https://www.nature.com/articles/s41587-022-01618-2
요약
-
서론(Introduction):
- 대형 언어 모델이 자연어뿐만 아니라 단백질 설계 및 생명공학 분야에서도 활용될 수 있다는 배경을 설명합니다.
- ProGen이라는 모델을 개발했으며, 이 모델은 다양한 단백질 계통에서 기능적으로 유효한 단백질 서열을 생성할 수 있음을 소개합니다.
-
기존 연구와의 비교(Background and Related Work):
- 전통적인 단백질 설계 방법과 de novo 설계 방법을 설명하며, 구조적 설계 및 공진화 방법의 한계점을 언급합니다.
- ProGen은 이러한 한계점을 극복할 수 있는 가능성을 제시하며, 기존 연구에서 단백질 정보학 및 설계에 어떻게 활용되었는지 설명합니다.
-
ProGen 모델(Methods: ProGen Model):
- ProGen 모델의 설계 원리와 학습 방법에 대해 설명합니다. 280억 개의 단백질 서열 데이터를 사용하여 학습했으며, 각 단백질의 특성을 제어할 수 있는 "컨트롤 태그"를 추가해 모델의 예측 성능을 향상시켰습니다.
- Transformer 기반의 신경망 구조를 활용한 이 모델이 다양한 단백질 계통에서 새로운 단백질 서열을 생성할 수 있음을 설명합니다.
-
실험 결과(Results):
- 다양한 단백질 계통에서 ProGen이 생성한 단백질 서열의 기능성을 실험적으로 검증합니다.
- Lysozyme, Chorismate mutase(CM), Malate dehydrogenase(MDH) 등의 단백질 패밀리에서 인공적으로 생성된 단백질이 자연 발생 단백질과 유사한 기능을 가짐을 보여줍니다.
- 실험적으로 생성된 인공 단백질이 효소 기능을 유지하면서도 자연 단백질과는 서열 상의 유사성이 낮음을 입증합니다.
-
고찰(Discussion):
- ProGen 모델이 전통적인 단백질 설계 방법보다 더 넓은 서열 공간을 탐색할 수 있음을 논의합니다.
