alpha proteo랑 같은 종류의 de novo 단백질 생성 모델입니다.
논문 요약:
이 논문은 ProtGPT2라는 딥러닝 기반의 언어 모델을 통해 단백질 디자인 문제를 해결하려는 시도를 다루고 있습니다. 최근 자연어 처리(NLP)에서 Transformer 기반 아키텍처가 사람처럼 자연스러운 텍스트를 생성하는 데 성공하면서, 이를 단백질 서열 생성에도 적용할 수 있다는 아이디어를 발전시켰습니다. 단백질 서열은 자연어와 유사하게 정보를 압축하고, 서열의 배열에 따라 구조와 기능이 정해지므로, 이러한 NLP 기법을 단백질 디자인에 활용할 수 있다는 것입니다.
핵심 내용:
-
ProtGPT2는 약 5천만 개의 단백질 서열을 학습하여 de novo 단백질 서열을 생성할 수 있는 자율회귀(autoregressive) Transformer 모델입니다. 이 모델은 자연적으로 발생하는 단백질의 아미노산 특성을 모방하며, 특히 글로불린 구조를 갖춘 단백질을 주로 생성합니다.
-
ProtGPT2가 생성하는 단백질 서열은 기존의 자연 단백질과 진화적으로 멀리 떨어져 있지만, 여전히 자연 단백질과 유사한 기능과 구조를 보입니다. 이 모델은 단백질 구조 데이터베이스에 없는 새로운 영역의 단백질 서열을 탐색할 수 있다는 점에서 주목할 만합니다.
-
AlphaFold로 ProtGPT2가 생성한 단백질 서열의 구조를 예측한 결과, 상당수의 단백질이 안정적인 접힘 구조를 가지며, 긴 루프와 새로운 토폴로지를 포함한 복잡한 3D 구조를 형성하는 것으로 나타났습니다. 이는 ProtGPT2가 단백질 디자인 분야에서의 새로운 가능성을 열었다는 의미가 있습니다.
-
ProtGPT2는 특정 단백질 패밀리나 기능에 맞춰 세밀하게 조정(fine-tuning) 될 수 있으며, 단백질 서열을 고속으로 생성할 수 있기 때문에 환경 문제나 의료 문제 해결을 위한 단백질 엔지니어링에 유용하게 사용될 수 있습니다.
Results
1. Learning the protein language (단백질 언어 학습)
이 부분에서는 ProtGPT2가 어떻게 단백질 서열을 학습하고, 이를 통해 de novo 단백질을 생성하는지를 설명하고 있습니다. 단백질 서열은 특정한 의미를 가지는 단어 또는 문장처럼 해석될 수 있는데, 이러한 서열에서의 각 아미노산은 언어 모델에서의 단어와 비슷한 역할을 합니다.
수식 설명:
ProtGPT2는 자율회귀(autoregressive) 모델로 동작합니다. 자율회귀 모델에서는 문맥(context)을 기반으로 다음 단어(또는 아미노산)를 예측합니다. 즉, 주어진 아미노산 서열에서, 그 이전 서열을 기반으로 다음 아미노산이 무엇일지를 예측하는 방식입니다. 이를 표현하는 수식은 다음과 같습니다:
여기서:
- 는 서열 W의 전체 확률입니다.
- 는 서열에서의 i번째 아미노산입니다.
- 는 이전 아미노산들의 서열을 의미합니다.
- 즉, 각 아미노산 의 확률은 그 이전 아미노산 서열 에 의해 결정됩니다.
이 모델은 음의 로그 우도(Negative Log-Likelihood, NLL)를 최소화하는 방식으로 학습됩니다. 이를 수식으로 나타내면 다음과 같습니다:
여기서:
- 은 언어 모델의 손실 함수입니다.
- 는 전체 데이터셋이고, 는 각 데이터 샘플을 의미합니다.
- 는 k번째 단백질 서열에서의번째 아미노산입니다.
- 는 모델의 파라미터를 나타냅니다.
이 과정에서 모델은 UniRef50 데이터베이스를 사용하여 학습되었으며, 약 738백만 개의 파라미터를 가진 36 레이어의 Transformer 모델로 학습되었습니다.
2. Statistical sampling of natural amino acid propensities (자연 아미노산 성향의 통계적 샘플링)
이 부분에서는 ProtGPT2가 단백질 서열을 생성할 때, 자연 단백질 서열과 얼마나 유사한지, 그리고 생성된 서열이 자연 아미노산 분포와 얼마나 잘 일치하는지에 대한 평가가 이루어집니다.
