
1. 최소 신장 트리
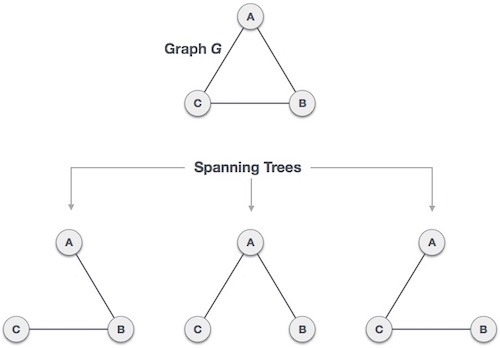
신장 트리(Spanning Tree)
- 그래프 내의 모든 정점들을 포함하는 그래프의 부분집합(subgraph) Tree
- 최소한의 간선들로 그래프 내의 모든 정점을 포함
- 따라서 Spanning Tree는 cycle을 포함하지 않음
- 그래프 내의 정점의 수가 n개이면, Spanning Tree는 (n-1) 개의 간선을 가짐 - 한 그래프 내의 여러 개의 Spanning Tree가 있을 수 있음
최소 신장 트리 (Minimum Spanning Tree)
- 가중치가 있는 그래프(weighted graph)에서 최소 가중치를 가진 Spanning Tree
- 즉, 한 그래프 내의 여러 개의 Spanning Tree 중 minimum weight을 가진 Spanning Tree
- MST를 구하는 대표적인 알고리즘으로는 Prim과 Kruskal 알고리즘이 있음
프림 알고리즘 (Prim's Algorithm)
프림 알고리즘은 Tree에 포함되지 않은 정점들 가운데, 이미 포함된 정점과 가장 가까운 정점을 선택해서 해당 간선을 추가하는 방식이다.
V : 그래프의 모든 정점들의 집합
F : MST에 포함된 간선들의 집합
Y : MST에 포함된 정점들의 집합, Y = V가 되면 MST를 구현한 것
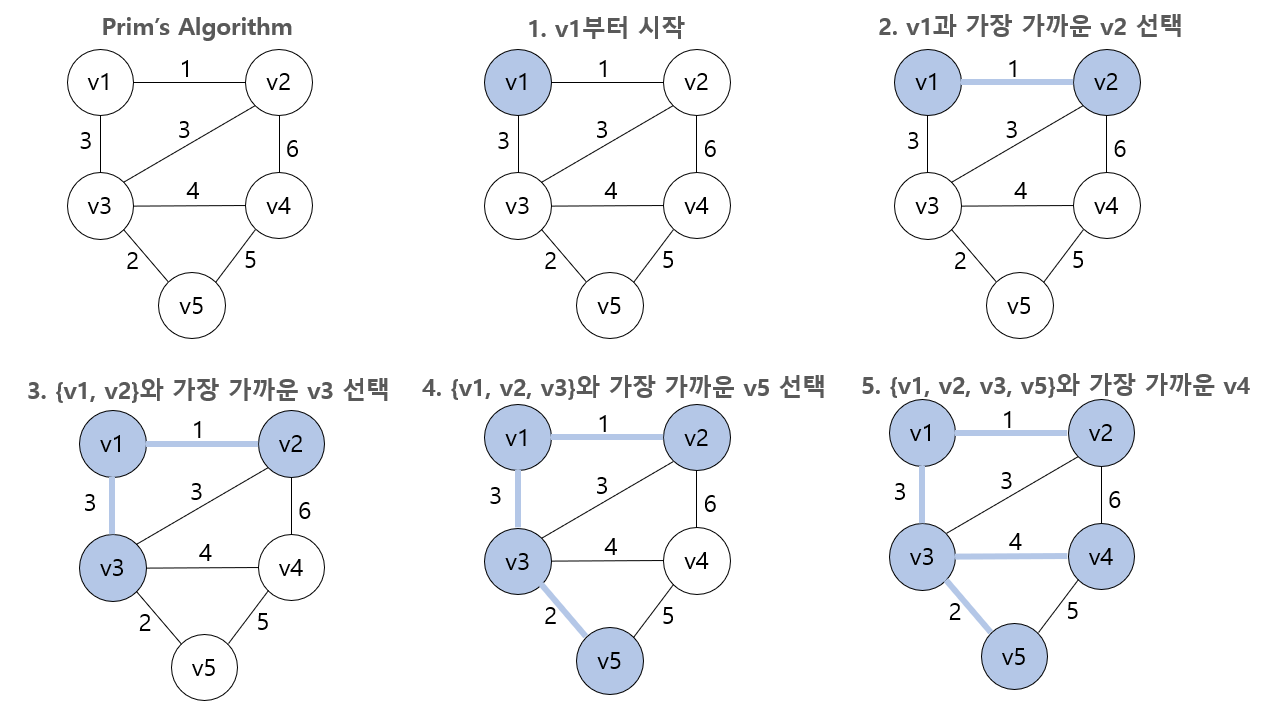
- 첫 번째 정점을 v1이라고 하면 F = { }, Y = { v1 }으로 초기화해준다. 이는 아직 선택된 간선이 없고, v1부터 알고리즘을 수행한다는 의미이다.