- 향후 ProGen 모델의 적용 가능성을 제시하며, 단백질 설계, 생명과학, 의학, 환경 문제 해결을 위한 도구로 활용할 수 있는 잠재력을 설명합니다.
-
결론(Conclusion):
- ProGen 모델이 다양한 단백질 계통에서 기능적 단백질을 생성할 수 있음을 증명했으며, 이 모델이 단백질 설계와 같은 생명공학적 응용 분야에서 혁신을 가져올 수 있음을 강조합니다.
-
부록 및 추가 데이터(Supplementary Information):
- 실험 데이터, 생성된 단백질 서열, 코드 및 모델 체크포인트가 공개된 자료로 포함되어 있으며, 실험 재현에 필요한 정보도 제공됩니다.
Result
논문에 나오는 Results 부분에서는 ProGen 모델을 사용하여 다양한 단백질 계통에서 생성된 단백질 서열의 성능을 실험적으로 검증한 내용을 다루고 있습니다.
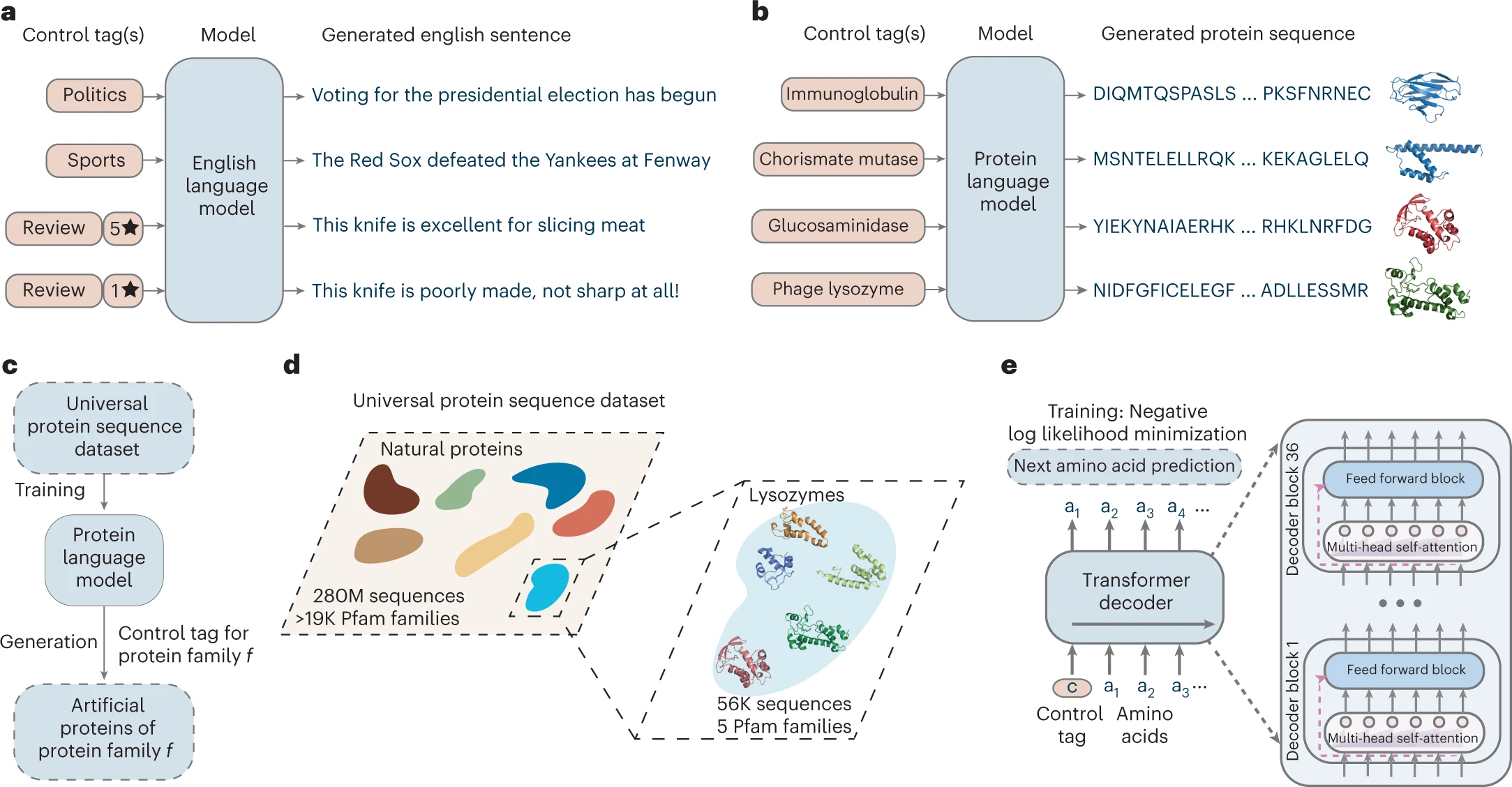
Figure 1: Artificial protein generation with conditional language modeling
이 그림에서는 ProGen 모델의 구조와 기능을 설명하고 있습니다.
- 1a, 1b, 1c: 자연 언어 모델과 단백질 생성 모델의 비교를 시각적으로 나타냅니다. ProGen 모델은 단백질 서열에 대해 입력된 control tags(단백질 특성이나 계통)를 기반으로 특정 서열을 생성할 수 있습니다. 이러한 방식은 자연어에서 문맥에 맞는 문장을 생성하는 것과 유사합니다.
- 1d: ProGen 모델이 학습된 데이터셋을 설명합니다. 280억 개 이상의 단백질 서열이 19,000개 이상의 단백질 계통을 포함합니다.
- 1e: ProGen은 12억 개의 파라미터를 가진 트랜스포머(Transformer) 아키텍처를 사용하여 단백질 서열을 생성합니다.
핵심 내용: ProGen 모델은 다양한 단백질 계통에서 기능적 단백질 서열을 생성할 수 있으며, 이 모델은 구조적 정보 없이도 단백질 서열의 문맥적 특성을 학습할 수 있습니다.