샘플링 전략:
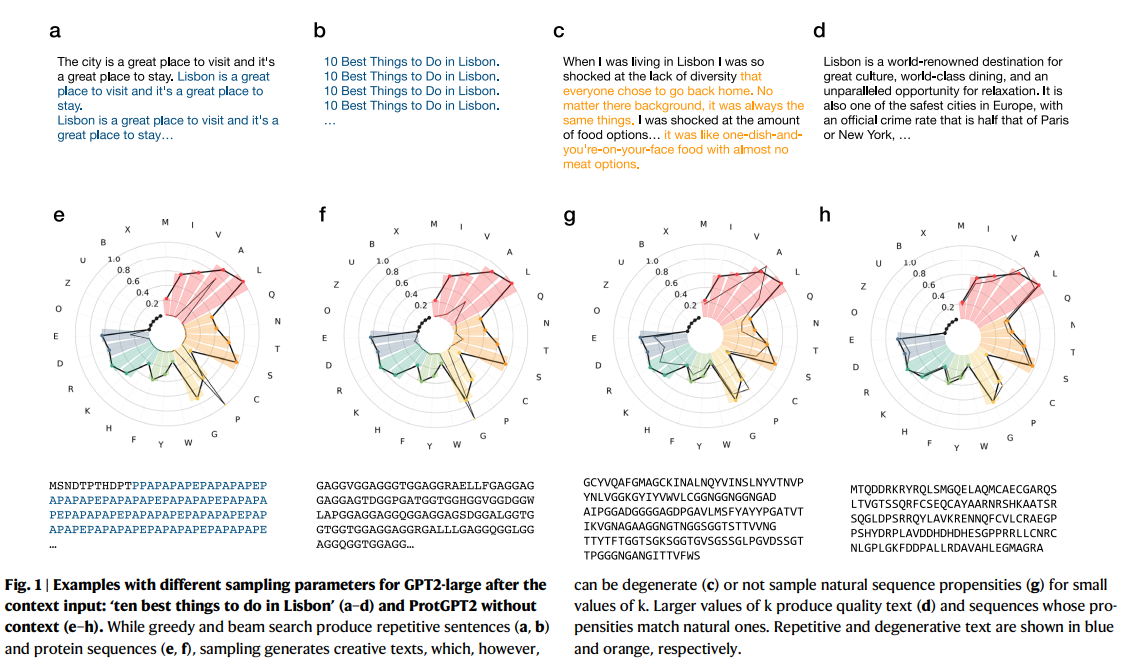
서열 생성에서 사용되는 주요 샘플링 전략으로는 Greedy Search, Beam Search, 그리고 Random Sampling이 있습니다.
- Greedy Search: 각 단계에서 가장 확률이 높은 아미노산을 선택합니다. 이 방법은 간단하지만 서열이 반복적이고 비자연적인 결과를 생성하는 경향이 있습니다.
- Beam Search: 여러 후보를 동시에 고려하여 가장 가능성이 높은 서열을 선택합니다. 그러나 이 방법도 자연적인 다양성을 충분히 확보하지 못할 수 있습니다.
- Random Sampling: 확률적으로 상위개의 아미노산 중 하나를 무작위로 선택합니다. 이 방법은 더 자연스러운 서열을 생성할 수 있지만, 너무 무작위적일 경우 비자연적인 서열이 나올 수 있습니다.
수식 설명:
서열 생성은 조건부 확률 분포에 기반하여 이루어집니다. 즉, 각 아미노산은 그 이전 아미노산들의 맥락에서 확률적으로 선택됩니다. 이 확률 분포는 다음 단어(아미노산)의 조건부 분포로 나눌 수 있으며, 이를 다음과 같이 수식으로 표현합니다:
여기서 는 i번째 아미노산이 이전 아미노산 서열을 고려했을 때의 조건부 확률입니다. 이를 기반으로 서열을 생성하며, 샘플링 파라미터로는 값과 반복 페널티(repetition penalty)를 사용하여 자연 서열과 유사한 분포를 유지하려고 합니다.
연구에서 최적의 결과를 위해 Top-k 샘플링에서을 선택하고, 반복 페널티는 1.2로 설정하여 반복적인 서열 생성을 줄였습니다.
3. ProtGPT2 sequences encode globular proteins
이 부분에서는 ProtGPT2가 생성한 단백질 서열이 주로 글로불린(globular) 단백질 형태를 띠고 있음을 다룹니다. 글로불린 단백질은 구형 구조를 가지며, 자연에서 흔히 발견되는 단백질 구조 중 하나입니다. 논문에서는 이러한 구조가 어떻게 확인되었는지를 설명하고 있습니다.
구조 및 분석:
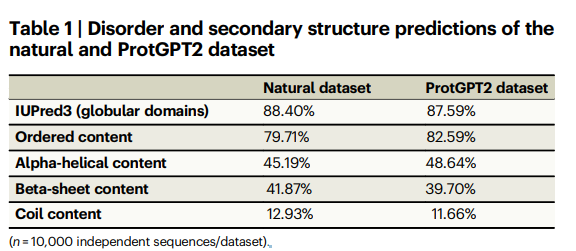
- ProtGPT2가 생성한 단백질 서열은 구형(globular) 구조를 형성할 확률이 높습니다. 이를 확인하기 위해 IUPred3라는 도구를 사용하여 무질서(disorder) 및 이차 구조(secondary structure)를 예측했습니다.
- 자연 단백질 서열의 약 88%가 글로불린 형태를 취하며, ProtGPT2가 생성한 서열 역시 약 87.59%가 글로불린 형태임을 확인했습니다. 이 결과는 ProtGPT2가 자연 단백질 서열과 매우 유사한 구조적 특징을 가진 단백질을 생성한다는 것을 의미합니다.
IUPred3 분석 결과:
- 자연 단백질과 ProtGPT2 생성 단백질 사이의 정렬된(ordered) 아미노산 분포도 유사합니다. 구체적으로, ProtGPT2가 생성한 서열 중 79.71%의 아미노산이 정렬된 상태였으며, 자연 단백질에서는 82.59%의 아미노산이 정렬된 상태였습니다.
- 또한, 알파 나선(alpha-helix), 베타 병풍(beta-sheet), 코일(coil)과 같은 이차 구조 요소의 비율도 유사한 결과를 보였습니다. 자연 단백질에서는 알파 나선이 45.19%, 베타 병풍이 41.87%, 코일이 12.93%였고, ProtGPT2의 경우 알파 나선이 48.64%, 베타 병풍이 39.70%, 코일이 11.66%로 나타났습니다.
4. ProtGPT2 sequences are similar yet distant to natural ones
이 부분에서는 ProtGPT2가 생성한 단백질 서열이 자연 단백질 서열과 유사하지만 동시에 진화적으로 먼 관계에 있다는 점을 설명합니다. 이는 ProtGPT2가 기존 단백질 서열을 학습하면서도, 새로운 영역의 단백질 서열을 생성할 수 있음을 의미합니다.
