<머신러닝 이상치 탐지>
- 이상치: 정상범위를 벗어남
: 이상치 탐지 접근 방법으로는 통계기반, 머신러닝 기법이 있다.
-통계기반: IQR,Z-SCORE
-머신러닝: 대부분이 비지도학습이다.라벨이 없음.(=정답이 없음)
통계기반 이상치 탐지는 정규분포를 따른다는 가정하에 진행한다. long_tail같은것은 불가하다는 말.
- z-score: 각 데이터가 평균으로부터 몇 표준편차(시그마)가 떨어져 있는지를 나타내는 값. 보통 3시그마를 사용. 절댓값이 일정기준을 넘으면 이상치로 간주한다.
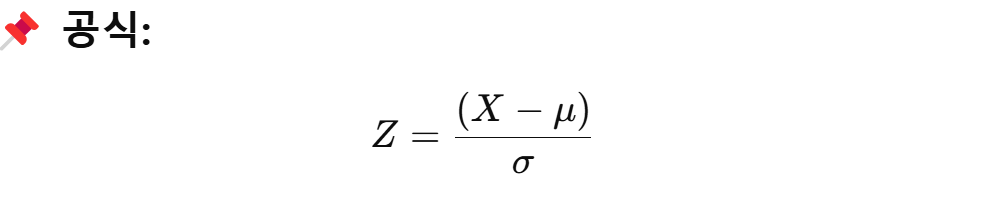
z = 0 이면 평균과 같다.
z = +2 이면 평균보다 2표준편차만큼 크다
z = -1 이면 평균보다 1표준편차만큼 작다
이상치를 판단할 때: 보통 z>3 또는 z<-3이면 이상치로 판단한다.
- IQR: 상위 25%(Q1)와 하위25%(Q3) 사이 범위를 구한다. 데이터의 중앙값 주변의 분포 폭을 나타낸다.
공식: IQR = Q3 - Q1
이상치를 판단할 때: 하한 Q1-1.5xIQR
상한 Q3+1.5xIQR
이 범위 밖의 값은 이상치로 간주.
z-score은 데이터가 정규분포에 가까울 때 더 잘 작동하고
IQR은 비정규분포나 극단값이 있는 데이터에 유리하다. ex)박스플롯
왜 이상치가 중요한가?
- 보안분야: 이상거래 탐지->사기 예방
- 제조분야: 센서 이상 탐지->사전에 고장 예측
- 의료 분야: 환자 상태 모니터링->조기 진단
지도학습 vs 비지도 학습
-지도학습: 레이블이 필요하고 준비할 것이 많다. 실제 현업에서는 데이터가 많아도 레이블이 안되는 것들이 있다고 한다.
-비지도 학습: 레이블이 없어도 된다. 시간과 비용이 절약된다.(준비할게 많지 않음) 하지만 평가하기가 어렵다. 일부 데이터에 대해 괜찮으면 신뢰할 수 있다고 한단한다.
👉🏼 지도학습은 사실은 '분류'이다. 정상/이상 라벨이 있는 데이터로 분류모델을 학습한다. 그래서 사실은 그 라벨에 따른 의존적인 학습방법이다.
👉🏼 비지도학습은 대부분의 데이터가 정상이라는 가정하에 진행하기 때문에 정상 데이터만으로 모델을 학습한다. 그래서 그 정상치와 어느정도 차이가 나는 그 차이(보통은 통계적으로 설정한다)를 사람이 설정해주면 이상치를 찾게 된다.
=>정상을 아니까 다른 것을 발견했을 때 이상치로 간주한다.
=>라벨 없이도 모델 가능, 다양한 환경에 적용이 가능하다.
머신러닝 기법:
- isolation forest
- one-class svm
등이 있다.