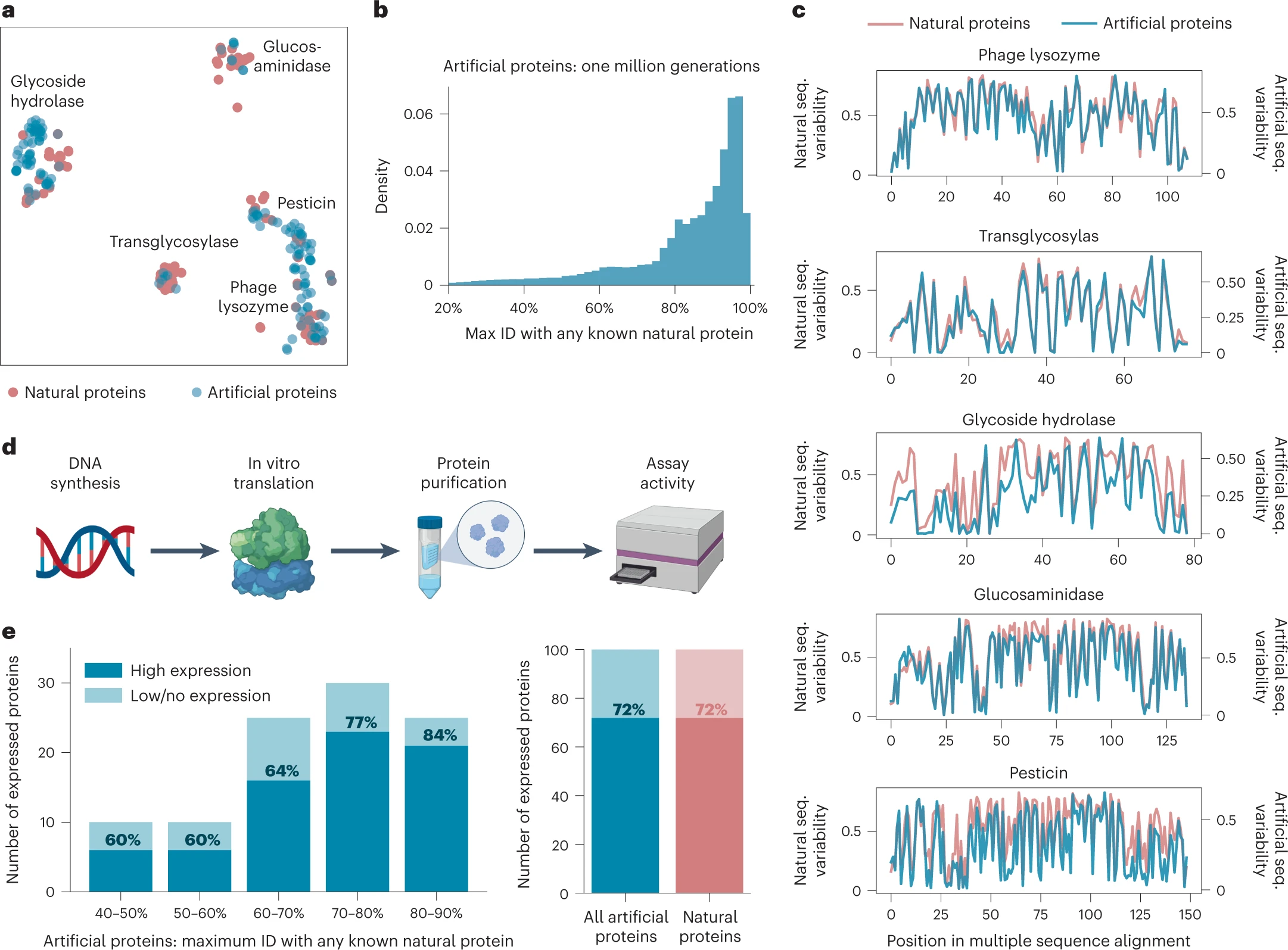
Figure 2: Generated artificial antibacterial proteins are diverse and express well in our experimental system
이 그림에서는 ProGen이 생성한 인공 단백질이 실험적으로 잘 발현되고 기능성을 유지하는지에 대한 평가를 보여줍니다.
- 2a: t-SNE 분석을 통해 ProGen이 생성한 단백질 서열이 자연 단백질 서열 공간을 넓게 커버함을 시각적으로 나타냅니다. 각 점은 다섯 가지 Lysozyme 패밀리에서 생성된 단백질 서열을 나타냅니다.
- 2b: ProGen이 생성한 서열이 자연 서열과 매우 다를 수 있음을 보여줍니다. 서열 간의 최대 일치도(Max ID)가 낮은 경우에도 기능적 단백질이 생성됨을 시사합니다.
- 2c: ProGen이 생성한 단백질 서열이 자연 단백질과 유사한 진화적 보존 패턴을 유지함을 보여줍니다. 서열의 각 위치에서 변동성을 비교하여, 자연 서열과 인공 서열 간의 변동성 차이가 크지 않음을 나타냅니다.
- 2d, 2e: 실험적으로 ProGen이 생성한 단백질이 잘 발현되고, 서열 유사성에 관계없이 높은 발현율(72%)을 보임을 확인했습니다.
핵심 내용: ProGen은 다양한 단백질 패밀리에서 발현이 잘 되는 인공 단백질을 생성할 수 있으며, 자연 단백질과 유사한 기능을 할 수 있습니다.