유사성 분석:
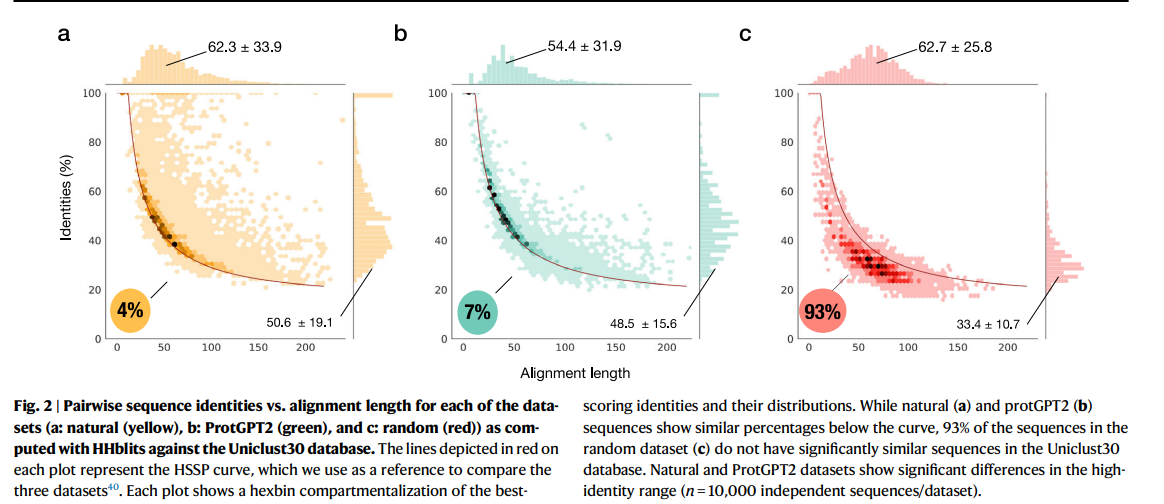
- ProtGPT2가 생성한 단백질 서열과 자연 단백질 서열 사이의 유사성을 확인하기 위해 HHblits 도구를 사용하여 원거리 상동성 탐지(remote homology detection)를 수행했습니다.
- 자연 단백질 데이터베이스(예: Uniclust30)와의 비교 결과, ProtGPT2가 생성한 10,000개의 서열 중 93%가 자연 단백질 서열과 어느 정도 유사성을 보였습니다. 이는 자연 단백질과 ProtGPT2 생성 서열이 어느 정도의 구조적 유사성을 유지하고 있음을 보여줍니다.
진화적 거리:
- 비록 많은 서열이 유사성을 보였지만, ProtGPT2가 생성한 서열은 자연 단백질 서열과 진화적으로 먼 관계에 있음을 확인할 수 있었습니다. HSSP 곡선(유사성 및 서열 길이의 상관관계를 나타내는 그래프) 상에서 ProtGPT2 서열의 다수는 자연 단백질과의 상동성(homology)을 보이지 않는 "황혼 영역(twilight zone)"에 속했습니다.
- ProtGPT2의 서열은 자연 단백질의 특정 영역에 속하지 않으며, 새로운 서열 공간을 탐색하고 있음을 시사합니다. 이는 ProtGPT2가 기존에 존재하지 않던 새로운 단백질 서열을 생성할 수 있는 가능성을 열어주며, 단백질 디자인에 있어 매우 중요한 발견입니다.
결론:
이 두 섹션에서의 결과는 ProtGPT2가 자연 단백질 서열과 매우 유사하면서도, 새로운 영역의 단백질 서열을 생성할 수 있음을 보여줍니다. ProtGPT2는 자연 단백질의 특징을 잘 모방하면서도 기존 데이터베이스에 없는 구조와 서열을 탐구할 수 있는 잠재력을 가지고 있습니다.
5. ProtGPT2 generates ordered structures
이 부분에서는 ProtGPT2가 생성한 단백질 서열이 안정적인 구조를 형성하며, 주문형(ordered) 구조를 가질 수 있음을 설명합니다. ProtGPT2는 기존의 자연 단백질과 비슷한 방식으로 접힘(folding) 구조를 만들어낼 수 있으며, 이는 de novo 단백질 디자인에 중요한 요소입니다.
AlphaFold를 통한 구조 예측:
- ProtGPT2가 생성한 단백질 서열이 실제로 안정적으로 접힐 수 있는지를 평가하기 위해 AlphaFold를 사용하여 각 서열에 대한 구조 예측을 수행했습니다. AlphaFold는 단백질의 각 잔기(residue)에 대해 pLDDT 점수(per-residue confidence score)를 부여하는데, 이 점수는 구조의 주문도(order)}를 나타냅니다.
- pLDDT 점수는 0에서 100까지의 범위를 가지며, 50 미만은 무질서(disordered) 영역을, 90 이상은 안정적인 주문형 구조(ordered structure)를 의미합니다.
- ProtGPT2가 생성한 단백질 서열의 평균 pLDDT는 63.2로, 상당수의 서열이 구조적으로 주문된 상태임을 나타냈습니다. 또한, ProtGPT2가 생성한 서열의 37%가 pLDDT 70 이상의 점수를 보여, 이 서열들이 자연 단백질과 유사하게 안정적인 구조를 형성할 수 있음을 시사합니다.
Rosetta를 통한 에너지 분석:
- Rosetta 도구를 사용하여 ProtGPT2가 생성한 단백질 서열의 열역학적 안정성을 추가로 평가했습니다. Rosetta는 총 에너지(Rosetta Energy Units, REU)를 계산하여 단백질의 구조가 얼마나 안정적인지를 나타냅니다. 자연 단백질과 ProtGPT2 서열 모두 평균적으로 1.9 REU/residue 수준의 안정성을 보였습니다. 이는 ProtGPT2가 생성한 단백질이 자연 단백질과 유사한 수준의 안정성을 유지하고 있음을 나타냅니다.