✏️ 지도학습은 정해진 레이블 안에서만 학습하기 때문에 이상치를 찾을 때도 학습한 이상치만 찾아낼 수 있음. 하지만 비지도 학습은 정상 데이터들을 학습하기 때문에 다른 새로운 이상치가 나왔을 때도 발견이 가능하다. 알아서 구분됨. 지도학습은 새로운 이상치가 나오면 또 업데이트 해주어야 함.(학습시켜야 함)
<QCC 4회차 오답 정리>:
-오답원인 분석 후, "왜 틀렸는지", "정답은 어떤 구조로 흘러가는지" 요약 정리
문제 3번
- payments테이블, orders테이블 두개가 있음.

<나의 쿼리>
-- 버그를 악용한 사용자 수를 구하는 문제. 누군지는 안궁금함.
-- 첫째 버그 악용 사례: payments에는 user_id가 없는데, orders테이블에는 user_id가 있는 경우
-- 둘째 악용 사례: orders 테이블의 날짜가 pay_date의 날짜보다 빠른 경우
-- orders 테이블에 있지만 payments 테이블에 없는 경우 1가지)orders테이블에 left join 사용 후 null값이 있는 곳 찾으면 될 듯
-- 날짜 비교 하기
select distinct cnt
from
(select count (*) as cnt
from orders o left join payments p on o.user_id=p.user_id
where (p.user_id is null and o.user_id is not null) or o.order_date < p.pay_date) a
쿼리 실행 시 나온 답:
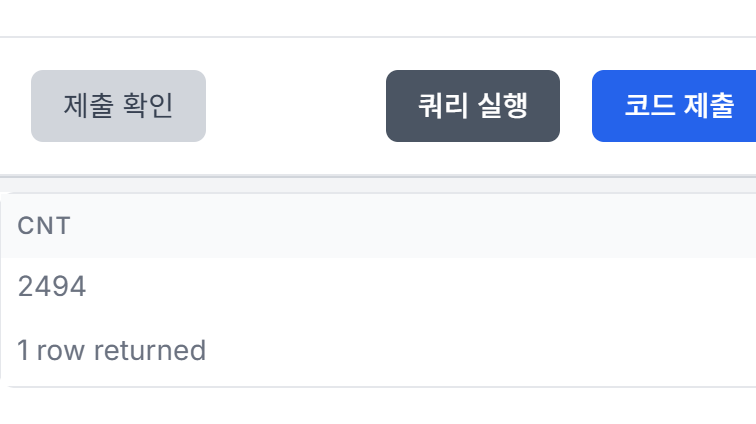
여기서 오답이 나온 이유는-
1. 중간에 문제가수정이 되었는데: '첫번째 결제일보다 이전에 상품을 주문한 사용자' 에서 첫번째 결제일이 추가됨. 나는 새로고침?을 하지 않아서 그런지 저 수정된 조건이 보이지 않았음..
다시 풀어보았을 때- 첫번째 결제일을 구할 시 payments의 min(pay_date)를 구하면 첫번째 결제일을 구할 수 있을 것 같음. 이것을 반영하여 조건을 수정해본다면: 주석 걸어놓은 둘째 악용 사례를 수정해보겠다.
-- 둘째 악용 사례: orders 테이블의 날짜가 min(pay_date)의 날짜보다 빠른 경우
-> 해 보았을 때 invalid use of group function이라는 에러 메세지가 뜬다. 흠,, where절에는 집계함수를 사용하지 못한다..
여기서 정답쿼리를 보자:
WITH first_payment AS (
SELECT
USER_ID,
MIN(PAY_DATE) AS FIRST_PAY_DATE
FROM qcc.payments
GROUP BY USER_ID
)
SELECT
COUNT(DISTINCT o.USER_ID) cnt
FROM qcc.orders o
LEFT JOIN first_payment fp
ON o.USER_ID = fp.USER_ID
WHERE fp.USER_ID IS NULL
OR o.ORDER_DATE < fp.FIRST_PAY_DATE
위 쿼리를 분석해 보았을 때: 먼저, 첫번째 결제일을 with구문으로 구한다. -> where절에 집계함수를 사용하지 못하니 오히려 좋은 방법이 되겠군. 근데 실제 with구문을 어떻게 활용하는거지?
