
INTRO
논문 제목이 살벌하다. Don't Do RAG ,,,
열심히 배웠는데 어째서요 ㅠㅠ
그럼에도... 새로운건 늘 짜릿하니까 🥺
(한동안 LLM 관련 안한다고 했는데 블로그는 내 취미생활이니까 에라 모르겠다)
RAG 방식의 한계점을 극복하기 위해 나온 CAG에 대해 알아보자!
기술 소개: CAG와 RAG
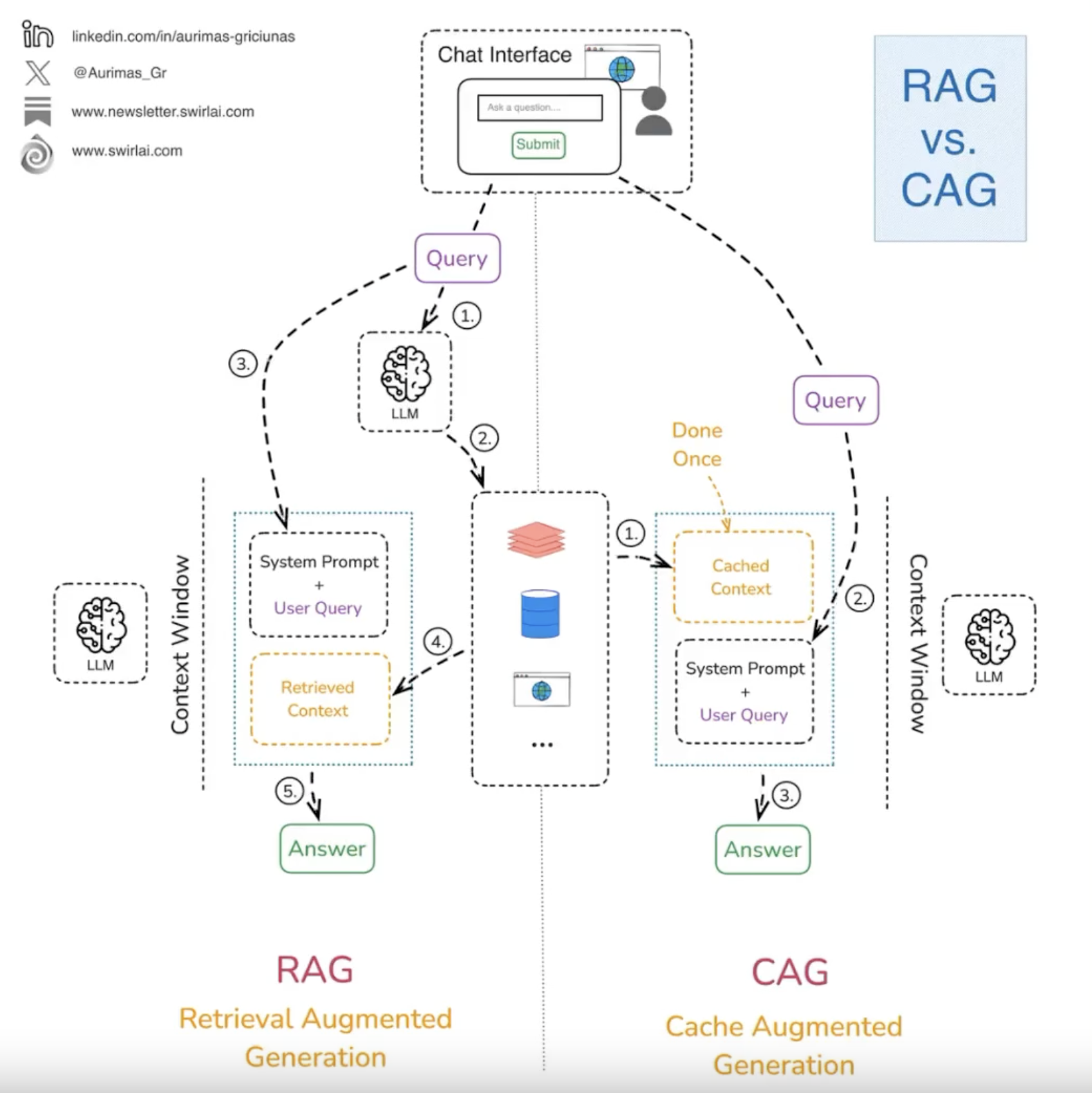 출처 : https://www.threads.net/@choi.openai/post/DEgGNUAh6M-
출처 : https://www.threads.net/@choi.openai/post/DEgGNUAh6M-
CAG(Cache-Augmented Generation)는 대규모 언어 모델의 성능을 극대화하기 위해 개발된 기술로, 미리 준비된 정보를 캐시에 저장하여 빠른 응답을 제공한다. 이 기술은 실시간 검색의 필요성을 제거하고, 사전에 로드된 정보를 활용하여 높은 정확성과 효율성을 보장한다. CAG는 복잡한 검색 모듈을 사용하지 않기 때문에 구조가 단순하며, 이는 시스템의 유지보수와 확장성이 용이하다.
