구글 빅쿼리는 간단하게 말하면 그냥 데이터 웨어하우스입니다. 수십 테라바이트 페타바이트 단위 데이터를 다루려면 힘드니까
쿼리로 관리하는거에요. SQL이랑 차이점도 잘 모르겠습니다. 명령어가 SQL이랑 같아가지고
우선 데이터셋은 알파폴드 데이터베이스에서 가져왔습니다.
데이터셋 링크
실험에 사용하려고 데이터셋을 다운로드 받는데 하다가 고생좀 했습니다.
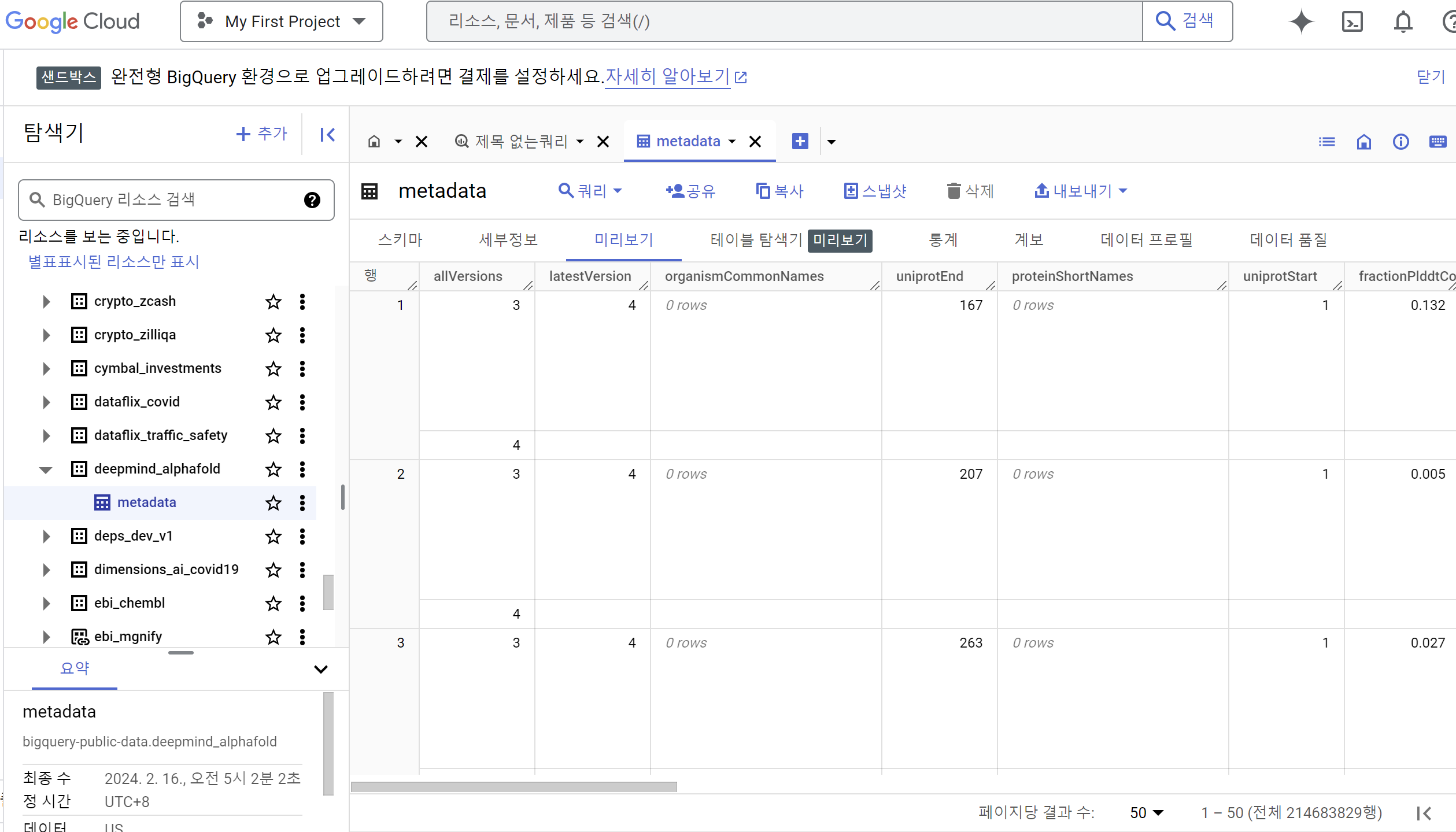
빅쿼리로 들어가면 다음과 같이 metadata를 볼 수 있어요. 이제 해봅시다.
