오늘은 아침에 강의 듣는것보다는 자신감을 고취시키기 위하여 sql 코드카타를 1번부터 다시 풀어보았다. 원래는 답을 푸는것에 집중했다면, 이번에는 검사를 같이해보았다. 근데 내가 원하는 답이 나오지 않아 당황,, 일단 밑의 문제이다.
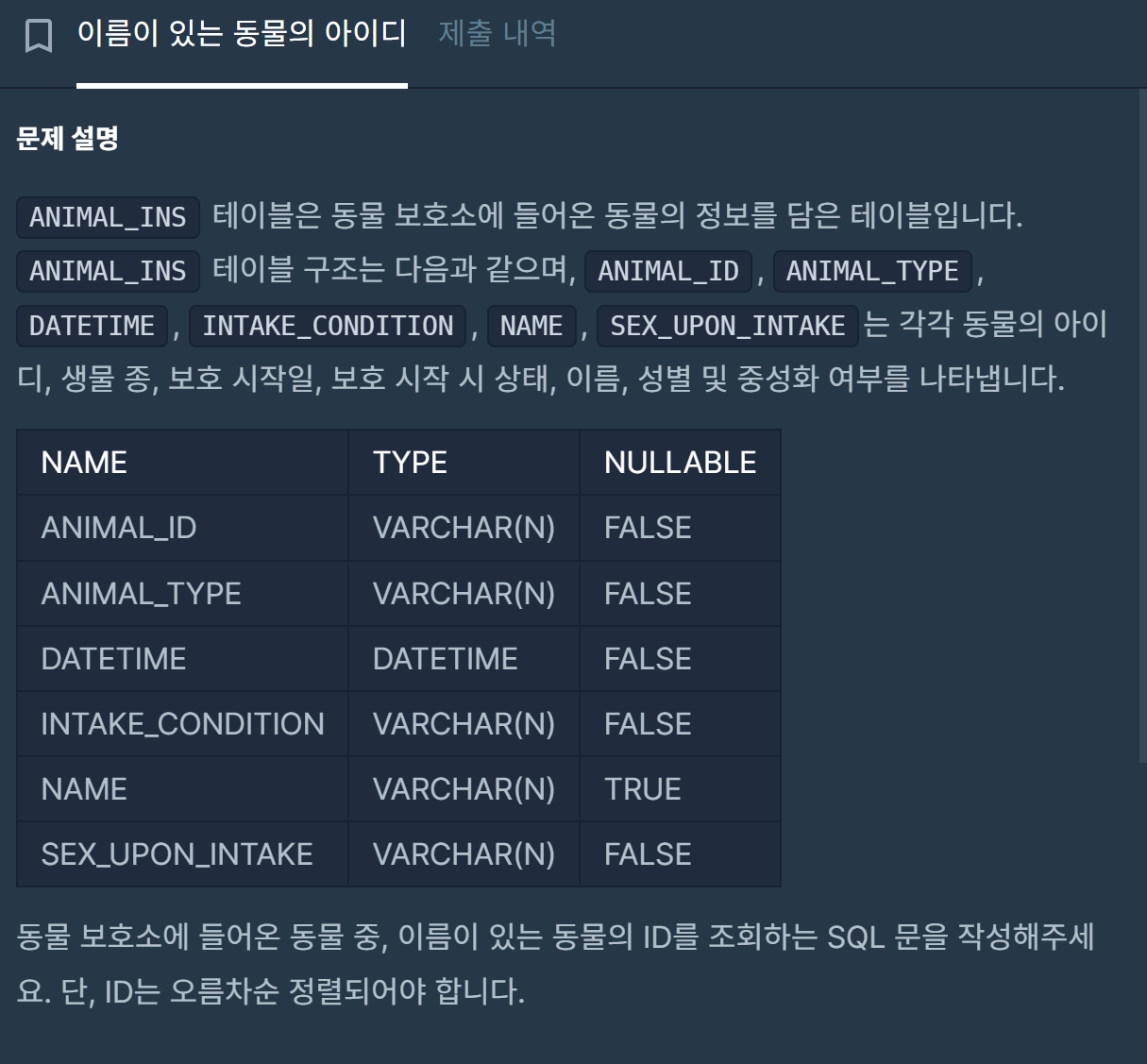
처음으로는 전체 테이블 조회를 해보았음(select * from animal_ins)
그리고 나서는 조건을 걸어서 name컬럼의 빈값들이 얼마나 있는지 조회를 해보려고 하였으나 아무런 행이 나오지 않아서 1차 당황을 했다. 오잉?