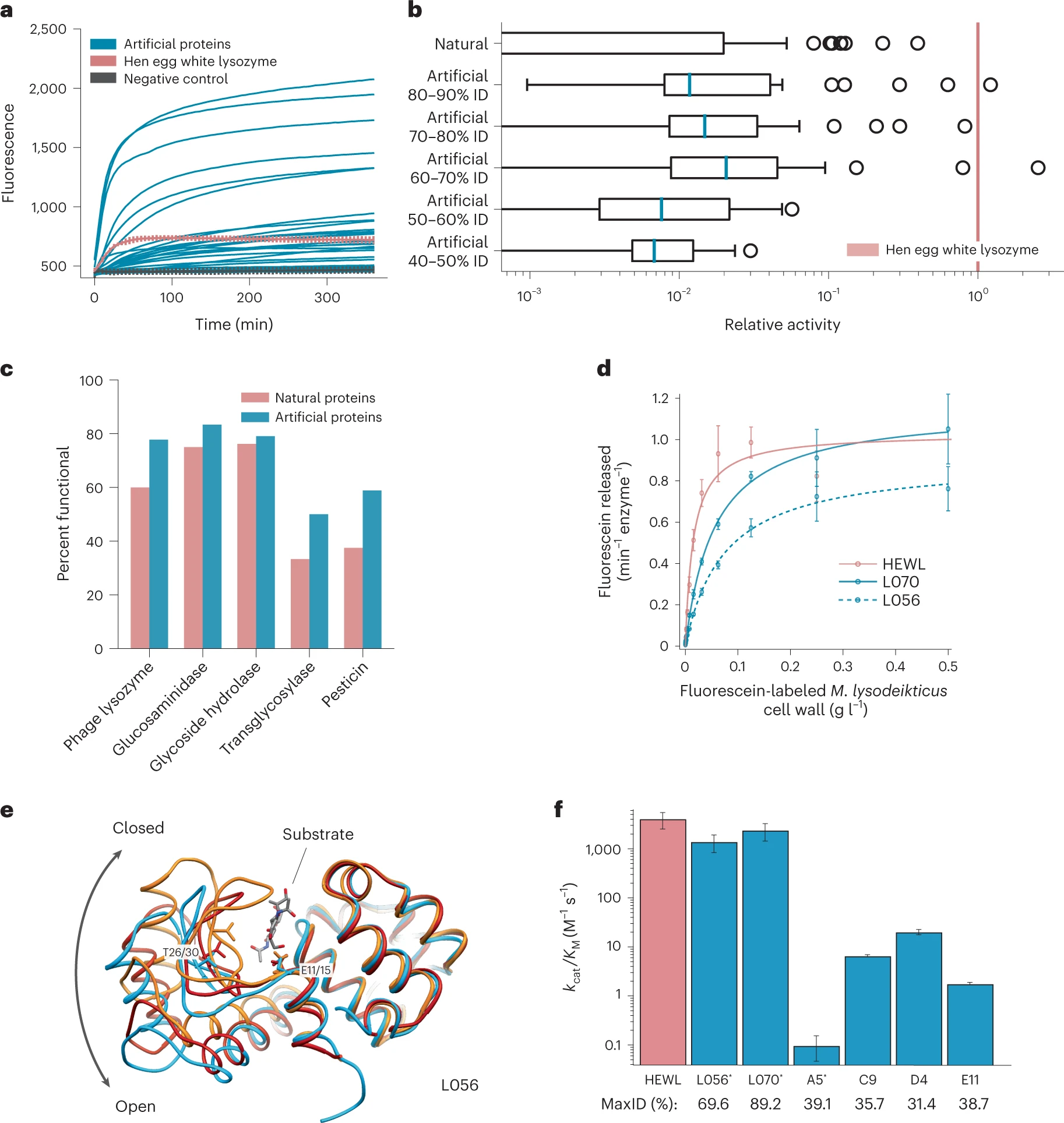
Figure 3: Artificial protein sequences are functional while reaching as low as 31% identity to any known protein
이 그림에서는 ProGen이 생성한 단백질의 기능성을 검증합니다.
- 3a: ProGen이 생성한 단백질들이 기질과 잘 결합하고, 높은 수준의 형광 반응을 나타내는 것을 보여줍니다. 이는 이들 단백질이 효소 기능을 잘 수행함을 의미합니다.
- 3b: 자연 단백질과 서열 유사성이 낮은(최대 31%까지) 인공 단백질도 활성을 유지할 수 있음을 시사합니다.
- 3c: 다양한 단백질 계통에서 생성된 인공 단백질이 기능을 유지함을 나타냅니다. 인공 단백질의 73%가 자연 단백질과 유사한 효소 활성도를 보였습니다.
- 3d: Michaelis–Menten kinetic 분석을 통해 ProGen이 생성한 두 가지 Lysozyme(L056, L070)이 자연 Lysozyme과 유사한 촉매 효율을 보이는 것을 보여줍니다.
