
인턴 생활 하면서 정말정말 정신 없는 삶을 살고 있다😋
1일 1 포스팅이 목표였는데 개뿔 현생에 치여 매우 바쁘다
그래도 오랜만에 일하면서하면서 알게 된 분석기법을 소개하고자 한다
원래 한 포스팅에 내용을 많이 쓰는 편인데 한동안은 어렵지 싶음😢
주저리 주저리 그만하고, 얼른 내가 배운 지식을 남기자 !!

1. 주제 분석 ?
주제 분석(Topic Modeling) 은 대량의 텍스트 데이터에서 숨겨진 주제를 자동으로 찾아내기 위해 사용되는 기법으로, 주제들이 텍스트에서 자주 등장하는 단어 패턴을 기반으로 추론된다.
주로 비지도 학습 기법에 속하며, 인간의 개입 없이 데이터의 패턴을 발견한다.
주제 분석의 목적은 문서에서 자주 등장하는 단어들의 패턴을 기반으로 그 문서가 어떤 주제를 다루고 있는지 파악하는 것 !
주제 분석은 비정형 텍스트 데이터를 분석하는 데 효과적인 도구로, 뉴스 기사, 블로그, 학술 논문, 사용자 리뷰 등에서 사용된다. 이러한 텍스트 데이터가 대규모일 경우, 인간이 일일이 읽고 분석하는 것이 불가능하거나 비효율적일 수 있기 때문에 주제 분석 기법은 다음과 같은 질문을 자동으로 해결한다
텍스트 데이터에서 주된 주제는 무엇인가?
각 문서는 어떤 주제를 얼마나 다루고 있는가?
주제와 관련된 핵심 단어들은 무엇인가?
주제 분석의 중요한 가정은 문서가 주제들의 혼합으로, 주제가 단어들의 혼합으로 구성된다는 것 !
즉, 문서(document) 는 여러 주제(topic) 의 혼합으로 이루어져 있으며, 각 주제는 문서 내에 확률적으로 분포되어 있다.
각 주제(topic) 는 특정 단어들의 분포로 정의되며, 주제는 여러 문서에서 단어의 출현 빈도에 따라 확률적으로 구성된다.
2. LDA ?
LDA(Latent Dirichlet Allocation)는 주제 분석의 대표적인 알고리즘이자 확률적 주제 모델링 기법
📚 LDA의 확률적 분포
- 문서-주제 분포: 문서가 여러 주제로 이루어져 있으며, 각 주제는 문서 내에서 특정 확률로 등장
- 주제-단어 분포: 각 주제는 여러 단어로 이루어져 있으며, 주제 내에서 특정 단어들이 특정 확률로 등장
-> LDA는 이러한 분포를 토대로 각 문서가 어떤 주제들로 이루어져 있는지를 추정하고, 각 주제가 어떤 단어들로 이루어져 있는지를 계산함
- 단어(w): 문서에서 관찰되는 데이터로, 각 단어는 고유의 단어 ID를 가지고 있음.
- 문서(d): 여러 단어들로 구성된 텍스트. 각 문서는 다양한 주제의 혼합으로 이루어짐.
- 주제(z): 주제는 단어의 분포를 나타내며, 각 주제는 특정 단어들의 집합을 나타냄.
- 말뭉치(corpus): 문서들의 집합으로, 분석의 대상이 되는 전체 텍스트 데이터.
📚 LDA의 동작 과정
LDA는 각 문서에서 주제를 추론하고 각 주제에서 단어를 추론하는 역방향 생성 모델로 동작한다.
수학적인 내용은 너무 어려워서 개념적인 이해만이라도 되도록 간단히 표현해봤다.
- 문서-단어 행렬 생성: 데이터에 있는 문서를 단어의 등장 빈도로 나타냄
- 사전 확률 분포 설정: 주제에 포함될 단어들에 대한 초기 확률을 무작위로 설정
- 토픽 할당: 각 문서의 각 단어에 대해 확률적으로 주제를 할당
- 최적화: 각 문서의 주제 분포와 주제의 단어 분포를 반복적으로 최적화해 문서에 가장 적합한 주제들을 도출
📚 LDA의 결과 해석
LDA 모델이 학습되면 다음과 같은 정보를 얻을 수 있다
- 문서에서 주제 분포: 각 문서가 어떤 주제들로 구성되어 있는지 (각 주제에 대한 확률).
