음.. 오늘은 통계 강의를 듣고 드디어 머신러닝 강의를 들었다.
통계랑 머신러닝이랑 (자꾸 러닝머신이라고 머릿속에서 맴돈다,,) 같이 들어야 할 듯하다.
통계 강의
- 정말 의미가 있는지를 확인하기 위해 가설 검정을 한다. A/B test 유의미한가.
- t-test: 두 그룹 간의 평균 차이가 통계적으로 유의미한지 여부를 판단하는 방법. p-value 피벨류하면 튜터님의 목소리가 귀에 맴돈다. 우연이야? 우연이 아니면 귀무가설 기각. 유의수준 0.05라고 설정 시 그 수치보다 낮아야 함. ->그래야 대립가설을 채택할 수 있음. 모든 기업에서는 귀무가설이 기각되기를 원한다.
-가설검정: 데이터가 특정 가설을 지지하는지에 대해 검정한다. 공부하면서 느끼는건데 되게 설명이 다 좀 어렵게 느껴진다. 조금 더 쉽게 설명할 수는 없을까?-> 그냥 말대로 가설을 검정한다는 거다. 가설을 설정하고 나서 그 가설이 실제로 맞는지 확인하는 과정이라고 생각하면 될 것 같다.
두가지 전략이 있는데, 그 중에 나는 두번째 방법을 더 선호하는 것 같다.
첫번째 방법: 미리 가설을 세우고 검증해 나가는 방법=확증적 자료분석
두번째 방법: 가설을 먼저 정하지 않고 데이터를 탐색해보면서 가설 후보들을 찾고 데이터의 특징을 찾는 것=탐색적 자료분석(EDA)
오늘 강의를 들으면서 알게된 점은 유의수준이 0.05가 디폴트 값은 맞는데, 데이터에 따라서 그 유의수준을 바꿀 수도 있다는 것을 알게 되었다. 유의수준은 그때마다 다르게 쓰일 수 있다는 것. 유의수준이란 것은 결과값이 의미가 있는 것처럼 보이지만 우연일 확률을 얼마나 허용할지의 기준이다.
t검정: 두 집단 간의 평균 차이가 통계적으로 유의미한지 확인하는 검정 방법
독립표본 t검정: 두 독립된 그룹의 평균 비교
대응표본 t검정: 동일한 그룹의 사전/사후 평균 비교
다중검정-볼페르니 검정.
카이제곱 검정-범주형 데이터 분석에 사용한다.
- 적합도 검정-관찰된 분포와 기대된 분포가 일치하는지 검정한다.
- 독립성 검정-p값이 높으면 데이터가 귀무 가설에 잘 맞는다.:두 범주형 변수 간의 독립성을 검정하는 것이다. p값(p-value)이 높으면 두 변수간의 관계가 연관성이 없다:독립성이 있다는 뜻이다.
제1종 오류: 귀무가설이 참인데 기각해버린것->아무런 영향이 없는데 영향이 있다고 하는 것: 잘못된 긍정
제 2종 오류: 귀무가설이 거짓인데 참이라고 채택해버리는 것->대립가설을 채택해야하는데 대립가설을 기각하는 것: 영향이 있는데 영향이 없다고 하는 것
제 1종 오류와 제 2종 오류는 상충관계에 있다. 하나가 올라가면 하나가 내려감. 반대로 하나가 내려가면 다른 하나가 올라감.
다중검정을 하면 오류범위가 커져서 1종오류가 발생할 확률이 높아진다.
<회귀>: Regression. 사람들이 자식을 낳고 그 자식이 또 자식을 낳게 되면 작은 사람은 계속 작고 키가 큰 사람은 계속 크다기보다는 사람의 키가 평균으로 돌아오려는 성향이 있더라-> regression이란 단어를 사용하기 시작함. 평균적으로 돌아오려는 성향.
->무언가 예측을 하거나, 경향성을 파악하고자 하는 경우에 '회귀'를 쓰게 됨.