- 3e: 인공 단백질 L056의 결정 구조를 통해, 생성된 단백질이 예상한 구조와 유사한 형태로 접히며, 기능적 활성 부위를 잘 형성하고 있음을 보여줍니다.
- 3f: 서열 유사도가 낮은 인공 단백질도 일정 수준의 효소 활성을 보였으나, 그 효율은 자연 단백질에 비해 낮았습니다.
핵심 내용: ProGen이 생성한 단백질은 자연 단백질과 서열 유사도가 낮아도 기능을 유지할 수 있으며, 높은 효소 활성을 보이는 경우도 있습니다. 결정 구조 분석 결과, 생성된 단백질이 올바르게 접힘을 확인했습니다.
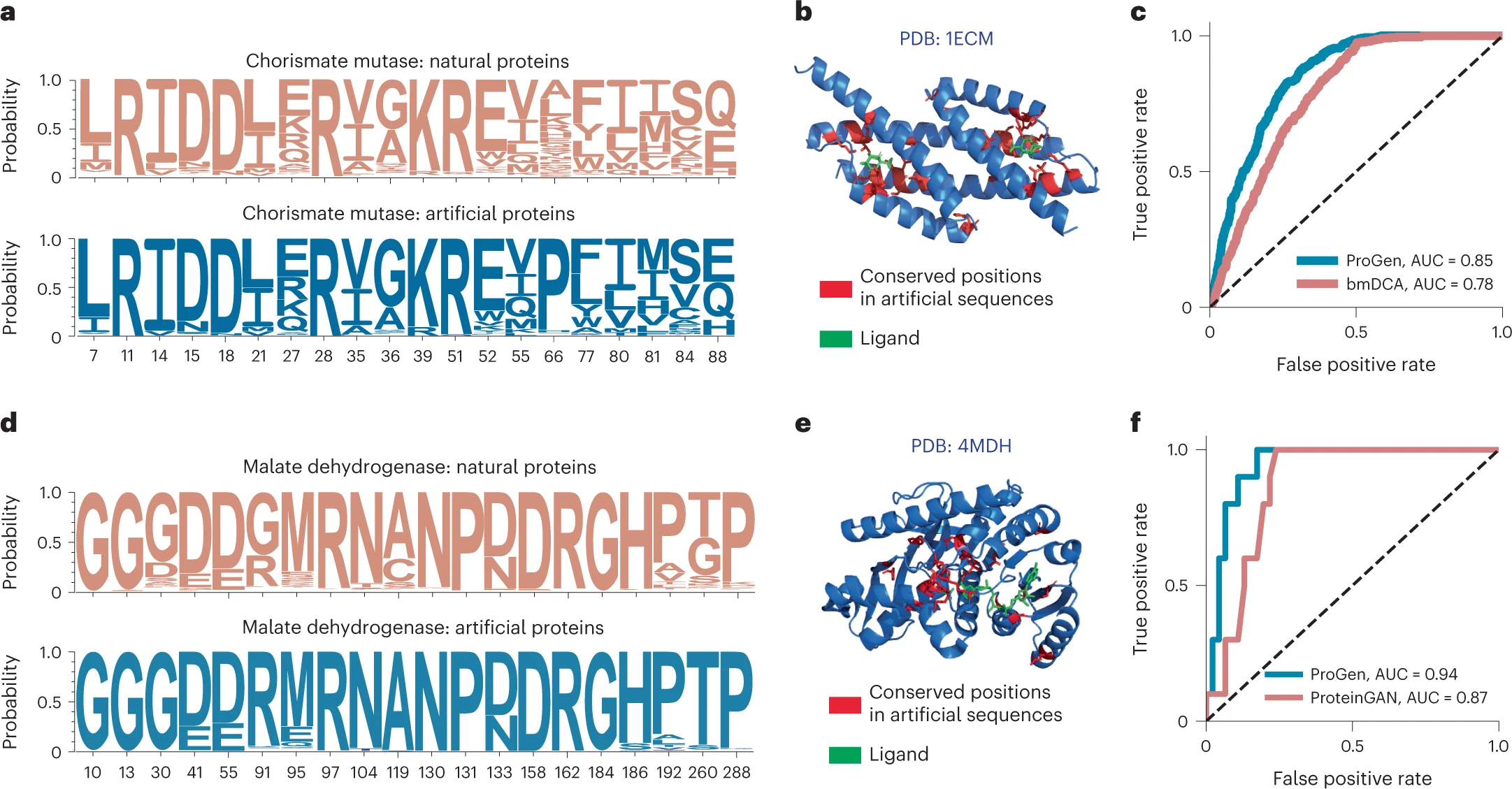
Figure 4: Applicability of conditional language modeling to other protein systems
이 그림에서는 ProGen 모델이 다양한 단백질 패밀리(Lysozyme 외의 계통)에서 어떻게 적용될 수 있는지 보여줍니다.