- 주제에서 단어 분포: 각 주제가 어떤 단어들로 이루어져 있는지 (각 단어에 대한 확률).
- 주제 키워드: 각 주제에 가장 관련된 키워드들.
✨ 예시
문서 A는 40%의 확률로 "스포츠", 60%의 확률로 "정치" 주제를 다루고 있다.
"스포츠" 주제는 '축구', '선수', '경기'와 같은 단어들과 강하게 연관되어 있다.
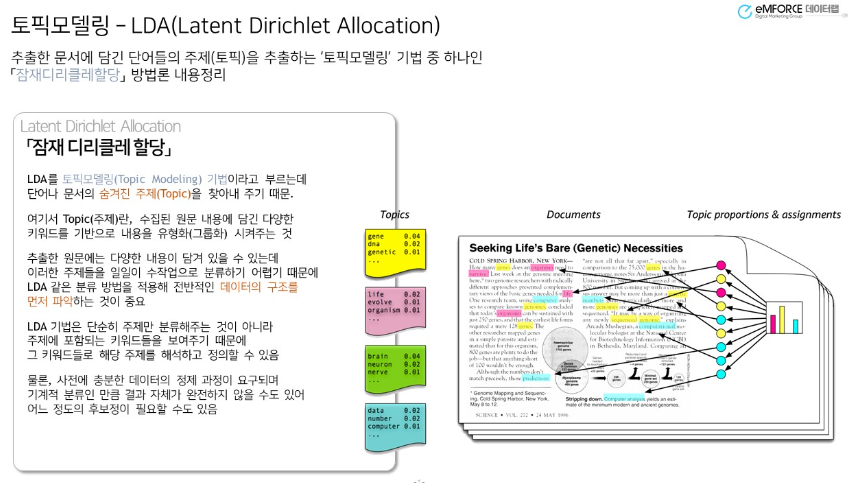
- 출처 : http://bigdata.emforce.co.kr/index.php/2020072401/
솔직히 그림 봐도 잘 이해가 안돼서 내가 볼라구 가져온 것🤭 ㅎ
3. 그게 군집 분석이랑 뭐가 달라
주제 분석(Topic Modeling)과 군집 분석(Clustering)은 둘 다 데이터를 그룹화하는 기법이지만, 그 목적과 방법이 다르다.
-
주제 분석(Topic Modeling): 문서에서 숨겨진 주제를 찾아내는 데 중점을 둔다. 주제 분석은 문서나 텍스트에서 자주 등장하는 단어들의 패턴을 기반으로, 텍스트가 어떤 주제를 포함하고 있는지 알아내는 방법이다.
예를 들어, LDA(잠재 디리클레 할당)를 사용하여 여러 문서에서 주제를 찾아내고, 각 문서에 주제가 어느 정도 포함되어 있는지를 확률적으로 계산한다. 이때, 각 주제는 특정 단어들의 분포로 구성된다. -
군집 분석(Clustering): 데이터를 비슷한 속성에 따라 여러 그룹으로 나누는 방법. 군집 분석은 데이터를 비슷한 특성이나 패턴에 따라 자동으로 묶는 데 사용된다. 텍스트 데이터뿐만 아니라, 숫자 데이터, 이미지 등 다양한 데이터에서 사용 가능하다. 기법은 K-means, DBSCAN, 계층적 군집화 등 여러 가지 방법이 있으며 군집 분석에서는 주제 대신 데이터의 유사성을 기반으로 그룹을 나눈다.
🕵️♂️조금 더 자세히 설명하자면,
-
주제(Topic): 주제는 특정 범주나 카테고리에 속하는 내용적인 개념. 여러 문서에서 등장하는 특정 단어들이 서로 밀접한 관계를 맺고 있다면, 이 단어들이 묶여 하나의 주제를 형성함. 이는 텍스트 내에서 내용의 중심을 발견하는 과정. LDA 같은 주제 분석 알고리즘은 이 단어들의 패턴을 보고, 그 문서가 어떤 주제를 포함하고 있는지 추출함.