-단순 선형회귀: 직선과 같은 상태를 보이는 것. 변수가 1개인 것.
y = ax + b
선: 직선
형: 모양 이라는 뜻이다.
하나의 독립변수와 종속변수와의 관계를 분석 및 예측.
ex)광고비(x)와 매출(y)간의 관계 분석.
현재의 광고비를 바탕으로 예상되는 매출 예측 가능
절편: x가 0일 때 y의 고유값
<머신러닝>
-인공지능: 사람의 지능적인 작업을 기계가 수행하도록 만드는 광범위한 개념이다. -> 기계가 사람이 생각하고 행동하는 것처럼 무엇인가 자동으로 수행하는 개념..
-머신러닝: 데이터로부터 특징이나 규칙을 찾아내서 '학습' 하는 것->알고리즘을 만드는 기술.
-딥러닝: 사람의 뇌의 구조와 비슷(?)한 인공신경망. 인공신경망을 여러겹 쌓아서 복잡한 정보를 학습할 수 있음. 쳇지피티도 딥러닝을 사용해 만들어진 오픈AI이다. (요즘 내 공부 메이트)
머신러닝은 대량의 데이터 처리와 분석을 한다. 사람의 손을 타지 않고 스스로 학습, 분석을 한다.
빅데이터란 일반적인 방법으로는 저장 및 분석하기 힘들만큼 방대한 양의 데이터이다.
머신러닝이 쓰이는 대표적인 분야
제조업, 금융, 마케팅 등등
머신러닝 vs 통계 분석
머신러닝은 예측. 매출이 잘 나오려나? 얼마나 정확하게 예측하는지가 중요 통계분석은 이 변수와 저 변수 사이에 유의미한 관계가 있는가? 를 알아보는 것둘 다 데이터가 많을수록 좋다. 하지만 통계는 데이터가 적을 경우 사람이 컨트롤할 수 있지만, 머신러닝은 사람의 손을 타지 않기 때문에 데이터가 너무 적다면 머신러닝 보다는 통계를 사용하는 것이 나을 수도 있음.