- 실험적으로 안정적인 단백질 구조는 -1 ~ -3 REU/residue 범위에 있어야 하는데, ProtGPT2 서열은 이 범위에 들어가는 값을 보였습니다.
분자 동역학(MD) 시뮬레이션:
- ProtGPT2가 생성한 서열의 구조적 유연성을 확인하기 위해 분자 동역학 시뮬레이션(Molecular Dynamics, MD)을 수행했습니다. 자연 단백질과 ProtGPT2가 생성한 단백질 모두 평균적으로 Root Mean Square Deviation (RMSD) 값이 약 3 Å로 나타났습니다. 이는 두 그룹 간의 유연성이 비슷하다는 것을 보여주며, ProtGPT2 서열이 자연 단백질과 유사한 방식으로 구조적 안정성과 유연성을 가질 수 있음을 시사합니다.
6. ProtGPT2 transcends the boundaries of the current protein space
이 부분에서는 ProtGPT2가 단백질 디자인에 있어 현재의 단백질 서열 공간(protein space)을 넘어서는 새로운 가능성을 제시하는 부분입니다. ProtGPT2는 기존의 자연 단백질 서열뿐만 아니라, 아직 탐구되지 않은 단백질 서열 공간을 탐색하고, 이를 통해 새로운 단백질 구조를 생성할 수 있는 잠재력을 보여줍니다.
서열 공간의 확장:
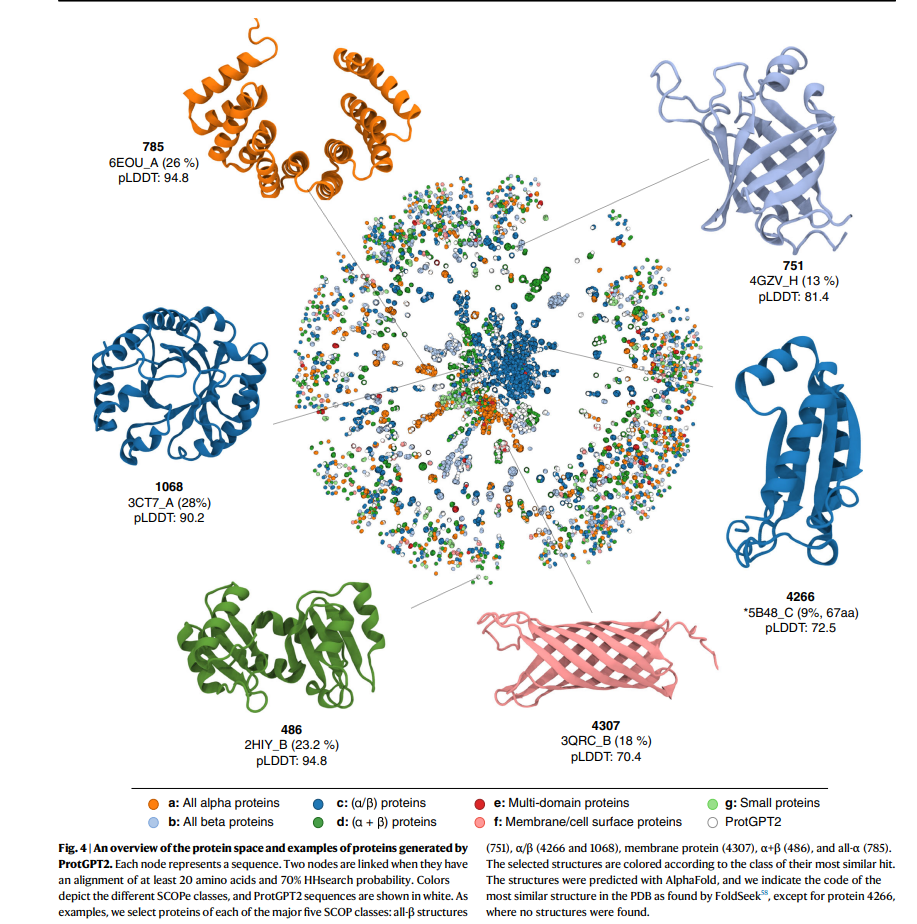
- ProtGPT2는 자연 단백질 서열뿐만 아니라, "어두운 프로테옴(dark proteome)"으로 알려진 실험적 방법이나 유사성 검색으로는 발견되지 않는 영역의 서열까지도 생성할 수 있습니다.
- ProtGPT2가 생성한 단백질 서열을 기존의 SCOP(SCOPe 2.07) 데이터베이스와 비교하여, 새로운 서열이 기존의 단백질 구조들과 어떻게 연관되어 있는지를 분석했습니다. 이를 위해 HHsearch를 사용하여 상동성(유사성)을 탐색하고, 네트워크 구조를 만들었습니다. 이 분석에서 ProtGPT2가 생성한 서열들은 기존 단백질 구조 공간에서 섬처럼 고립된 영역들(island-like clusters)을 연결하는 새로운 서열로 나타났습니다.
새로운 구조의 예:
- ProtGPT2는 새로운 단백질 토폴로지(예: β-시트, 막단백질, 알파-나선 구조 등)를 만들어낼 수 있으며, 일부는 기존의 단백질 구조 데이터베이스(PDB)에서 발견되지 않은 구조를 가지기도 했습니다.
- 예를 들어, ProtGPT2는 자연 단백질 서열에서는 보기 드문 비이상적인(“non-idealized”) 구조와 긴 루프(long loops)를 가진 구조도 생성할 수 있었습니다. 이러한 특징은 단백질이 특정 기능을 수행하는 데 중요한 표면 상호작용 영역을 형성할 수 있게 합니다.