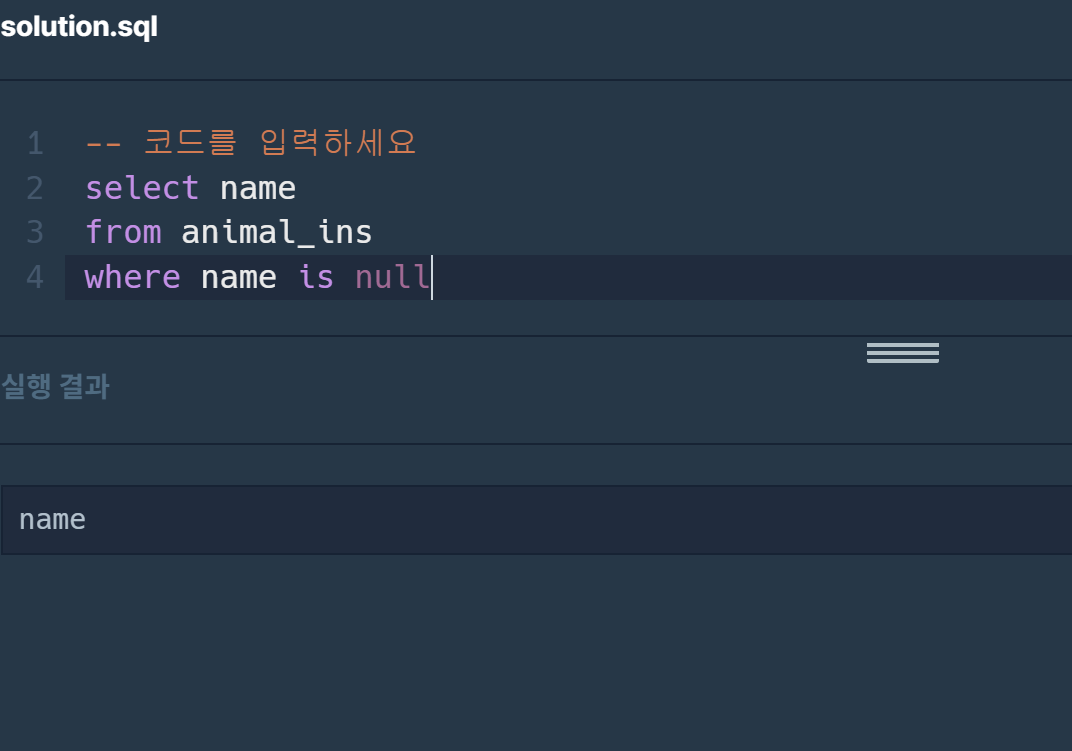
그래서 뭔가 잘못된건가 싶어 count(name)을 해보았으나 값이 0이 뜬다. 도대체 뭐지 싶어서 구글링 시작
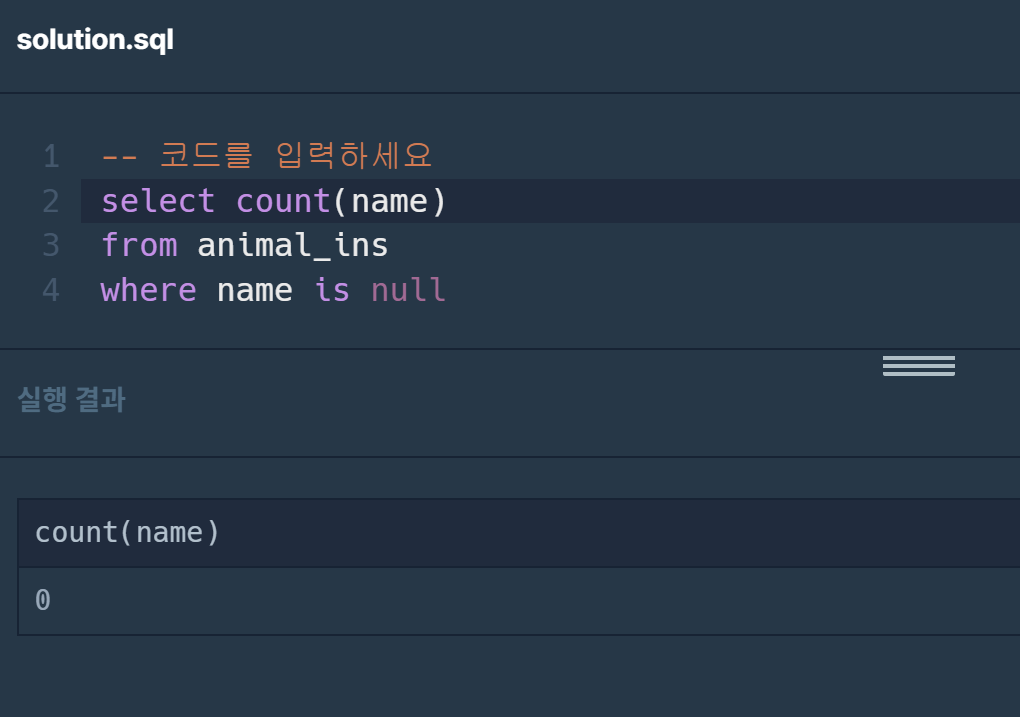
💡알게 된 중요한 사실은 빈값이 다 null값이 아니라는 사실이다.
'빈값 <> null','빈값 != null'
이 테이블에서 name컬럼이 비어있는 곳은 null값이 되어있는 것이 아니라 진짜로 empty 그 자체이다. 그래서 is null이라는 조건을 주었을 때 아무것도 나오지 않은 것이다. -실제로 비어있는 name컬럼을 보았을 때 나는 비어있는 값은 모두 null값이라고 생각했다.-> 내가생각했던 그동안의 규칙. 