1. 우선 파이썬으로 big query를 설치합니다.
!pip install google-cloud-bigquery
2. 해당 코드를 실행시켜봅시다.
실행하면 우선 로그인 하라고 나올건데 로그인 하고 가이드 따라서 등록하시면 됩니다.
동시에 두개 이상의 계정을 등록하면 가끔 새로 등록한 계정이
권한 없다고 이것저것 등록하라고 나오는데, 그럴땐 그냥 로그아웃 하고 다시 로그인 하면 해결됩니다.
(2시간정도 이걸로 고생함)
from google.cloud import bigquery # 구글 클라우드의 BigQuery 클라이언트를 임포트
from google.cloud import storage # 구글 클라우드의 Cloud Storage 클라이언트를 임포트gcloud config set project 본인 프로젝트 이름
2-1. 만약에 Quota Warning이 나왔을 때
WARNING: Your active project does not match the quota project in your local Application Default Credentials file. This might result in unexpected quota issues.
해결방법:
gcloud auth application-default set-quota-project 내 프로젝트 이름
gcloud config list
해당 명령어를 사용하여 현재 설정된 프로젝트와 ADC 할당량 프로젝트가 일치하는지 확인할 수 있습니다.
2-2 ERROR: (gcloud.auth.application-default.set-quota-project) [메일주소] does not have permission to access projects instance (여전히 권한이 부족하다 나옴)
해결방안
.
gcloud auth application-default set-quota-project 본인 프로젝트 명령을 실행할 때 발생하는 오류는 권한과 관련된 문제입니다. 이 오류 메시지에 따르면, 본인 메일 계정에 본인 프로젝트 프로젝트에 대한 필요한 IAM 권한이 여전히 부족하다고 되어있는데. 그런데 get-iam-policy 명령어 결과에서는 roles/serviceusage.serviceUsageConsumer 역할이 이미 부여되어 있는 상태.
Application Default Credentials(ADC)의 문제
-
Application Default Credentials 파일 자체에 문제가 있을 수 있습니다. 이 파일은
gcloud auth application-default login을 통해 설정됩니다.해결 방법: 현재 설정된 Application Default Credentials(ADC)를 제거하고, 다시 설정해봅니다.
-
현재 ADC 인증 제거:
gcloud auth application-default revoke -
다시 로그인하여 ADC 설정:
gcloud auth application-default login이 명령을 실행하면 브라우저 창이 열리면서 Google 계정으로 다시 로그인하게 됩니다.
-
할당량 프로젝트 설정 다시 시도:
gcloud auth application-default set-quota-project 본인 프로젝트ID
3. 프로젝트 활성화 확인
프로젝트가 제대로 활성화되지 않았을 가능성도 있습니다. 프로젝트가 비활성화된 경우 API 호출이 거부될 수 있습니다. 프로젝트 상태 확인은 다음과 같이 가능합니다:
gcloud projects describe 본인 프로젝트ID프로젝트가 활성화되어 있는지 확인하세요. 만약 비활성화된 상태라면 Google Cloud Console에서 프로젝트를 활성화할 수 있습니다.
4. 할당량 및 청구 관련 문제
프로젝트가 Google Cloud의 청구가 활성화되지 않았거나, 할당량 사용이 차단된 경우에도 문제가 발생할 수 있습니다. Cloud Billing 설정을 확인해야 합니다.
