
pred_box = (
best_box_idx * predictions[..., self.C + 5: self.C+6] + (1 - best_box_idx) * predictions[..., self.C:self.C + 1]
)
object_loss = self.mse(
torch.flatten(exists_box * pred_box),
torch.flatten(exists_box * targets[..., self.C:self.C+1]),
)
# no_object loss
no_object_loss = self.mse(
torch.flatten((1 - exists_box) * predictions[..., self.C:self.C+1], start_dim=1),
torch.flatten((1 - exists_box) * targets[..., self.C:self.C+1], start_dim=1),
)
no_object_loss += self.mse(
torch.flatten((1 - exists_box) * predictions[..., self.C+5:self.C+6], start_dim=1),
torch.flatten((1 - exists_box) * targets[..., self.C: self.C+1], start_dim=1),
)
# class loss
class_loss = self.mse(
torch.flatten(exists_box * predictions[..., :self.C], end_dim=-2),
torch.flatten(exists_box * targets[..., :self.C], end_dim=-2),
)
loss = (
self.coord * box_loss_xy +
self.coord * box_loss_wh +
object_loss +
self.noobj * no_object_loss +
class_loss
)
return loss
우선 해당 코드에서 특정 부분을 뜯어서 살펴보도록 하자.
predictions = predictions.reshape(-1, self.S, self.S, self.C + self.B * 5)
iou_b1 = intersection_over_union(predictions[..., self.C+1:self.C+5], targets[..., self.C+1:self.C+5])
iou_b2 = intersection_over_union(predicitions[..., self.C+6:self.C+10], targets[..., self.C+1:self.C+5])
ious = torch.cat([iou_b1, iou_b2], dim=0)
iou_maxes, best_box_idx = torch.max(ious, dim=0)
exists_box = targets[..., self.C].unsqueeze(3)
model에서 내뱉는 predictions의 shape는 다음과 같다.
(BATCH_SIZE, self.S, self.S, self.C + self.B * 5)이므로 predictions.reshape()를 통해서 굳이 4D shape를 만들지 않아도 되지만 안정성을 위해서 추가한 코드이다.
iou_b1, iou_b2의 변수는 intersection_over_union이라는 함수를 불러와 작동하는데, 별거 없다.(loss에 대한 내용이 끝나면 utils에 대한 내용이 나올 예정이므로 자세한 내용은 뒤를 참고하자.) 교집합을 생각하자. 실제 ground truth인 target과 model이 예측한 bounding box의 접하는 부분의 면적을 구하는 코드이다.
우리가 한 셀에서 예측할 수 있는 바운딩 박스인 B=2로 설정해놨으므로 model이 예측할 수 있는 predictions.shape는 (Batch_size, self.S, self.S, self.C + self.B * 5)로 나오게 된다. 즉,(Batch_size, 7, 7, 13)이 나오게 된다는 것이다.
여기서 13의 내부를 보면 [cls1, cls2, cls3, obj1_conf, x, y, w, h, obj2_conf, x, y, w, h]인 형태를 갖게 된다.
따라서 predictions[..., self.C + 1: self.C + 5], targets[..., self.C+1: self.C+5]의 접한 면적을 구하는 것이다. 그것이 iou_b1이 된다.
iou_b2도 마찬가지이다. predictions[..., self.C+6:self.C+10], targets[..., self.C+1:self.C+5]의 접한 면적을 구하여 iou_b2에 저장한다.
이렇게 구한 iou_b1, iou_b2를 가장 큰 iou값을 가지는 bounding box를 반환해야 하니
torch.cat([iou_b1, iou_b2], dim=0)과 iou_maxes, best_box_idx = torch.max(ious, dim=0) iou가 가장 높은 값을 갖는 값과 해당 박스의 인덱스를 추출하는 것이다. 이해가 안되면 아래의 예시 코드를 이해하자.