머신러닝의 3가지 학습 종류: 지도학습, 비지도 학습, 강화 학습

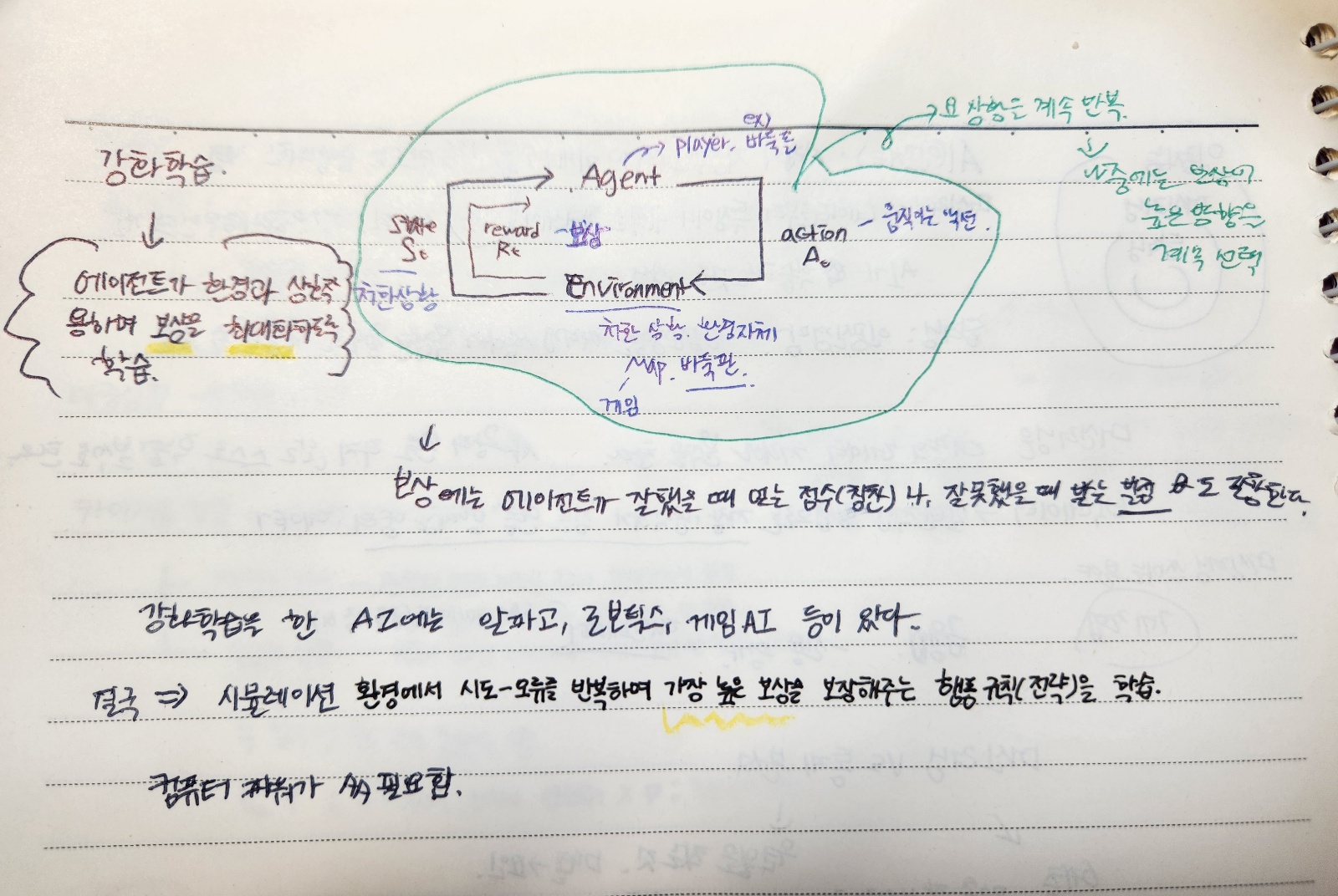

시간이 12시를 향하고 있기도 하고 아직 못 씻었기도 하고,, 허리가 좀 아픈 것 같기도 하고. 목은 좀 뻐근하기도 하고 해서 노트에 필기한 것으로 오늘은 대체한다.
🐢오늘의 회고:
아침을 먹으면서 강의를 듣고, 이제 오전스크럼 써야 해서 그거 확인하러 들어갔는데, 아직 만들어져있지 않아서 다시 나오고, 또 조원들끼리 스크럼내용 나눠야되서 이야기하고, 아침 먹은거 치우고, 양치하고 등등 계속 끊기니까 강의 듣는데 시간이 오래 걸렸다. 흐름이 끊기니 들었던거 다시 듣고 다시듣고, 아 이게 뭐였지 하면서 다시 앞으로 돌아가는 현상이 많았다.(시간 낭비)
그냥 아침 먹지말고 아예 집중해서 공부하는 시간으로 만들어야겠다.=>이미 들었던 강의를 또 듣는 복습방식은 먹으면서도 듣기 수월하지만, 처음 배우는 개념은 적으면서 더 집중해서 들어야 하기 때문에 밥먹으면서 듣기에는 적합하지 않다는 것을 오늘 깨달았다.-차라리 밥먹을 때 들으려면 처음 배우는 개념 또는 처음 듣는 강의 말고 복습하는 용으로 들었던 강의 수강하면 좋을 것 같음.
그리고 오늘은 집중을 잘 못하고 딴짓했던 시간이 있었다(도대체 왜그러니정말로..)+잘하는 분 벨로그 한번 들어가보았다가 오히려 비교되면서 자신감 급하락 및 멘탈 하락-보지말아야겠다.
다시한번 마음 다잡는 용도로 이 영상을 봅시다.
https://www.youtube.com/watch?v=aKu76y4hXU0