하지만 오늘 그것이 아니라는 사실을 알게 되었다.->그렇다면 지금 이 animal_ins테이블에서 name컬럼이 비어있는 곳은 null값이 주어지지 않았고, 비어있다는 소리인데 이 비어있는 컬럼을 어떻게 찾아내지?->
- 일단은 mysql환경에서는 공백값과 null값을 구분하지만 oracle환경에서는 공백값과 null값을 동일하게 본다고 한다. 데이터베이스에 따라서(환경에 따라서) 조금씩 다른 것 같다.
- 공백값만 뽑아내기 위해서 별 공식을 다 써봄. 하지만 나오지 않음.<> ' ', =!' ', like '% %', = ' ', is empty(얘는 혹시나 해서 써봤는데 이런 문법은 존재하지 않았음), ->튜터님 help,, 포기포기,, 분명 비어있는 값이 있었지만 trim을 사용해도, null값을 다시 조회해보았을 때 갑자기 뿅하고 하나가 생겼다.. 어이없음. 더 혼란스러워짐.. 그냥 포기,,,
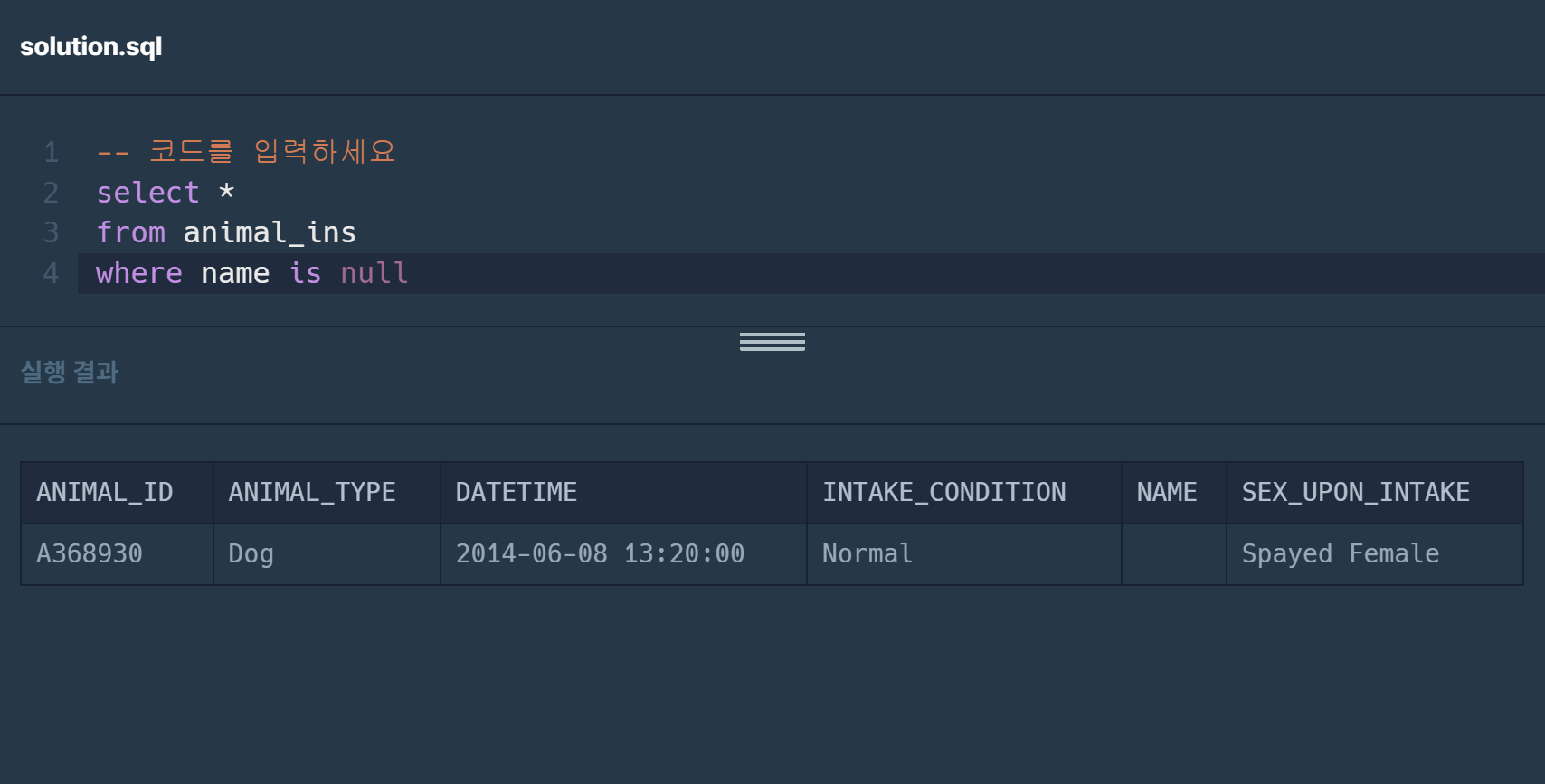
아아,, 그,, 설마 아까 select name 했을 때 저게 값이 나온거였나,,,? 아무것도 없으니 아무것도 안나온 상태로 값을 보여준거였나ㅏ,,,?
->null값이면 카운트로 select 했을때 나오지 않는다
COUNT(*) → 행 자체를 세니까 NULL이든 뭐든 상관없이 조건만 맞으면 카운트 됨.
COUNT(column) → 해당 컬럼의 값이 NULL이 아니어야 카운트됨.
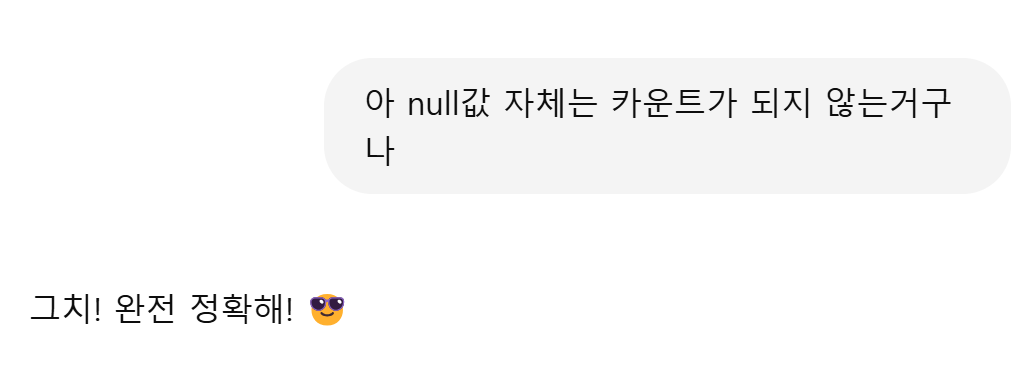
count(name)을 하면 name안에 있는 null은 제외되고 카운트가 된다.