- Google Cloud Console에서 청구 페이지로 이동합니다.
- 프로젝트
본인 프로젝트 이름가 올바르게 청구 설정이 되어 있는지 확인합니다. - 청구가 활성화되어 있지 않으면 프로젝트에서 BigQuery나 기타 API를 사용하지 못할 수 있습니다.
2.3 description: Google developers console API activation
2.2가 아마 위에 명령어를 실행하면 해결 될겁니다.
현재 발생한 오류 메시지는 Service Usage API가 프로젝트에서 활성화되지 않았기 때문에 발생한 것입니다. 이를 해결하려면 Service Usage API를 활성화해야 합니다. 다음 단계에 따라 문제를 해결할 수 있습니다.
1. Service Usage API 활성화
Google Cloud 프로젝트에서 Service Usage API를 활성화해야 합니다. 이 API는 프로젝트에서 다른 API를 사용하기 위해 필요한 권한을 제공합니다.
방법 1: Google Cloud Console을 통해 활성화
- 브라우저를 열고 아래 URL로 이동합니다:
Service Usage API 활성화 링크 - API 사용 설정 버튼을 클릭하여 Service Usage API를 활성화합니다.
- API가 활성화되면 몇 분 기다렸다가 다시 명령어를 실행하세요.
방법 2: gcloud 명령어를 통해 활성화
또는 gcloud 명령어를 사용하여 Service Usage API를 활성화할 수 있습니다:
gcloud services enable serviceusage.googleapis.com --project=alpha-436815이 명령을 실행하면 API가 활성화됩니다.
2. cloudresourcemanager API 활성화
오류 메시지에서 cloudresourcemanager.googleapis.com API가 활성화되지 않았다는 내용도 있습니다. 이 API도 필요하기 때문에 함께 활성화해야 합니다.
방법 1: Google Cloud Console을 통해 활성화
- 브라우저를 열고 아래 URL로 이동합니다:
Cloud Resource Manager API 활성화 링크 - API 사용 설정 버튼을 클릭하여 Cloud Resource Manager API를 활성화합니다.
- API가 활성화되면 다시 명령어를 실행하세요.
방법 2: gcloud 명령어를 통해 활성화
gcloud 명령어를 사용하여 cloudresourcemanager.googleapis.com API를 활성화할 수 있습니다:
gcloud services enable cloudresourcemanager.googleapis.com --project=프로젝트IDAPI 활성화 후 다시 시도
API가 활성화되고 나면, 몇 분 정도 기다렸다가 아래 명령어를 다시 실행해 보세요:
gcloud auth application-default set-quota-project 프로젝트ID아마 이렇게 하면 해결될겁니다.
3.코드 실행
from google.cloud import bigquery # 구글 클라우드의 BigQuery 클라이언트를 임포트
from google.cloud import storage # 구글 클라우드의 Cloud Storage 클라이언트를 임포트
import os # 파일 경로를 다루기 위한 기본 파이썬 모듈
# BigQuery와 Cloud Storage 클라이언트를 초기화
# '본인 프로젝트' 부분을 본인의 구글 클라우드 프로젝트 ID로 대체해야 합니다.
bq_client = bigquery.Client(project='본인 프로젝트') # BigQuery 클라이언트 초기화
storage_client = storage.Client(project='본인 프로젝트') # Cloud Storage 클라이언트 초기화
# 데이터셋과 테이블 정보 설정
dataset_id = 'temp_dataset' # 생성할 BigQuery 데이터셋 이름
table_id = f'본인 프로젝트.{dataset_id}.alphafold_results_sorted' # BigQuery 테이블 ID
bucket_name = 'alpha_chunk' # Cloud Storage에서 사용할 버킷 이름 (버킷은 GCS에서 생성해야 함)
# 클러스터링된 테이블 생성 함수
def create_clustered_table():