진화적 새로운 영역 탐색:
- ProtGPT2는 기존의 단백질 설계에서 다루기 어려운 막단백질이나 복잡한 구조의 β-시트와 같은 새로운 구조를 생성할 수 있으며, 이는 단백질 디자인 분야에서 매우 중요한 진전입니다. 이처럼 ProtGPT2는 새로운 단백질 서열 공간을 탐구하며, 새로운 기능을 가진 단백질을 디자인하는 데 기여할 수 있습니다.
결론:
ProtGPT2는 안정적인 주문형 구조를 생성할 수 있으며, 기존 단백질 서열 공간을 넘어선 새로운 영역을 탐구하여 독창적이고 진화적으로 중요한 단백질 구조를 만들어낼 수 있습니다. 이는 단백질 디자인 분야에서 매우 유망한 진전을 의미하며, 환경 문제나 의료 문제 해결을 위한 새로운 단백질 기능을 디자인하는 데 큰 기여를 할 수 있습니다.
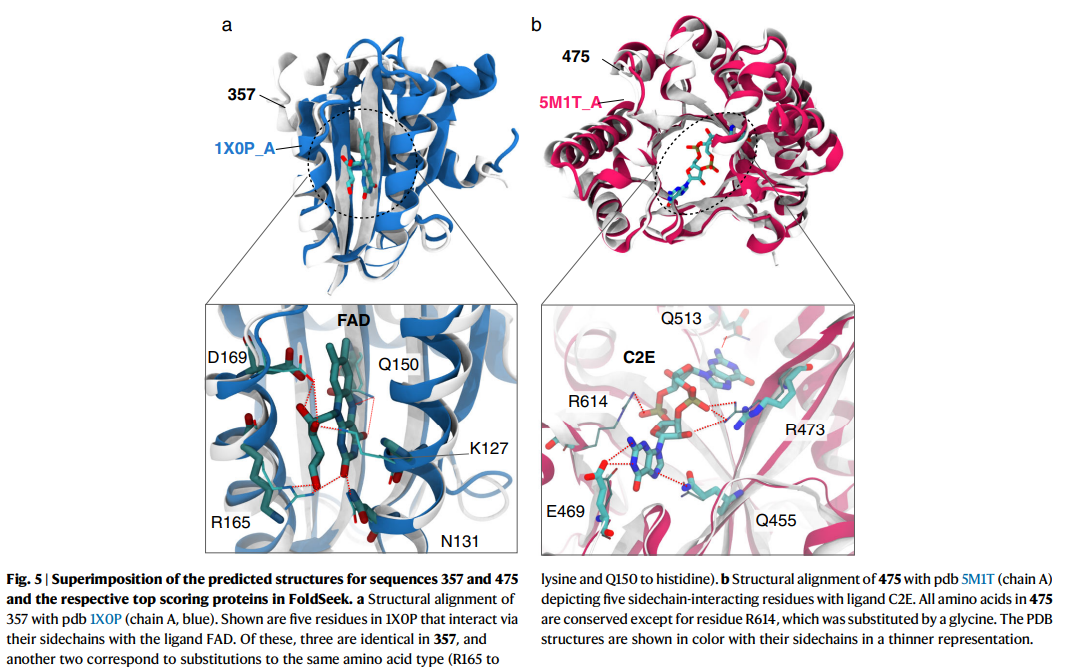
7. Preserved functional hotspots (보존된 기능적 핫스팟)
이 섹션에서는 ProtGPT2가 생성한 단백질 서열이 자연 단백질의 기능적 특징을 보존할 수 있다는 점을 설명합니다. ProtGPT2는 특정 리간드와 결합하는 기능적 부위(핫스팟)를 유지하면서 새로운 단백질 서열을 생성할 수 있습니다.
기능적 결합 부위 보존:
- ProtGPT2는 zero-shot 방식으로 훈련되었기 때문에, 특정 단백질 패밀리나 기능을 학습하지 않아도 리간드 결합 부위와 같은 핵심 기능적 요소를 보존하면서 서열을 생성할 수 있습니다.
- 연구진은 ProtGPT2가 생성한 단백질 서열과 자연 단백질 서열을 FoldSeek 도구를 사용해 비교했습니다. 이 비교를 통해, 결합 부위의 아미노산들이 유사하게 배열되어 있음을 확인했습니다.
예시:
- FAD 결합 단백질(PDB 코드 1X0P)의 경우, ProtGPT2가 생성한 서열 357은 자연 단백질과 결합하는 5개의 중요한 아미노산 중 3개를 동일하게 유지하고 있었습니다. 나머지 2개의 아미노산도 기능적으로 유사한 상호작용을 할 수 있는 다른 아미노산으로 대체되었습니다.
- C2E 결합 단백질(PDB 코드 5M1T)의 경우, ProtGPT2가 생성한 서열 475도 결합에 관여하는 5개 중 3개의 아미노산을 동일하게 유지했으며, 다른 2개는 유사한 기능을 가진 아미노산으로 대체되었습니다.
이 결과는 ProtGPT2가 진화적으로 멀리 떨어진 서열을 생성하면서도, 핵심적인 기능적 부위를 보존할 수 있음을 보여줍니다. 이는 단백질 엔지니어링에서 매우 중요한 발견으로, 새로운 기능을 가진 단백질을 설계할 때도 기존의 기능적 특징을 유지할 수 있는 가능성을 제시합니다.
8. Discussion (토론)
이 섹션에서는 ProtGPT2의 성과와 그 의미를 종합적으로 논의하고, 향후 연구 방향과 실제 응용 가능성에 대해 설명합니다.
ProtGPT2의 성과:
- 단백질 디자인에서 ProtGPT2는 기계 학습 기반의 단백질 생성에 있어서 중요한 진전입니다. 특히, ProtGPT2는 자연 단백질과 구조적 유사성을 가지면서도 진화적으로 새로운 단백질을 생성할 수 있는 능력을 보여주었습니다.