- 4a, 4d: ProGen이 생성한 Chorismate mutase(CM)와 Malate dehydrogenase(MDH) 단백질의 서열 보존 패턴이 자연 서열과 유사하다는 것을 보여줍니다.
- 4b, 4e: CM과 MDH 단백질에서 생성된 서열이 리간드 결합 부위나 매몰된 잔기 등 중요한 위치에서 자연 서열과 일치하는 패턴을 보입니다.
- 4c, 4f: ProGen이 생성한 서열의 기능성을 예측한 결과, CM과 MDH에서 ProGen이 기존의 단백질 설계 방법보다 더 높은 예측 성능(AUC 0.85 및 0.94)을 보였습니다. 특히 기존 방법인 bmDCA와 ProteinGAN보다 우수한 성능을 나타냈습니다.
핵심 내용: ProGen은 Lysozyme뿐만 아니라 CM, MDH와 같은 다른 단백질 계통에서도 높은 기능성 예측 성능을 보입니다. 기존의 공진화 모델이나 GAN 기반 방법보다 더 좋은 성능을 발휘합니다.
Results 부분 핵심 내용 요약:
- ProGen은 다양한 단백질 계통에서 자연 단백질과 유사하거나 그 이상의 성능을 보이는 인공 단백질을 생성할 수 있습니다.
- 생성된 단백질은 서열 유사도가 낮아도 기능을 유지하며, 실험적으로도 높은 발현율과 기능성을 나타냅니다.
- ProGen은 Lysozyme 외에도 다양한 단백질 계통에서 우수한 성능을 발휘하며, 기존의 단백질 설계 방법을 능가할 수 있습니다.
Methods 부분에서는 ProGen 모델의 학습 과정, 실험 절차 및 데이터 수집 방법 등을 다룹니다. 이 부분의 핵심 내용을 정리하고, 수식도 설명하겠습니다.
핵심 내용 정리:
-
Training Data Curation (학습 데이터 수집):
- ProGen 모델은 280억 개의 단백질 서열과 19,000개 이상의 단백질 패밀리를 포함한 대규모 데이터셋을 사용해 학습되었습니다.
- UniParc, UniprotKB, Pfam, NCBI Taxonomy 등 다양한 데이터베이스에서 수집된 서열 데이터와 함께, 각 서열에 대한 메타데이터(예: 단백질 패밀리, 생물학적 과정, 분자 기능 등)를 control tags로 추가하여 학습합니다.
- 학습 데이터는 training set과 두 개의 test set(in-domain test set, out-of-distribution test set)으로 나뉘며, 각각 100만 개와 10만 개의 서열로 구성됩니다.
-
Conditional Language Modeling (조건부 언어 모델링):
- ProGen은 트랜스포머 기반의 언어 모델로, 각 단백질 서열을 예측하기 위한 모델링을 수행합니다. 이를 통해 다음 아미노산을 예측하고, 이를 바탕으로 전체 서열을 생성할 수 있습니다.
- control tags는 단백질의 패밀리, 생물학적 기능, 분자 기능 등을 포함하며, 모델이 원하는 특성을 가진 단백질 서열을 생성하는 데 중요한 역할을 합니다.
-
Model Architecture (모델 구조):
- ProGen은 12억 개의 파라미터로 구성된 트랜스포머(Transformer) 아키텍처를 사용하며, 36개의 레이어와 8개의 self-attention heads로 이루어져 있습니다.
- 모델은 매번 다음 아미노산을 예측하는 방식으로 학습되며, 이를 통해 단백질 서열을 왼쪽에서 오른쪽으로 순차적으로 생성합니다.
-
Fine-tuning (세부 조정):
- ProGen은 전체 데이터셋을 먼저 학습한 후, 특정 단백질 패밀리(예: Lysozyme, Chorismate mutase, Malate dehydrogenase)에 대한 서열로 세부 조정(fine-tuning)됩니다.
- 세부 조정 과정에서는 주어진 패밀리의 서열과 control tag를 입력으로 하여, 해당 패밀리 내에서 더 정확한 서열을 생성하도록 모델을 미세 조정합니다.
-
Sequence Selection (서열 선택):
- ProGen이 생성한 서열 중에서 특정 기준에 따라 서열을 선택하는 과정이 포함됩니다. log-likelihood와 discriminator score를 사용해 서열의 품질을 평가하고, 그중 최적의 서열을 선택합니다.
논문 수식:
식 1: 언어 모델의 음의 로그 우도 (Negative Log-Likelihood)
- 설명:
- 이 수식은 ProGen 모델이 학습되는 목표 함수인 음의 로그 우도(Negative Log-Likelihood)를 나타냅니다.