global bq_client # 함수 내에서 전역적으로 BigQuery 클라이언트 사용
# 테이블 스키마 정의 (각 필드의 이름과 데이터 타입을 지정 본인이 하고싶은걸로 지정하면 됩니다.)
schema = [
bigquery.SchemaField("uniprotAccession", "STRING"), # 문자열 타입 필드
bigquery.SchemaField("uniprotEnd", "INTEGER"), # 정수 타입 필드
bigquery.SchemaField("uniprotSequence", "STRING"), # 문자열 타입 필드
bigquery.SchemaField("globalMetricValue", "FLOAT") # 실수 타입 필드
]
# 테이블 옵션 설정 (테이블을 클러스터링하는 필드 설정)
table = bigquery.Table(table_id, schema=schema) # 테이블 객체 생성
table.clustering_fields = ["uniprotAccession"] # 클러스터링 기준 필드 설정 (uniprotAccession 기준으로 클러스터링)
# 테이블을 생성 (이미 테이블이 존재하면 무시)
table = bq_client.create_table(table, exists_ok=True) # 테이블이 존재하는지 확인하고 없으면 생성
print(f"Table {table.project}.{table.dataset_id}.{table.table_id} is ready.") # 테이블 준비 완료 메시지 출력
# 테이블이 비어 있는지 확인
table_info = bq_client.get_table(table) # 테이블 정보를 가져옴
if table_info.num_rows > 0: # 테이블에 데이터가 이미 존재하는지 확인
print("Table already has data. Skipping data insertion.") # 데이터가 있으면 데이터 삽입을 건너뜀
return # 함수 종료
# 테이블에 데이터를 삽입하는 쿼리 정의 (데이터 소스는 DeepMind의 Alphafold 메타데이터 테이블)
insert_query = f"""
INSERT INTO `{table_id}`
(uniprotAccession, uniprotEnd, uniprotSequence, globalMetricValue)
SELECT
uniprotAccession,
uniprotEnd,
uniprotSequence,
globalMetricValue
FROM
`bigquery-public-data.deepmind_alphafold.metadata`
"""
# 쿼리 실행
query_job = bq_client.query(insert_query) # 정의된 쿼리를 실행하여 테이블에 데이터 삽입
query_job.result() # 쿼리 작업이 완료될 때까지 대기
print("Data inserted into the clustered table successfully.") # 데이터 삽입 성공 메시지 출력
# 테이블을 GCS(Google Cloud Storage)에 내보내는 함수
def export_table_to_gcs():
global bq_client # 함수 내에서 전역적으로 BigQuery 클라이언트 사용
# 내보낼 GCS 파일의 경로 설정 (GCS 버킷 내에 JSON 파일 형식으로 저장)
destination_uri = f"gs://{bucket_name}/alphafold_results_*.json.gz" # GCS 버킷에 저장될 경로 및 파일명 설정
dataset_ref = bigquery.DatasetReference(bq_client.project, dataset_id) # 데이터셋 참조 생성
table_ref = dataset_ref.table("alphafold_results_sorted") # 내보낼 테이블 참조 생성
# 내보내기 작업에 대한 설정 (JSON 형식, GZIP 압축 사용)
job_config = bigquery.ExtractJobConfig()
job_config.destination_format = bigquery.DestinationFormat.NEWLINE_DELIMITED_JSON # JSON 형식으로 내보냄
job_config.compression = bigquery.Compression.GZIP # 데이터를 GZIP으로 압축하여 내보냄
# 테이블을 GCS로 내보내는 작업 실행
extract_job = bq_client.extract_table(
table_ref,
destination_uri,
job_config=job_config # 설정을 적용하여 작업 실행
)
extract_job.result() # 내보내기 작업이 완료될 때까지 대기
print(f"Exported {table_id} to {destination_uri}") # 내보내기 완료 메시지 출력
# 메인 함수 (전체 흐름을 관리)
def main():
try:
# 데이터셋이 존재하지 않으면 생성
dataset = bigquery.Dataset(f"{bq_client.project}.{dataset_id}") # 데이터셋 참조 생성
dataset.location = "US" # 데이터셋의 위치를 미국으로 설정
bq_client.create_dataset(dataset, exists_ok=True) # 데이터셋이 없으면 생성, 있으면 무시
print(f"Dataset {dataset_id} created or already exists.") # 데이터셋 생성 또는 이미 존재한다는 메시지 출력
# 클러스터링된 테이블을 생성하고 데이터를 삽입
create_clustered_table() # 클러스터링된 테이블 생성 및 데이터 삽입
# 생성된 테이블을 GCS로 내보냄
export_table_to_gcs() # 테이블 데이터를 GCS로 내보내기
print("Data exported to GCS successfully.") # 내보내기 성공 메시지 출력
except Exception as e:
# 예외가 발생하면 에러 메시지 출력
print(f"An error occurred: {e}") # 에러 메시지를 출력
# 파이썬 스크립트가 직접 실행될 때만 main() 함수 실행
if __name__ == "__main__":
main() # main 함수 호출
4. 결과확인
Dataset tempdataset created or already exists.