Y=V가 될 때까지 다음 과정을 반복한다.
- (V - Y)의 정점들 중 Y와 가장 가까운 정점 A를 선택한다.
- Y에 정점 A를 추가한다.
- F에 간선을 추가한다.
Y=V가 되어서 MST가 완성되면 F는 MST의 모든 간선을 포함한 집합이 되므로 F의 원소 개수는 (n-1)개가 된다.
크루스칼 알고리즘 (Kruskal's Algorithm)
크루스칼 알고리즘은 각 정점을 하나의 원소로 갖는 V의 서로소 집합을 만들어서 시작한다.
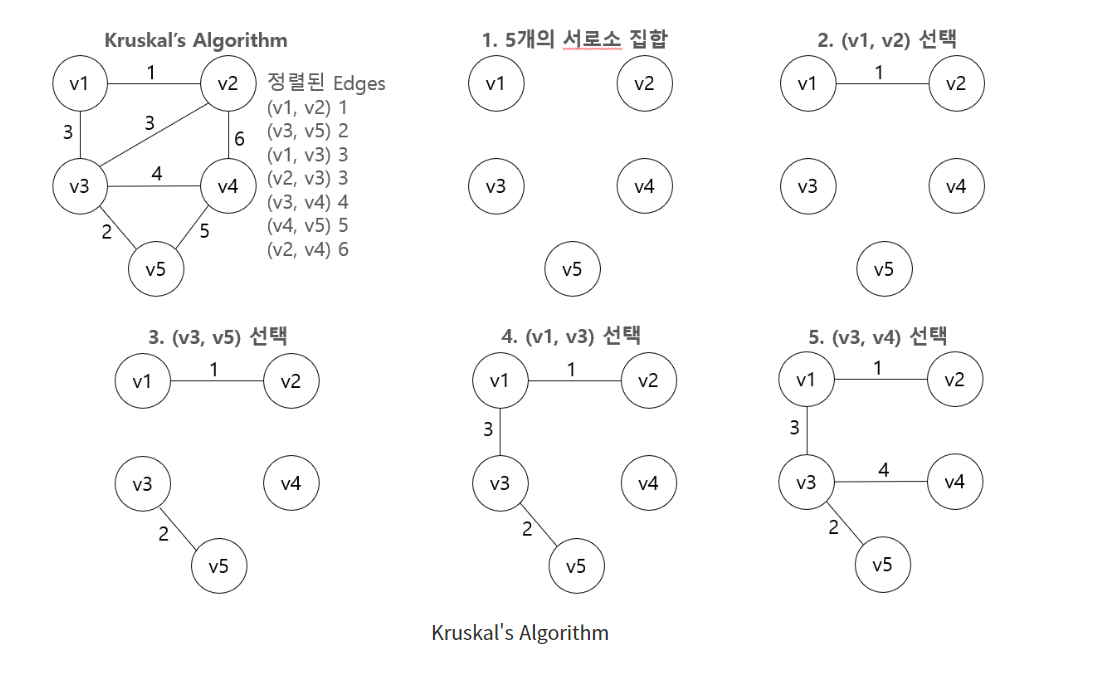
n개의 정점을 가진 그래프라면 처음에 n개의 서로소 부분집합들로 시작하고, 이 집합들은 각 정점만을 원소로 가진다. 이후 간선들의 집합 E를 가중치를 기준으로 오름차순으로 정렬한다. 그리고 하나의 집합이 남을 때까지 다음을 반복한다.
- 간선들의 집합 E에서 다음 간선을 선택한다.
- 만약 간선이 서로소 부분집합에 있는 두 개의 정점을 연결한다면
1) 두 집합을 합친다.
2) 간선을 F에 추가한다. (F는 MST에 포함되는 간선들의 집합)모든 부분집합들이 합쳐지고 나면 F는 MST의 모든 간선을 포함한 집합이 되므로 F의 원소 개수는 (n-1)개가 된다.