- ProtGPT2는 기존의 자연 단백질 서열 데이터만을 학습하여, 추가적인 훈련 없이도 고도로 기능적인 de novo 단백질을 생성할 수 있습니다. 이는 ProtGPT2가 생물학적 기능과 구조적 특징을 동시에 보존하는 단백질 엔지니어링에 매우 유용할 수 있음을 나타냅니다.
새로운 단백질 설계의 가능성:
-
ProtGPT2는 기존 단백질 설계에서 어려웠던 β-시트 구조나 막단백질과 같은 복잡한 구조를 생성할 수 있습니다. 특히 ProtGPT2는 이상적이지 않은(non-idealized) 긴 루프를 포함한 단백질을 만들어냄으로써, 기존 단백질 설계 방법론에서 해결하기 어려운 문제들을 극복할 수 있음을 보여주었습니다.
-
이 모델을 통해 새로운 기능을 가진 단백질을 설계할 수 있으며, 의료나 환경 문제와 같은 분야에서 고속 단백질 엔지니어링이 가능해집니다. 특히, ProtGPT2는 단백질 디자인의 고성능 스크리닝을 통해 자연 단백질 데이터베이스에 없는 새로운 서열을 탐색할 수 있습니다.
향후 연구 방향:
-
앞으로의 연구에서는 ProtGPT2의 세밀한 조정(fine-tuning)을 통해 특정 기능적 태그나 패밀리에 맞는 단백질을 생성하는 능력을 강화할 수 있습니다. 이러한 조정을 통해 특정 단백질 패밀리나 기능에 맞춘 목적형 단백질 설계가 가능해질 것입니다.
-
또한, ProtGPT2가 생성한 단백질의 실험적 검증이 필요합니다. 실제 생물학적 실험을 통해 ProtGPT2가 생성한 단백질의 구조적 및 기능적 특징을 평가하고, 이를 통해 실제 응용에서의 가능성을 탐색할 수 있습니다.
결론:
ProtGPT2는 단백질 디자인에 있어 혁신적인 접근법을 제시하며, 고속 및 효율적인 단백질 설계를 가능하게 합니다. ProtGPT2는 기존 단백질 구조의 경계를 넘어 새로운 서열을 탐색하며, 단백질 엔지니어링의 새로운 장을 열어줄 수 있을 것입니다. 앞으로의 연구와 실험을 통해 이 모델이 다양한 실제 응용에 사용될 가능성이 높습니다.
Methods (방법론)
1. Vocabulary encoding (어휘 인코딩)
ProtGPT2는 단백질 서열을 처리하기 위해 특정 어휘(vocabulary)를 필요로 합니다. 단백질 서열에서 각각의 아미노산은 문자로 표현될 수 있으며, 이를 효율적으로 처리하기 위해 BPE(Byte Pair Encoding) 알고리즘을 사용하여 단백질 서열을 서브워드(sub-word) 단위로 토크나이징(tokenization)합니다. 이 방법을 통해 각 서열을 고유한 단위로 나누고, 모델이 학습할 수 있는 형태로 변환합니다.
주요 사항:
- ProtGPT2는 UniRef50 데이터셋을 사용하여 BPE 알고리즘을 훈련했고, 최종적으로 50,256개의 토큰을 생성했습니다. 이 토큰들은 평균 4개의 아미노산으로 이루어져 있습니다.
- 이 어휘는 자연어 처리(NLP)에서 사용되는 것과 유사한 방식으로 단백질 서열을 효과적으로 표현합니다.
2. Dataset preparation (데이터셋 준비)
ProtGPT2는 단백질 서열 데이터로 학습되었습니다. 이 데이터는 UniRef50에서 추출된 서열들로 구성되었으며, 이를 학습과 검증을 위해 적절히 나누어 사용했습니다.
주요 사항:
- UniRef50 (2021_04 버전)에서 총 49,874,565개의 단백질 서열을 가져와 사용했습니다.
- 데이터셋은 90%는 학습용, 10%는 검증용으로 나누어졌습니다. 학습 데이터에는 44.88백만 개의 서열이, 검증 데이터에는 4.99백만 개의 서열이 포함되었습니다.
- 서열의 길이를 512 토큰으로 설정하여 모델 학습에 사용했습니다.
3. Model pre-training (모델 사전 학습)
ProtGPT2는 Transformer 기반의 언어 모델로, 자율회귀(autoregressive) 모델로 작동합니다. 이 모델은 자연 단백질 서열을 학습하여 다음 아미노산을 예측하는 방식으로 훈련되었습니다.
주요 사항:
- 모델은 36 레이어와 738백만 개의 파라미터를 가진 GPT2-large 아키텍처와 유사한 구조를 가지고 있습니다.
- Adam 옵티마이저를 사용하여 학습하였으며, 학습률은 1e-03으로 설정되었습니다.
- 학습은 128개의 NVIDIA A100 GPU에서 진행되었으며, 4일 동안 병렬 처리로 진행되었습니다.
4. Model inference (모델 추론)
모델이 학습된 후, 서열 생성에 필요한 다양한 추론(inference) 설정을 통해 새로운 단백질 서열을 생성했습니다.
주요 사항:
- Top-k 샘플링: k 값은 250에서 1000 사이의 값을 사용하여 샘플링을 수행했습니다. 가장 좋은 결과를 보인 k 값은 950이었으며, 반복 페널티(repetition penalty)는 1.2로 설정되었습니다. 이 설정은 모델이 자연 단백질과 유사한 아미노산 분포를 가지도록 하는 데 도움이 됩니다.