-
그룹화(Grouping): 그룹화는 데이터 간의 유사성이나 특성에 따라 데이터를 묶는 행위. 군집 분석에서는 유사한 특성을 가진 데이터를 한 그룹으로 묶는데 이 때 데이터의 속성을 기준으로 그룹이 나뉘게 된다. 즉, 그룹화는 데이터 사이의 패턴이나 연관성을 기반으로 분류하는 것.
✨ 예시:
- 주제 분석: 텍스트 데이터에서 특정 단어들이 반복적으로 나타나면, 이를 기반으로 "교육", "기술", "AI"와 같은 주제들이 발견될 수 있음.
- 군집 분석: 주제와 무관하게 데이터의 유사한 속성(ex: 크기, 거리 등)을 기준으로 데이터를 묶는 과정. 예를 들어, 나이와 수입을 기준으로 사람들을 여러 그룹으로 나누는 것이 군집 분석입니다.
4. 주제분석은 어디에 활용될까?
뉴스 기사 분류: 뉴스 기사를 주제별로 분류하여 독자에게 추천하거나, 언론사 내부에서 자동으로 분류할 때 활용.
리뷰 분석: 고객 리뷰를 분석하여, 특정 제품이나 서비스에 대한 주요 이슈나 장점 파악.
SNS 데이터 분석: 소셜 미디어 데이터를 분석하여 사람들이 주로 논의하는 주제나 트렌드를 파악.
학술 논문 분석: 대량의 학술 논문을 주제별로 분류하고, 관련 논문들을 탐색.
주제 분석은 방대한 양의 텍스트에서 대략적인 맥락을 보여주는 기법이라고 보면 된다. 어떤 토픽인지 결정하는 것은 분석가의 인사이트 영역이기 때문에, 주제 분석 외에도 다양한 분석을 진행해가면서 문서를 씹고 뜯고 맛보고 즐기면 된다(?)
5. 뭐 다 좋대. 한계점은?
📚 장점
- 대규모 텍스트 데이터 처리 가능: 대량의 비정형 텍스트 데이터를 효율적으로 처리하여 주제를 자동으로 추출.
- 비지도 학습: 주제나 레이블 없이도 텍스트 데이터를 분석할 수 있고, 분석자의 주관을 최소화.
- 효율적 주제 탐색: 각 문서의 핵심 주제를 자동으로 탐지하여, 효율적으로 문서들을 요약, 분류함.
📚 한계
- 사전 주제 수 설정 필요: LDA는 사용자가 미리 설정한 주제 수에 따라 결과가 달라진다. 너무 적거나 많은 주제 수는 적절한 결과를 도출하지 못할 수 있음.
- 짧은 문서에 대한 분석 한계: 주로 긴 문서에서 더 효과적이고, 문서가 짧으면 주제 추출이 어려워질 수 있다.
- 해석의 모호성: 추출된 주제를 분석가가 해석하는 과정에서 모호할 수 있으며, 주제가 명확하지 않은 경우가 발생할 수 있다.
📚 LDA 외의 주제 분석 기법
- NMF (Non-negative Matrix Factorization): 행렬 분해 기법을 사용하여 주제를 추출하는 방법.
- BERT 토픽 모델링: 사전 학습된 BERT 모델을 활용해 보다 정교하게 문서의 의미와 주제를 추출하는 방법.
- LSA (Latent Semantic Analysis): 단어 간의 의미적 유사성을 기반으로 주제를 추출하는 방법.
아직 실무에 적응하느라 바쁘지만
같이 일하시는 분들이 다 열정적이고 똑똑하신 분들이어서😎
매번 공부할게 넘쳐난다(LDA도 같은 직원분이 쓰셔서 알게 되었다)
다들 열심히 사시는구나 부럽기도 하고, 나도 열심히 해야겠다 자극도 되니까 더 좋다🐣
요즘 DA 직무와는 사뭇 다르게 쿼리 짜고, 서버 올리고 로직 짜고 했었는데 ( 아닌가? DA 직군도 다 할줄 아는 내용인가?)
오랜만에 분석하니 또 재미있다
그럼 다음 일은 무엇일까 두근두근 🤗
참고 문헌
https://wikidocs.net/30708
http://bigdata.emforce.co.kr/index.php/2020072401/