2. 최소 신장 트리 구현
프림 알고리즘 (Prim's Algorithm)
최소힙 사용
import heapq
import collections
import sys
sys.setrecursionlimit(10**6)
input = sys.stdin.readline
n, m = map(int,input().split()) # 노드 수, 간선 수
graph = collections.defaultdict(list) # 빈 그래프 생성
visited = [0] * (n+1) # 노드의 방문 정보 초기화
# 무방향 그래프 생성
for i in range(m): # 간성 정보 입력 받기
u, v, weight = map(int,input().split())
graph[u].append([weight, u, v])
graph[v].append([weight, v, u])
# 프림 알고리즘
def prim(graph, start_node):
visited[start_node] = 1 # 방문 갱신
candidate = graph[start_node] # 인접 간선 추출
heapq.heapify(candidate) # 우선순위 큐 생성
mst = [] # mst
total_weight = 0 # 전체 가중치
while candidate:
weight, u, v = heapq.heappop(candidate) # 가중치가 가장 적은 간선 추출
if visited[v] == 0: # 방문하지 않았다면
visited[v] = 1 # 방문 갱신
mst.append((u,v)) # mst 삽입
total_weight += weight # 전체 가중치 갱신
for edge in graph[v]: # 다음 인접 간선 탐색
if visited[edge[2]] == 0: # 방문한 노드가 아니라면, (순환 방지)
heapq.heappush(candidate, edge) # 우선순위 큐에 edge 삽입
return total_weight
print(prim(graph,1))시간복잡도

크루스칼 알고리즘 (Kruskal's Algorithm)
정석
# 특정 원소가 속한 집합 찾기
def find(parent, x):
if parent[x] == x:
return x
parent[x] = find(parent, parent[x])
return parent[x]
# 두 원소가 속한 집합 찾기
def union(parent, a, b):
rootA = find(parent, a)
rootB = find(parent, b)
if rootA < rootB:
parent[rootB] = rootA
else:
parent[rootA] = rootB
# 노드의 개수와 간선의 개수 입력받기
v, e = map(int, input().split())
parent = [0] * (v+1)
edges = []
result = 0
# 부모 테이블 상에서, 부모를 자기 자신으로 초기화
for i in range(1, v + 1):
parent[i] = i
# 모든 간선에 대한 정보를 입력받기
for _ in range(e):
a, b, cost = map(int, input().split())
# 가중치를 오름차순으로 정렬하기 위해 튜블의 첫 번째 원소를 비용으로 설정
edges.append((cost, a, b))
edges.sort()
for edge in edges:
cost, a, b = edge
# 사이클이 발생하지 않는 경우에만 집합에 포함된다.
if find(parent, a) != find(parent, b):
union(parent, a, b)
result += cost
print(result)최소힙 사용
import sys
from heapq import heappush, heappop
input = sys.stdin.readline
def find_set(u):
curr = u
history = []
while curr != parent[curr]:
history.append(curr)
curr = parent[curr]
for h in history:
parent[h] = curr
return curr
def union_set(u, v):
if u == v:
return False
if rank[u] >= rank[v]:
parent[v] = u
if rank[u] == rank[v]:
rank[u] += 1
else:
parent[u] = v
return True
N, M = map(int, input().split())
parent = list(range(N+1))
rank = [0]*(N+1)
edges = []
for _ in range(M):
a, b, c = map(int, input().split())
heappush(edges, (c, a, b))
connected_cnt = 0
ans = 0
while connected_cnt < N - 1:
w, x, y = heappop(edges)
xr, yr = find_set(x), find_set(y)
if union_set(xr, yr):
ans += w
connected_cnt += 1
print(ans)시간복잡도

3. 프림 알고리즘 vs 크루스칼 알고리즘
-
프림은 정점 위주의 알고리즘, 크루스칼은 간선 위주의 알고리즘
-
프림은 시작점을 정하고, 시작점에서 가까운 정점을 선택하면서 트리르 구성 하므로 그 과정에서 사이클을 이루지 않지만 크루스칼은 시작점을 따로 정하지 않고 최소 비용의 간선을 차례로 대입 하면서 트리를 구성하기 때문에 사이클이 이루어지는 항상 확인 해야한다.
-
프림의 경우 최소 거리의 정점을 찾는 부분에서 자료구조의 성능에 영향을 받고 크루스칼은 간선을 기준으로 정렬하는 과정이 오래 걸린다.
간선의 개수가 작은 경우에는 크루스칼, 간선의 개수가 많은 경우에는 프림.
참고문헌
https://mjmjmj98.tistory.com/75
https://8iggy.tistory.com/159
https://8iggy.tistory.com/160

노를 젓다 보면 언젠가는 물이 들어오겠지.