# 예제 예측값과 타겟값 정의
predictions = torch.tensor([
[0.4, 0.5, 0.2, 0.3], # 첫 번째 바운딩 박스 예측값
[0.45, 0.55, 0.25, 0.35] # 두 번째 바운딩 박스 예측값
])
target = torch.tensor([0.42, 0.52, 0.22, 0.32]) # 타겟 바운딩 박스
# 각 바운딩 박스에 대해 IOU 계산
iou_b1 = intersection_over_union(predictions[0], target)
iou_b2 = intersection_over_union(predictions[1], target)
# IOU 결과 병합 및 최대 IOU 선택
ious = torch.cat([iou_b1.unsqueeze(0), iou_b2.unsqueeze(0)], dim=0)
iou_maxes, best_box = torch.max(ious, dim=0)
# 결과 출력
print(f"IOU of Box 1: {iou_b1.item()}") # IOU: 0.7317
print(f"IOU of Box 2: {iou_b2.item()}") # IOU: 0.6556
print(f"Max IOU: {iou_maxes.item()}") # Max IOU: 0.7317
print(f"Best Box Index: {best_box.item()}") # Best Box: 0 (첫 번째 박스 선택됨)
이제 다음 코드를 이해해 보자.
box_predictions = exists_box * (
best_box_idx * predictions[..., self.C + 6:self.C + 10] +
(1 - best_box) * predictions[..., self.C + 1 : self.C + 5]
)
box_targets = exists_box * targets[..., self.C + 1: self.C + 5]
exists_box는 0과 1의 값만 가진다. 왜냐하면 object가 존재하는지 아닌지에 대한 값을 가져오기 때문이다. targets[..., self.C]는 [cls1, cls2, cls3, obj1_conf, x, y, w, h, obj2_conf, x, y, w, h]에서 obj1_conf의 값을 가져오는 것이기 때문이다.
따라서 객체가 존재하지 않으면 box_predictions의 값은 0이 된다.
box_predictions의 값이 1이 되었을 때를 생각해보자. best_box_idx가 1인 경우엔 두번째 bounding_box의 iou값이 크므로 predictions[..., self.C+6:self.C+10]이 곱해져야 하므로 위와 같은 계산식을 갖게 된다.
# coordinate loss x, y
box_loss_xy = self.mse(
torch.flatten(box_predictions[..., 0:2], end_dim=-2),
torch.flatten(box_targets[..., 0:2], end_dim=-2),
)
# coordinate loss width, height (box loss)
box_predictions[..., 2:4] = torch.sign(box_predictions[..., 2:4] * torch.sqrt(torch.abs(box_predictions[..., 2:4] + 1e-6))
box_targets[..., 2:4] = torch.sqrt(box_targets[..., 2:4])
box_loss_wh = self.mse(
torch.flatten(box_predictions, end_dim=-2),
torch.flatten(box_targets, end_dim=-2)
)
해당 코드는 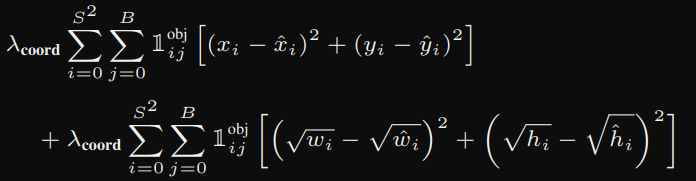
이 수식에 해당한다. box_predictions[..., 2:4] = torch.sign(box_predictions[..., 2:4])를 곱하는 이유는 원래 없어도 되긴하지만 안정성을 위해 개발자가 기입한 거다. 모델이 예측한 값이 -가 나온다면 예기치 못하는 결과가 발생할 수 있으므로 이를 방지하기 위해 곱해주는 작업을 한다.
# object loss
pred_box = (
best_box_idx * predictions[..., self.C + 5: self.C+6] + (1 - best_box_idx) * predictions[..., self.C:self.C + 1]
)
object_loss = self.mse(
torch.flatten(exists_box * pred_box),
torch.flatten(exists_box * targets[..., self.C:self.C+1]),
)해당 코드는 아래의 수식을 담당한다.
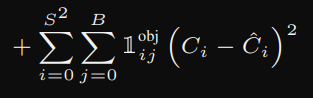
[cls1, cls2, cls3, obj1_conf, x, y, w, h, obj2_conf, x, y, w, h]에서 obj1_conf와 obj2_conf의 값을 보는 것. 객체의 confidence score의 값을 보는 것이다. no_object_loss도 object_loss와 거의 같은 매커니즘이기 때문에 생략한다.
나머지 코드도 수식에 대한 걸 풀어썼기 때문에 추가적인 설명은 생략한다.