RAG(Retrieval-Augmented Generation)는 대규모 언어 모델의 한계를 극복하기 위해 개발된 기술로, 외부 데이터베이스에서 실시간으로 정보를 검색하여 제공한다. 이 기술은 최신 정보를 활용할 수 있어 다양한 질문에 대한 대응력을 높일 수 있지만, 검색 시간과 시스템 복잡성이 증가할 수 있는 단점이 있다. RAG는 신뢰할 수 있는 외부 지식 베이스를 참조하여 모델의 출력을 최적화한다.
CAG와 RAG는 모두 대규모 언어 모델의 성능을 향상시키기 위해 개발된 기술이다. CAG는 미리 준비된 정보를 활용하여 빠르고 정확한 응답을 제공하는 반면, RAG는 실시간 검색을 통해 최신 정보를 반영하여 다양한 질문에 대응할 수 있다. 이러한 기술들은 대규모 언어 모델의 한계를 극복하고, 보다 효율적이고 정확한 정보 제공을 목표로 한다.
출시 시기 및 배경
CAG는 2024년에 소개된 기술로, RAG의 한계를 보완하기 위해 개발되었고 RAG는 2023년 3월 NVIDIA GTC 컨퍼런스에서 처음 발표된 기술로, 대규모 언어 모델의 한계를 극복하기 위해 개발되었다.
RAG는 기존 대규모 언어 모델의 한계점인 비실시간성을 보완하기 위해 외부 데이터베이스에서 실시간으로 정보를 검색하여 최신 정보를 반영할 수 있는 능력을 갖추고 있다. RAG는 다양한 질문에 대한 대응력을 높이고, 보다 정확한 정보를 제공하기 위해 설계되었다.
그럼에도 RAG는 한계점이 있었기 때문에 CAG는 이런 부분을 보완하고자 실시간 검색의 필요성을 제거하고 사전에 로드된 정보를 활용하여 응답을 생성한다. 이는 시스템의 복잡성을 줄이고, 유지보수와 확장성을 용이하게 하며, 빠르고 정확한 응답을 제공할 수 있도록 한다.
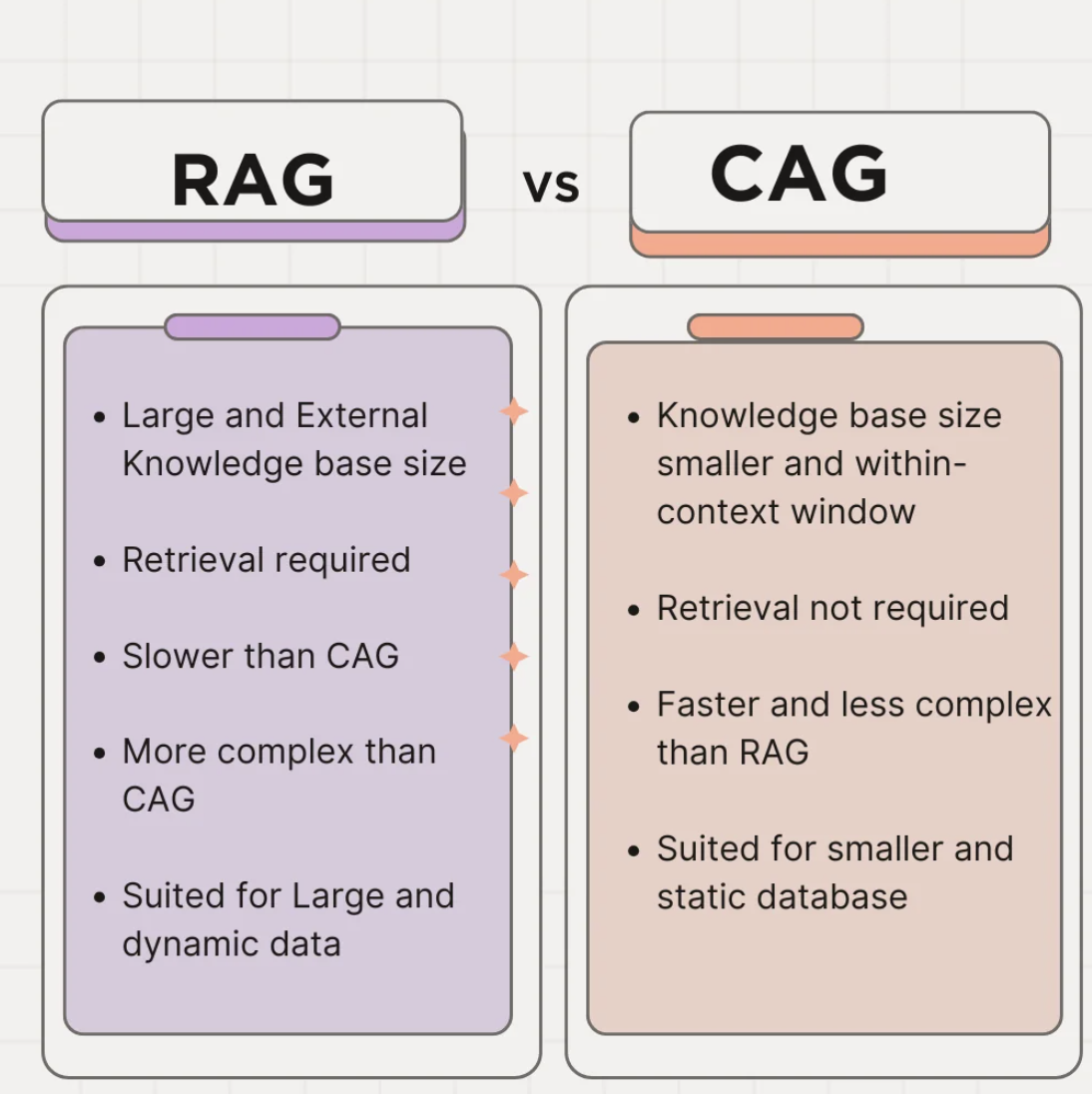
퍼플렉시티에게 만들어달라고 하니까 줄 다 엉망. 이럴거야 !?
코드로 살펴보기