- Greedy Search와 Beam Search도 실험했지만, 자연 단백질과 유사한 서열을 생성하는 데 있어서는 Top-k 샘플링이 가장 효과적이었습니다.
5. Sequence dataset generation (서열 데이터셋 생성)
ProtGPT2의 성능을 평가하기 위해, 모델이 생성한 서열과 자연 단백질 서열을 비교할 데이터셋을 생성했습니다.
주요 사항:
- ProtGPT2는 총 10,000개의 단백질 서열을 생성했으며, 각 서열의 평균 길이는 149.2 아미노산이었습니다.
- 자연 단백질 서열 데이터는 UniRef50에서 랜덤으로 선택한 10,000개의 서열을 사용했으며, 서열 길이가 ProtGPT2에서 생성한 서열과 동일하도록 맞추었습니다.
- 랜덤 서열 데이터셋도 생성하여 ProtGPT2와 자연 단백질 서열 간의 비교군으로 사용했습니다.
6. Homology detection (상동성 탐지)
ProtGPT2가 생성한 서열이 자연 단백질과 얼마나 유사한지를 평가하기 위해, HHblits 도구를 사용하여 상동성(homology)을 탐지했습니다. 이를 통해 ProtGPT2가 생성한 서열이 기존 단백질과 얼마나 유사하거나 다른지를 확인했습니다.
주요 사항:
- 각 서열은 Uniclust30 데이터베이스와 비교되었으며, 상동성이 있는지 여부를 확인했습니다. ProtGPT2가 생성한 서열 중 93%가 자연 단백질 서열과 상동성을 가진 것으로 나타났습니다.
7. Disorder prediction (무질서 예측)
단백질 서열에서 무질서(disorder) 및 이차 구조(secondary structure) 요소를 예측하기 위해 IUPred3 및 PSIPRED 도구를 사용했습니다. 이를 통해 ProtGPT2가 생성한 단백질 서열이 자연 단백질 서열과 얼마나 유사한지를 평가했습니다.
주요 사항:
- ProtGPT2 서열의 약 87.59%가 글로불린(globular) 구조로 나타났으며, 자연 단백질 서열과 유사한 결과를 보였습니다.
8. AlphaFold2 structure prediction (AlphaFold2 구조 예측)
ProtGPT2가 생성한 서열의 3차원 구조를 평가하기 위해 AlphaFold2를 사용했습니다. 이를 통해 ProtGPT2 서열이 실제로 어떻게 접히고 구조를 형성하는지 확인할 수 있었습니다.
주요 사항:
- 각 서열에 대해 5개의 구조 예측을 수행했으며, pLDDT 점수를 통해 구조적 신뢰도를 평가했습니다.
9. Network construction (네트워크 구축)
ProtGPT2가 생성한 단백질 서열과 기존의 자연 단백질 서열 간의 유사성 네트워크를 구축하여, ProtGPT2가 얼마나 새로운 서열 공간을 탐구하는지를 평가했습니다.
주요 사항:
- HHsearch 도구를 사용하여 서열 간의 유사성을 확인하고, 이를 기반으로 네트워크를 생성했습니다.
- 네트워크는 ProtGPT2가 기존 서열의 고립된 영역을 연결하는 새로운 서열을 생성할 수 있음을 보여주었습니다.
10. Molecular dynamics simulations (분자 동역학 시뮬레이션)
ProtGPT2가 생성한 단백질 서열의 유연성과 구조적 안정성을 평가하기 위해 분자 동역학 시뮬레이션(Molecular Dynamics, MD)을 수행했습니다.
주요 사항:
- 각 서열에 대해 100ns의 시뮬레이션을 세 번씩 반복하였으며, 이 시뮬레이션을 통해 ProtGPT2 서열이 자연 단백질과 비슷한 구조적 유연성을 가지고 있음을 확인했습니다.
11. Rosetta calculations (Rosetta 계산)
Rosetta 도구를 사용하여 ProtGPT2가 생성한 서열의 열역학적 안정성을 추가로 평가했습니다. 이를 통해 ProtGPT2 서열이 자연 단백질 서열과 유사한 안정성을 가질 수 있음을 확인했습니다.
주요 사항:
- 각 서열에 대해 Rosetta RelaxBB 알고리즘을 사용하여 에너지 계산을 수행했습니다.
사용법
모델 가중치는 허깅페이스에서 공개적으로 사용할 수 있습니다.
저장소: https://huggingface.co/nferruz/ProtGPT2 및 Zenodo:
https://doi.org/10.5281/zenodo.6796843 [https://zenodo.org/record/
6796843#.YswB9XbMIVA]. 훈련용 데이터 세트는 다음에서 사용할 수 있습니다:
https://huggingface.co/datasets/nferruz/UR50_2021_04. 이 작업의 세 가지
시퀀스 데이터 세트는 다음 링크에서 확인할 수 있습니다: https://huggingface.co/.
데이터셋/엔페루즈/데이터셋_파스타스. 알파폴드 예측은
세 데이터 세트에 대한 알파폴드 예측은 https://huggingface.co/datasets/
nferruz/dataset_alphafold. Uniref50 원본 데이터베이스 버전
21_04는 https://ftp.uniprot.org/pub/databases/uniprot/
previous_releases/release-2021_04/. Uniclust30 데이터베이스 버전
2018_08은 http://gwdu111.gwdg.de/~compbiol/uniclust/
2018_08/uniclust30_2018_08_hhsuite.tar.gz.
코드 주소
모델은 허깅페이스 트랜스포머 트레이너로 훈련되었습니다.
버전 4.14.1로 훈련되었습니다. 코드와 설명서는 여기에서 확인할 수 있습니다: https://
huggingface.co/docs/transformers/main_classes/trainer.
핵심내용 정리
Q.이게 gpt2 모델을 기반으로 설계 된 프로틴 생성 모델인거야? 단백질에 특화된 모델 설계를 위해 무엇을 한거고
A.