Table alpha-436815.temp_dataset.alphafold_results_sorted is ready.
Table already has data. Skipping data insertion.
Exported alpha.temp_dataset.alphafold_results_sorted to gs://alpha_chunk/alphafold_results*.json.gz
Data exported to GCS successfully.
이런식으로 나오면 성공입니다.
5. 내 PC로 파일 다운로드 받기
from google.cloud import storage
import os
import zipfile
from tqdm import tqdm
def download_and_zip(bucket_name, local_download_path, zip_file_name):
# Initialize the Google Cloud Storage client
storage_client = storage.Client()
# Get the bucket
bucket = storage_client.bucket(bucket_name)
# List all blobs in the bucket
blobs = bucket.list_blobs()
# Ensure the local download directory exists
if not os.path.exists(local_download_path):
os.makedirs(local_download_path)
# Download blobs to local directory
print("Starting download of files from GCS...")
file_paths = []
for blob in tqdm(blobs, desc="Downloading files"):
# Define the local file path
local_file_path = os.path.join(local_download_path, blob.name)
# Create directories if they do not exist
os.makedirs(os.path.dirname(local_file_path), exist_ok=True)
# Download the blob
blob.download_to_filename(local_file_path)
file_paths.append(local_file_path)
print("Download complete.")
# Create a ZIP file
print(f"Compressing files into {zip_file_name}...")
with zipfile.ZipFile(zip_file_name, 'w', zipfile.ZIP_DEFLATED) as zipf:
for file in tqdm(file_paths, desc="Adding files to ZIP"):
# Add file to the ZIP archive
zipf.write(file, arcname=os.path.relpath(file, local_download_path))
print(f"All files have been compressed into {zip_file_name}.")
# Optionally, delete the local files after zipping
# import shutil
# shutil.rmtree(local_download_path)
# print("Local files have been deleted after zipping.")
def main():
# Configuration
bucket_name = '본인 버킷이름'
local_download_path = '본인 경로'
zip_file_name = '본인 파일이름.zip'
download_and_zip(bucket_name, local_download_path, zip_file_name)
if __name__ == "__main__":
main()
후기
무료버전이나 300달러 용량 줘서 할 때
Query실행할 때 sorting이라던가 그런거 리소스 많이 잡아먹으니까 하지 마세요 3시간동안 progress bar 멈춰있는거 보고 무언가 잘못됐음을 느꼈습니다.
막 욕심내서 한 번에 100기가 1테라 받고 그러는거 의미 없어요 그냥 대충 1~2GB 짜리 블록으로 쪼개서 수십 수백개로 나눠서 관리하는게 제일 좋습니다.
상당히 무식하게 해서 안 따라 하시는게 좋습니다. 쿼리쪽도 공부를 해야겠네요.
출처:
https://cloud.google.com/bigquery/docs/python-libraries?hl=ko
GPT4