CAG와 RAG는 각각의 장점을 가지고 있다. CAG는 미리 준비된 정보를 활용하여 빠른 응답과 간단한 구조를 제공함으로써 시스템의 복잡성을 줄이고, 유지보수와 확장성을 용이하게 한다. 반면 RAG는 외부 데이터베이스에서 실시간으로 정보를 검색하여 최신 정보를 활용할 수 있어 다양한 질문에 대한 대응력을 높일 수 있다. 이러한 차이점은 각 기술이 특정 상황에서 더 적합하게 사용될 수 있도록 한다.
RAG
import openai from some_retrieval_module import retrieve_documents # 가상의 검색 모듈 # 사용자 질의 user_query = "파리의 에펠탑에 대해 알려줘." # 외부 데이터베이스에서 관련 문서 검색 retrieved_docs = retrieve_documents(user_query) # 검색된 문서를 컨텍스트로 설정 context = "\n\n".join(retrieved_docs) # 모델 프롬프트 구성 prompt = f"Context:\n{context}\n\nQuery: {user_query}\nAnswer:" # LLM에 프롬프트 전달하여 응답 생성 response = openai.ChatCompletion.create( model="gpt-4", messages=[ {"role": "system", "content": "당신은 역사적인 랜드마크에 대해 잘 알고 있는 어시스턴트입니다."}, {"role": "user", "content": prompt} ], max_tokens=100, temperature=0.5 ) print(response['choices'][0]['message']['content'].strip())
이 코드의 가장 핵심은 외부 검색 파이프라인이다.
지금은 간단한 코드여서 가상의 retrieve_documents를 사용했지만
보통은 FAISS나 다른 벡터DB를 사용하여 검색한 정보를 LLM에게 전달한다.