몇건이 있는지 알려면 count(1)또는 count(*)을 쓰면 된다.
->지금까지 name컬럼을 조회해서(name is null이란 조건을 준다음) 혼동했던 것 같다. 결과적으로 공백값은 없었고, null값만 한개 존재한다는 것을 알게 됨. 전체 데이터의 행은 100개이고 거기서 name컬럼의 null값을 제외한 컬럼은 모두 99행인 것을 알게 되었다.
공백만 있는 행 검사:
SELECT *
FROM ANIMAL_INS
WHERE length(name) = 1
name 컬럼의 길이를 1개 뽑는것.. 그리고 그 외의 trim이라는 함수를 사용할 수도 있는데 암튼 다 해봤는데 나오지 않았다.- 이거 할 때 약간 정신이 아득해짐,,
파이선 베이직 반 1. 표준입출력- 문제4,5번 풀이

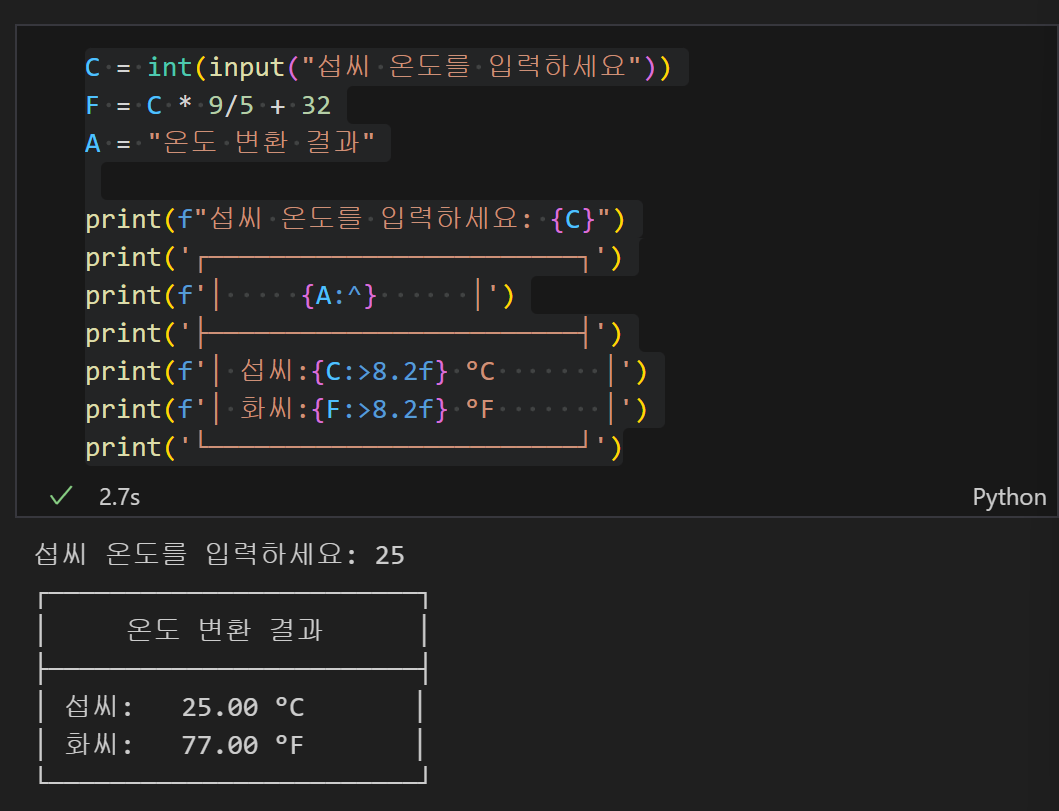
여기서 다시 정리해야할 부분은 저 포맷팅 할 시에 변수 넣어줄 때{}표시 해주는거랑, 변수에다가 :콜론을 해주면, 그 변수에 대한 포맷을 시작한다는 의미이다. 그리고 정렬표시가 먼저 오고 그 뒤에 숫자(몇칸 설정해줄지 지정)가 온 뒤에 소숫점 포맷이 온다. .2f 이렇게. f는 float형. 실수형으로 해준다는 소리이다. 당연히 i는 오지 못하는게(int)소수점 있다는거 자체가 실수형이기 때문.