- 는 학습 데이터셋이고, 는 번째 서열에서 번째 위치의 아미노산입니다.
- 는 모델의 파라미터 에 따른 다음 아미노산을 예측하는 확률을 의미합니다.
- 이 수식을 최소화하는 것이 ProGen 모델의 목표이며, 서열 내에서 앞서 예측한 아미노산들 에 기초하여 번째 아미노산 의 확률을 예측합니다.
식 2: 서열 선택 시 log-likelihood 점수
- 설명:
- 이 수식은 특정 서열 의 log-likelihood 점수를 계산하는 방법을 나타냅니다.
- 는 번째 아미노산 가 앞서 예측된 서열 와 주어진 control tag 에 따라 예측된 확률입니다.
- 이 점수는 서열이 모델에 의해 얼마나 "자연스럽게" 생성되었는지를 나타내며, log-likelihood 값이 높을수록 더 자연스러운 서열임을 의미합니다.
식 3: 상대적 활성도 계산
- 설명:
- 이 수식은 생성된 단백질의 상대적 효소 활성을 계산합니다.
- 과 은 각각 생성된 단백질과 Hen Egg White Lysozyme(HEWL)의 반응 속도를 나타냅니다.
- 과 은 각각 HEWL과 생성된 단백질의 질량입니다.
- 이 수식을 통해 실험된 단백질이 표준 단백질(HEWL)에 비해 얼마나 효소 활성이 있는지 상대적으로 비교할 수 있습니다.
식 4: Michaelis-Menten 식
- 설명:
- 이 식은 Michaelis-Menten 효소 반응 속도 방정식으로, 효소가 기질과 반응하여 생성물을 형성하는 속도를 나타냅니다.
- 는 반응 속도, 는 효소의 촉매 전환율, 는 기질의 농도, 은 기질의 반응 속도를 절반으로 만드는 기질 농도입니다.
- 이 식을 사용하여 생성된 단백질이 얼마나 효율적으로 기질과 반응하는지 측정할 수 있습니다.
식 5: Pseudo-first-order kinetics
- 설명:
- 이 식은 기질의 농도가 매우 낮을 때, 효소 반응 속도를 단순화한 형태로 나타낸 Pseudo-first-order 반응 속도 방정식입니다.
- 는 관찰된 반응 속도 상수, 은 효소 농도입니다.
- 이 식을 통해 효소의 기질 전환 효율을 계산할 수 있습니다.
식 6: 이중 지수 함수 모델 (Double Exponential Model)
- 설명:
- 이 식은 반응이 이중 지수 함수적으로 변화하는 것을 설명합니다. 주로 반응 시간이 길거나 기질이 이질적일 때, 반응 속도를 설명하는 데 사용됩니다.
- 는 두 지수 함수의 시간 상수입니다.
식 7: 의 역수 계산
- 설명:
- 이 식은 의 역수를 이중 지수 모델로 계산하는 방법을 나타냅니다. 각 시간 상수와 진폭의 비율을 사용해 최종적으로 반응 속도를 추정합니다.
핵심 정리:
-
ProGen 모델은 대규모 단백질 서열 데이터로 학습되어, 특정 control tag를 통해 다양한 단백질 패밀리에서 기능적 단백질을 생성할 수 있습니다.
-
음의 로그 우도(Negative Log-Likelihood)를 최소화하는 방식으로 학습되며, 이로써 주어진 단백질 서열을 정확하게
생성합니다.
-
Michaelis-Menten 방정식 및 Pseudo-first-order 반응 속도를 사용하여 실험적으로 생성된 단백질의 효소 활성을 평가하며, 이를 통해 모델의 성능을 실험적으로 검증합니다.
논문의 구조 예측 부분과 실제 모델 생성 방법은 주로 ProGen 모델을 통해 생성된 단백질 서열의 3차원 구조를 예측하는 과정과, 실험적으로 생성된 단백질의 결정 구조를 분석하는 방법으로 나뉩니다. 여기서는 이 두 가지 주요 과정을 각각 설명하겠습니다.
1. 구조 예측 (Structure Prediction)
ProGen이 생성한 인공 단백질의 구조 예측은 AlphaFold2 모델을 사용하여 수행되었습니다. 이 방법은 단백질 서열을 입력으로 받아, 해당 서열의 3차원 구조를 예측하는 방식입니다. AlphaFold2는 현재 단백질 구조 예측에서 매우 높은 정확도를 자랑하는 모델입니다.