CAG
import torch from transformers import AutoTokenizer, AutoModelForCausalLM # 모델과 토크나이저 로드 model_name = 'gpt-3.5-turbo' # 예시 모델 이름 tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # 사전 로딩된 데이터 preloaded_data = """ 에펠탑은 프랑스 파리에 위치한 랜드마크로, 1889년에 완공되었습니다. 세계에서 가장 유명한 건축물 중 하나입니다. 실제로는 훨씬 길고 많겠죠. 파일이나 DB자체를 불러와야 할거에요. """ # 사용자 질의 user_query = "파리의 에펠탑에 대해 알려줘." # 입력 구성: 사전 로딩된 데이터 + 사용자 질의 input_text = preloaded_data + "\n\n" + user_query input_ids = tokenizer.encode(input_text, return_tensors='pt') # 키-값 캐시 생성 with torch.no_grad(): outputs = model(input_ids, use_cache=True) past_key_values = outputs.past_key_values # 응답 생성 generated_ids = model.generate(input_ids, max_length=512, past_key_values=past_key_values) response = tokenizer.decode(generated_ids[0], skip_special_tokens=True) print(response)
CAG의 가장 핵심은 키-값 캐시 생성 부분이다
많은 메모리를 차지하지 않게 문서를 캐시화 해두고 모델은 검색 과정을 건너뛰고 저장된 캐시를 참고하여 답변을 생성하게 된다.
관련 연구 논문
CAG와 관련된 주요 논문으로는 'Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks'가 있다. 이 논문은 CAG가 RAG의 한계를 보완하기 위해 개발되었으며, 미리 준비된 정보를 활용하여 빠르고 정확한 응답을 제공하는 방법을 제시한다.
RAG와 관련된 주요 논문으로는 'Retrieval-Augmented Generation for Large Language Models: A Survey'가 있다. 이 논문은 RAG가 대규모 언어 모델의 한계를 극복하기 위해 제안된 기술로, 외부 데이터베이스에서 실시간으로 정보를 검색하여 최신 정보를 반영할 수 있는 능력을 갖추고 있음을 설명한다.
CAG와 RAG는 모두 대규모 언어 모델의 성능을 향상시키기 위한 기술로, 다양한 연구가 진행되고 있다. CAG는 미리 준비된 정보를 활용하여 빠르고 정확한 응답을 제공하는 반면, RAG는 실시간 검색을 통해 최신 정보를 반영하여 다양한 질문에 대응할 수 있다. 이러한 연구들은 대규모 언어 모델의 한계를 극복하고, 보다 효율적이고 정확한 정보 제공을 목표로 한다.

향후 발전 방향
CAG는 다양한 분야에서의 활용 가능성이 크며, 특히 실시간 답변 서비스와 특정 분야 정보 활용에 유용할 것으로 예상된다. 나온지 얼마 되지 않은 기술이지만, 현재 많은 기술 중 굉장한 관심과 기대를 가지고 있다. 실제 많은 대형 언어 모델이 컨텍스트 윈도우를 활용해 빠른 응답과 불필요한 반복적인 검색을 피하고 있다고 한다.
RAG는 하이브리드 시스템 개발을 통해 개인화, 확장성, 정확성 중심으로 발전할 것으로 보인다. 외부 데이터베이스에서 실시간으로 정보를 검색하여 최신 정보를 반영할 수 있는 RAG는 다양한 질문에 대한 대응력을 높이고, 보다 정확한 정보를 제공하기 위해 설계되었다. 이러한 발전 방향은 RAG가 개인화된 정보 제공과 확장성 있는 시스템 구축에 기여할 수 있을 것으로 보인다.
CAG와 RAG의 미래 전망은 두 기술의 장점을 결합한 하이브리드 시스템 개발이 활발히 진행될 수도 있다. CAG의 빠른 응답과 간단한 구조, RAG의 최신 정보 활용과 다양한 질문에 대한 대응력을 결합한 하이브리드 시스템은 대규모 언어 모델의 성능을 극대화할 수 있는 가능성을 제시한다. 이러한 시스템은 보다 효율적이고 정확한 답변을 내기 위해 가파른 성장을 할 것이다.
OUTRO
처음에는 CAG가 잘 이해가지 않았는데 관련 논문을 찾고 또 읽어보니 정말 재미있다는 생각이 들었다.
원래 전부 모델에 던짐 -> 느려짐 -> 검색해서 모델에 던짐 -> 이것도 느림 -> 미리 사전에 캐시로 저장해서 메모리 덜 쓰게 하기(검색X) -> ?
한편으로는 연구분야 사람들도 이어지지 않은 지식 그래프를 잇는 사람들이 아닐까 생각했다. 모델, 프롬프트, 지식 베이스, 캐스 등등 모두 다른 각각의 개념인데, 이걸 어떻게 조합해서 더 좋은 성능을 이끌어 낼것인가 하지 않을까. 조심스레 생각해본다 😊
출처:
글
https://discuss.pytorch.kr/t/cag-cache-augmented-generation-llm-long-context-rag/5792
https://www.aitimes.com/news/articleView.html?idxno=167272
https://modulabs.co.kr/blog/retrieval-augmented-generation
