기계 학습 프로젝트의 활동을 구성하는 요소를 이해하는 것은 매우 중요하다. 일반적으로 머신러닝 프로젝트에는 다음과 같은 4가지 주요 단계가 있다.
1. 계획 및 프로젝트 설정(set up project)
- 이 단계에서는 작업할 머신러닝 문제를 결정하고, 해당 프로젝트의 요구 사항(requirements)과 목표를 결정하고(어느 정도 성능이 나와야하는지, 정확도와 성능의 trades-off를 계산), 리소스를 적절하게 할당하는 방법을 파악하고, 윤리적 의미 또한 고려한다.
2. 데이터 수집 및 레이블 지정(data labeling & manipulating)
- 이 단계에서는 training data를 수집하고 data에 labeling을 한다.
- data를 가져오기가 어려우면 1단계로 돌아간다.
3. 모델 교육 및 모델 디버깅(modeling & training model & evaluating)
- 이 단계에서는 기준 model을 빠르게 구현하고, 문제 영역에 대한 최신 방법을 찾아 재현하고, 구현한 코드를 디버그하고, 특정 작업에 대한 model 성능을 개선하는 작업을 한다.
- 더 많은 data를 수집해야 하거나 data labeling의 신뢰도가 떨어지는 것을 알게 되면 2단계로 돌아간다.
- 또는 작업이 너무 어렵고 프로젝트 요구 사항 사이에 tradeoff가 있음을 인식하게 되면 1단계로 돌아간다.
4. 모델 배포 및 모델 테스트(deploy & roll up production )
- 이 단계에서는 제한된 환경에서 개발된 model을 개발하고 회귀를 방지하기 위한 테스트를 작성하고, model을 production level로 보내려고 한다.
- model의 정확도가 떨어지면 3단계로 돌아간다.
- 또는 더 많은 data를 수집하고 하드 케이스를 마이닝하여(?) training data와 production data 간의 불일치를 수정할 수 있다(현실 데이터와 학습 데이터간의 불일치, 2단계로 돌아가기).
- 또는 선택한 metric이 실제로 downstream user behavior을 유도하지 않거나 실제 성능이 좋지 않다는 것을 알 수 있다.
- 이러한 상황에서는 프로젝트의 메트릭과 요구 사항을 다시 살펴봐야 하기에 1단계로 돌아간다.
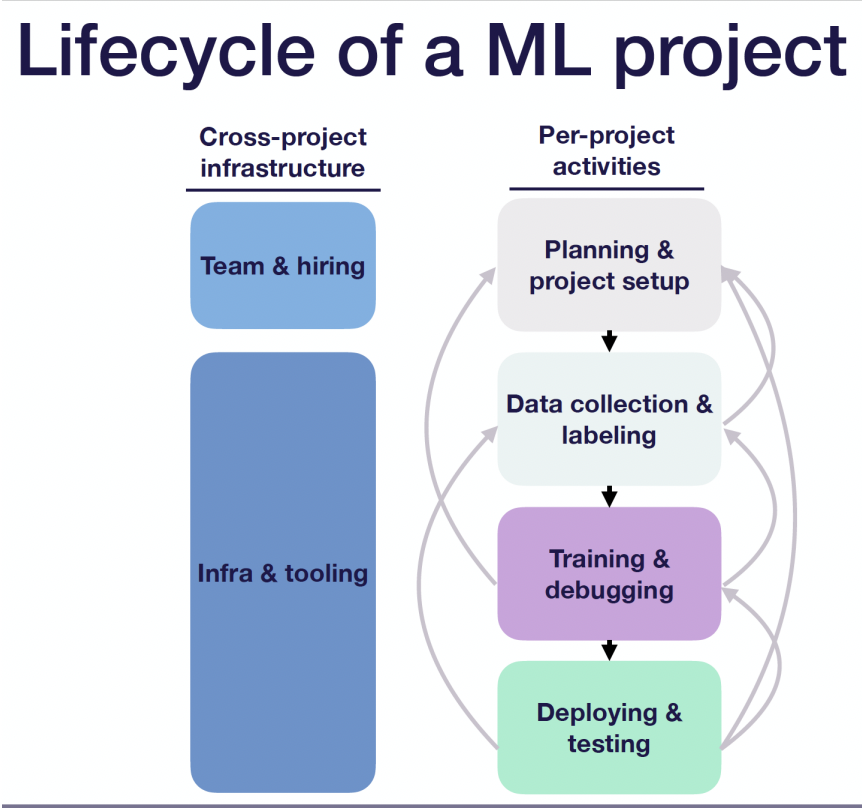
위에서 언급한 프로젝트별 활동 외에도 ML 팀이 관련된 모든 프로젝트에서 해결해야 하는 다른 두 가지 사항이 있다.
(1) 팀 구성 및 인력 고용 (2) ML 시스템을 반복적이고, 대규모로 구축하기 위한 인프라 및 도구 설정
또한 해당 응용 프로그램 도메인의 최신 결과를 이해하여 가능한 것과 다음으로 시도할 사항을 파악하는 것이 유용할 수 있다.

one and only