네, ProtGPT2는 GPT-2 모델을 기반으로 설계된 단백질 생성을 위한 특화된 모델입니다. GPT-2는 원래 자연어 처리(NLP)에서 텍스트 생성을 위해 개발된 모델이지만, ProtGPT2는 단백질 서열을 생성하는 데 사용됩니다. 이를 위해 단백질의 특성에 맞춰 몇 가지 중요한 변경 사항과 조정이 이루어졌습니다. 이제 ProtGPT2가 GPT-2와 어떤 차이점이 있는지, 그리고 단백질 생성에 특화된 설계를 위해 무엇을 했는지 설명드리겠습니다.
1. 데이터셋 변경
GPT-2는 자연어 데이터를 학습하지만, ProtGPT2는 단백질 서열 데이터로 학습됩니다. 이를 위해 다음과 같은 조치가 취해졌습니다:
- ProtGPT2는 UniRef50이라는 단백질 데이터베이스를 사용하여 훈련되었습니다. 이 데이터베이스에는 약 5천만 개의 단백질 서열이 포함되어 있으며, 이는 단백질 디자인에서 중요한 역할을 합니다.
- 자연어에서의 단어와는 달리, 단백질 서열은 아미노산의 배열로 이루어져 있습니다. 각 아미노산은 화학적으로 정의된 20개의 기본 아미노산으로 구성된 화학적 알파벳을 사용합니다.
이를 통해 ProtGPT2는 자연어 텍스트 대신 단백질 서열의 패턴을 학습할 수 있도록 데이터셋이 준비되었습니다.
2. 토크나이징(Tokenization) 방법 조정
GPT-2는 자연어에서 단어 또는 문장을 기반으로 토큰화하는 반면, ProtGPT2는 단백질 서열을 처리하기 위해 특수한 토큰화 방식이 사용됩니다:
- ProtGPT2는 BPE(Byte Pair Encoding) 알고리즘을 사용하여 단백질 서열을 서브워드(sub-word) 단위로 나누어 토크나이징합니다. 이 방식은 자연어 처리에서 사용되는 방식과 비슷하지만, 단백질 서열에 맞춰 수정되었습니다.
- 최종적으로, ProtGPT2는 50,256개의 토큰으로 구성된 어휘를 사용하여 단백질 서열을 처리합니다. 여기서 각 토큰은 평균 4개의 아미노산으로 이루어져 있습니다.
3. 자율회귀(Autoregressive) 모델링
ProtGPT2는 자율회귀(autoregressive) 방식으로 다음 아미노산을 예측합니다. 이는 GPT-2가 다음 단어를 예측하는 방식과 유사합니다. 하지만 단백질 디자인에서는 다음과 같은 특수 사항이 고려됩니다:
- ProtGPT2는 각 아미노산의 이전 서열 정보에 기반하여 다음 아미노산을 예측합니다. 이를 통해 자연적으로 발생하는 단백질 서열의 패턴을 모방할 수 있습니다.
- 모델은 음의 로그 우도(Negative Log Likelihood, NLL)를 최소화하는 방식으로 학습됩니다. 이를 통해 단백질 서열에서 각 아미노산이 나타날 확률을 효과적으로 학습할 수 있습니다.
4. 구조적 평가 및 안정성 분석
단백질은 3차원 구조를 가지며, 이 구조가 단백질의 기능에 매우 중요합니다. ProtGPT2는 자연어 생성과는 달리, 생성된 단백질 서열이 안정적인 3차원 구조를 형성하는지를 확인하는 추가적인 평가 단계가 필요합니다:
- AlphaFold2: ProtGPT2가 생성한 단백질 서열의 3차원 구조를 예측하기 위해 AlphaFold2가 사용되었습니다. 이를 통해 생성된 단백질 서열이 자연 단백질처럼 안정적으로 접히는지 평가할 수 있습니다.
- Rosetta Relax: ProtGPT2가 생성한 단백질 서열의 열역학적 안정성을 평가하기 위해 Rosetta 도구가 사용되었습니다. 이는 모델이 생성한 단백질이 실제로 안정적인 구조를 가질 수 있는지를 확인하는 중요한 단계입니다.
5. 단백질 서열 공간의 탐색
단백질 디자인에서 중요한 목표는 새로운 서열 공간을 탐색하는 것입니다. ProtGPT2는 기존 단백질 서열 데이터에만 국한되지 않고, 기존에 존재하지 않는 새로운 단백질 서열을 생성할 수 있습니다. 이를 위해:
- ProtGPT2는 무라벨 데이터(unsupervised data)에서 학습하므로, 기존에 주어진 단백질 서열에 국한되지 않고 새로운 단백질 서열을 탐색할 수 있는 능력을 가지게 됩니다.
- 상동성 탐지(Homology Detection) 및 네트워크 분석을 통해 ProtGPT2가 새로운 서열 공간을 탐색할 수 있음을 확인했습니다. ProtGPT2는 기존에 알려지지 않은 단백질 서열을 생성할 수 있으며, 이는 단백질 엔지니어링에서 매우 유용합니다.
ProtGPT2의 단백질 특화 모델 설계 요약:
- 단백질 서열 데이터(UniRef50)로 학습.
- BPE 토크나이징을 통해 단백질 서열을 처리.
- 자율회귀 모델로 다음 아미노산을 예측.
- AlphaFold2와 Rosetta를 통해 3차원 구조와 안정성을 평가.
- 새로운 단백질 서열 공간을 탐색할 수 있는 무라벨 학습 방식.
ProtGPT2는 이러한 특화된 설계를 통해 단백질 디자인에 최적화된 모델로, 자연 단백질과 유사한 구조와 기능을 가진 de novo 단백질을 생성할 수 있습니다.