중간에 저 섭씨 표시가 vscode에서 먹지 않아가지고 그거 고치느라 애 좀 먹었다. 그 무슨.. 그... 뭐시기..UTF-8을 설정해주었다. 그 과정도 쉽지 않았음. 약간 또 다시한번 멘붕..
https://youtu.be/-YSt8GdsIXE?si=3nKXVij_0AThAPqq
하지만 난 이겨냈다... 무려 쳇지피티가 눈치채지못한 부분들에서 나혼자 다시 시도해봤는데. 됐다. 그래서 지피티한테 뭐라함.(얘는 진짜 웃긴게 자기도 몰랐으면서 내가 된다하니까. 그래그거 맞아. 하면서 마치 자기가 알고있었다는 듯이말함.. 노어이..) 암튼-

해결완료-⭐

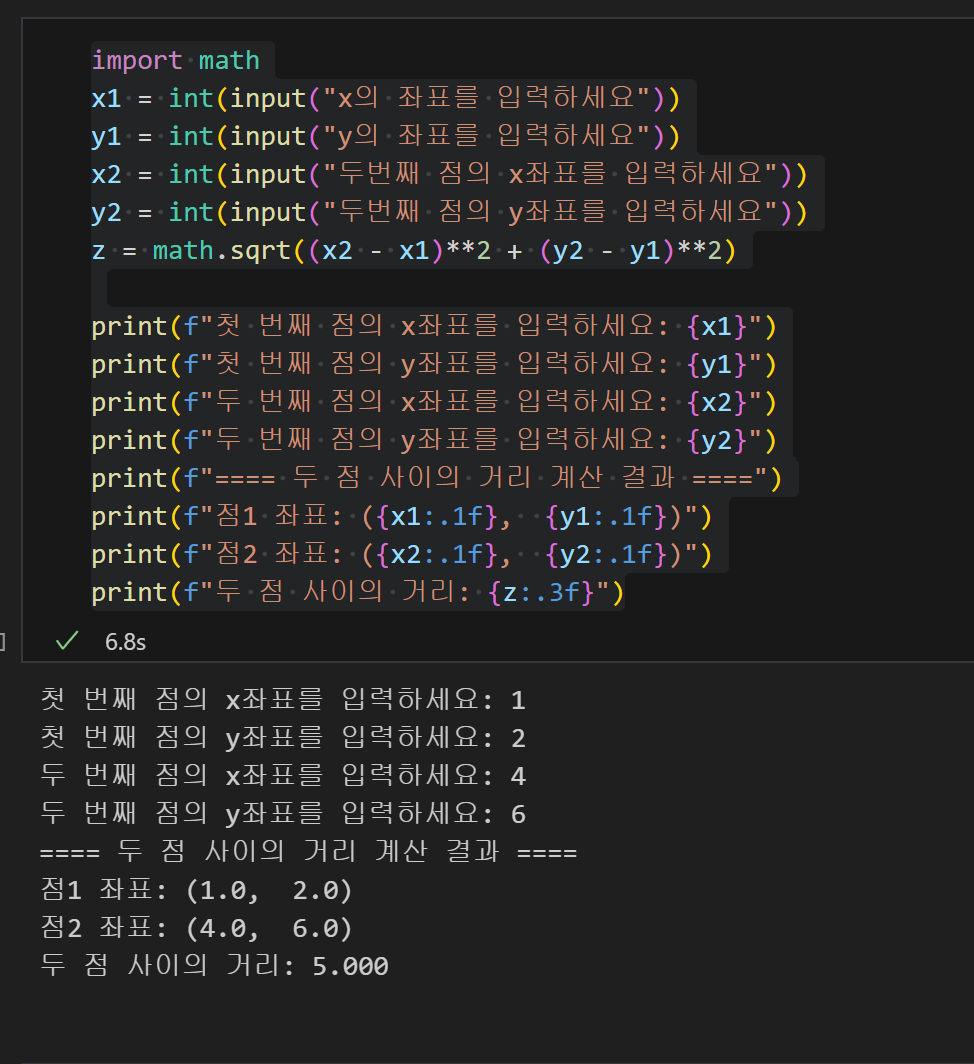
이게 한번 이해하고 나니까 푸는 속도랑 자신감이 확 붙어서 쉬워졌다. 역시 사람은 계속 해봐야 는다. 그리고 이 문제에서 햇갈렸던 것은 거리 계산 공식인데 저 수식을 그대로 코드에다가 복붙하니까 알아듣지 못해서 바꿔줘야 했다.