-
AlphaFold2 사용:
AlphaFold2를 single-sequence mode로 사용했으며, 이는 다중 서열 정렬(MSA) 없이 단일 서열만을 사용하여 예측을 수행하는 방식입니다. MSA 정보 없이 구조를 예측한 이유는 생성된 인공 단백질 서열이 기존의 자연 서열과 매우 다른 경우가 많기 때문입니다. MSA가 없는 상태에서도 AlphaFold2는 생성된 서열의 구조를 예측할 수 있지만, MSA가 포함된 예측에 비해 정확도는 다소 낮아질 수 있습니다. -
AlphaFold2 설정:
- 템플릿 기반 예측(With PDB Templates): PDB(Protein Data Bank)에서 알려진 구조를 템플릿으로 사용하여 예측을 진행하였습니다.
- 리사이클 횟수(Recycles): AlphaFold2는 단백질 구조 예측을 여러 차례 반복(recycles)하여 정확도를 높일 수 있는데, 이 논문에서는 12번의 리사이클을 사용하여 최종 구조를 예측했습니다.
-
다양한 설정 테스트:
- 템플릿을 사용하지 않고 다양한 설정(1~48번의 리사이클)을 시도하였지만, 생성된 인공 서열에서 신뢰할 만한 구조는 얻지 못했습니다. 따라서 템플릿이 포함된 예측을 통해 신뢰성 높은 구조를 확보하였습니다.
-
구조 예측 실패 사례:
AlphaFold2를 사용하여 예측한 여러 인공 서열 중 일부는 pLDDT(local distance difference test) 점수가 60 미만으로 나와 신뢰성이 낮은 것으로 평가되었습니다. 이는 해당 인공 서열이 자연 서열과 너무 달라서 예측에 어려움이 있었음을 나타냅니다.
2. 실제 모델 생성 및 구조 결정 실험 (Crystallization and Structure Determination)
실험적으로 생성된 단백질 중 일부는 결정화하여 실제 구조를 확인하는 절차를 거쳤습니다. 이 과정은 주로 X-선 결정학(X-ray crystallography)을 통해 수행되었으며, 이를 통해 결정 구조를 분석할 수 있었습니다.
-
결정화(Crystallization):
생성된 단백질 중 L056은 18.6 mg/mL 농도로 농축된 상태에서, sitting drop vapor diffusion 방법을 사용해 20°C에서 결정화되었습니다. 결정을 생성하기 위한 용액은 0.1 M CHES (pH 9.5)와 30% w/v PEG 3000을 포함한 용액이었습니다. -
X-선 회절 데이터 수집(X-ray Diffraction Data Collection):
L056 단백질의 결정은 Advanced Light Source(Beamline 8.3.1)에서 수집되었으며, 회절 데이터를 분석하기 위해 XDS 소프트웨어를 사용하였습니다. -
모델 생성(Model Building):
회절 데이터를 이용해 초기 모델은 trRosetta로 생성된 예측 구조를 사용하여 Phaser로 해결하였으며, 이를 통해 초기 결정 구조를 얻었습니다. 이후 Refmac과 Phenix 소프트웨어를 사용하여 구조를 정제(refine)하고, Coot을 통해 수동으로 모델을 수정하였습니다. 최종적으로 결정 구조는 2.5 Å 해상도로 확인되었습니다. -
비결정학적 대칭성 문제 해결:
결정화 과정에서 상당한 translational non-crystallographic symmetry(비결정학적 대칭성) 문제가 발생했지만, 이를 해결하기 위해 여러 차례의 구조 수정이 이루어졌습니다. -
구조 분석 결과:
생성된 L056 단백질의 구조는 자연에서 발견되는 T4 Lysozyme의 구조와 유사한 형태를 가지고 있음을 확인하였습니다. 특히, 활성 부위가 잘 형성되었으며, 촉매에 중요한 글루탐산(Glu15)과 트레오닌(Thr30) 잔기가 정확한 위치에 자리하고 있음을 확인했습니다.
결론
-
구조 예측:
AlphaFold2 모델을 사용해 ProGen이 생성한 단백질 서열의 3차원 구조를 예측하였으며, 일부는 신뢰성 있는 구조를 제공했으나, 서열이 자연 서열과 크게 다른 경우에는 정확한 예측이 어려운 경우도 있었습니다. -
실험적 구조 결정:
ProGen이 생성한 L056과 같은 단백질 서열은 실험적으로 결정화하여 X-선 결정학을 통해 정확한 3차원 구조를 확인하였으며, 자연 단백질과 유사한 활성 부위 및 구조를 가짐을 증명하였습니다.
이 과정을 통해 ProGen이 생성한 단백질 서열이 기능적일 뿐만 아니라, 구조적으로도 안정적임을 확인할 수 있었습니다.