제곱은-> **2로, 루트는 **0.5를 해줄 수도 있고, 아니면 math라이브러리를 불러와서 .sqrt를 써주면 루트를 계산해주는 방법이 있다.
이렇게 1. 자료형 및 연산자, 2. 표준 입출력 파트 복습 및 문제 풀이 완료-!



내 롤모델분,,, 하,,, 진짜 대단하고 닮고 싶습니다..버티라구 내자신!!
오늘 배운거 새로 알게된 점들만 정리
-시계열 데이터: 시간에 따라 변하는 데이터. 시간 순서에 따라 수집된 데이터이다. ex)주가, 거래량, 날씨, 트래픽, 심박수, 환율 등
-금융에서는 결측치 발생 시 평균보다는 중앙값을 사용한다.-중앙값이 조금 더 잘 나타내줌. 평균은 이상치가 있을 경우에(차이가 많이 나는 찐부자들) 영향을 많이 받기 때문이다. - 극단값이 있을 경우에는 중앙값을 사용한다.(평균보다는)
-이동평균: 최근 값들의 평균을 계속 구하면서 변화 추세를 부드럽게 보는 방법. 다시 정리하면 가장 최근 값들만 뽑아서 평균을 구하는것이다. ->평균이 계속 달라짐. 최근 값들의 데이터가 새로 쌓이기 때문에
ex) 3일 이동 평균을 구한다고 하면
가장 최근의 3일 평균값을 계속 구해나가는것이다.
10일은->8,9,10일의 평균값.
11일은->9,10,11일의 평균값.
12일은->10,11,12일의 평균값.
복습 정리
-pandas에서 결측값 제거->.dropna()사용. :결측값이 하나라도 있으면 해당 '행'을 제거한다. -괄호안에 axis=1을 해주면 결측값이 있는 열을 날리는 것이다.
-.fillna(): 결측값 대체해 줄 때 사용
-.median(): 중앙값
-.mode(): 최빈값 - .mode().iloc[0]:iloc은 몇번째 최빈값을 가져올건지 지정하는 것. 최빈값이 겹칠수도 있다고 한다. 예를 들어 2가 30번 나왔는데 3도 30번 나왔을 경우에.
-결측치를 처리하는 것에는 두가지 방법이 있다. 삭제하거나 대체하거나.
삭제는 결측치가 매우 소수일 때 적용하고, 대체는 두가지로 또 나뉘는데, 수치형데이터일때는 평균 또는 중앙값으로 대체한다.(데이터 분포 왜곡이 비교적 적다) 범주형 데이터일 때는 최빈값으로 대체한다. 또는 예측모델로 대체하는 방법도 있긴하다.
베이직반 라이브세션:
-빅데이터분석기사
-현업에서는 데이터 품질 모니터링 의무가 있다
-대부분 머신러닝은 데싸분들이 하신다
-아나콘다는 기본 패키지들이 다 포함되어 있음
-문자열 나누기.split()
-help[list]를 파이선에서 돌리면-어떤 방법 쓸 수 있는지 알려줌
-a.remove(3)을 하면 a라는 리스트에서 3이라는 숫자를 다 지우지는 않는다. 처음의 3만 지움.
-a.keys():키값만 호출. 뒤에()요것은 함수 호출의 뜻이 있다(처음 앎)
고생함~~~ 아 저녁에는 약간 공부못함.. 내일 다시화이팅!!!
+아 오늘 아티클스터디로 실무에서의 통계지식활용에 대한 글을 읽었는데, 통계 기초지식을 조금 더 내 말로 정리해야겠다는 생각을 했다.