그 다음은 상품주문(orders)테이블에서 user_id(사용자 아이디)를 count한다.(사실 이부분은 어차피 count를 사용하게 되면 null값은 빼주기 때문에 user_id를 사용하지 않아도 괜찮지 않을까 란 생각이 든다.)
그 이후에 테이블을 left join을 하는데,, 아까 만들어놓았던 그 첫 결제일테이블과 orders테이블을 조인한다. 물론 orders테이블의 순서가 먼저이다. -> 왜 첫 결제테이블과 orders테이블을 조인하는거지,,? where절에선 첫 결제데이터와 비교가 불가능하니 아예 with로 만들어준 후에 조인하는 것임.
본 쿼리에서 select절에 count 사용 시 distinct를 하는 이유는-> 실제 쿼리 돌려보니 distinct가 있고 없고의 차이가 있다. 겹치는 아이디가 있나보다. 확인을,, 해보니 겹치는 user_id가 있었음.-> 그 주문테이블이니까 한 사람이 주문을 꼭 한번만 하란법이 없으니까- 여러번 결제할 가능성이 있음. 그래서 distinct를 사용해주어야 함.
+그리고 내가 쓴 쿼리에서는 where (p.user_id is null and o.user_id is not null) 이렇게 p.user_id가 null이고 o.user_id가 null이 아니다 이렇게 지정해주었는데 사실 o.user_id가 null값이 있을수가 없기 때문에(왜냐면 orders테이블로 left join을 해주었으니까 orders테이블의 모든 데이터를 기준으로 묶어주는 것이기 때문에 null값이 있을 수가 없다.) 굳이 뒤의 조건은 빼주어도 괜찮다.
🐳정리해보자면: 첫주문날짜를 찾아야 하니 with구문으로 user_id별로 첫주문날짜:min(pay_date)를 구해준다.->
with first_date as (
select user_id, min(pay_date) first_pay
from payments
group by user_id)
그 이후에 주문 테이블과 첫주문날짜 테이블을 left join으로 묶어 준 후에 문제에서 말한 내용으로 조건을 줘야한다. 뽑아낼 때는 사용자 수를 구해야하니 중복값을 제거 해야한다.->
select count(distinct o.user_id)
from orders o left join first_date f
on o.user_id=f.user_id
where f.user_id is null
or o.order_date < f.first_pay
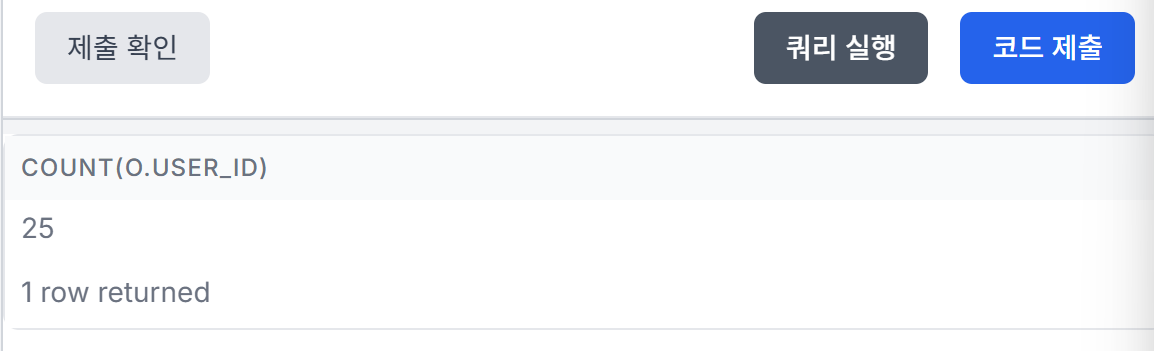
쿼리 실행 값=정답
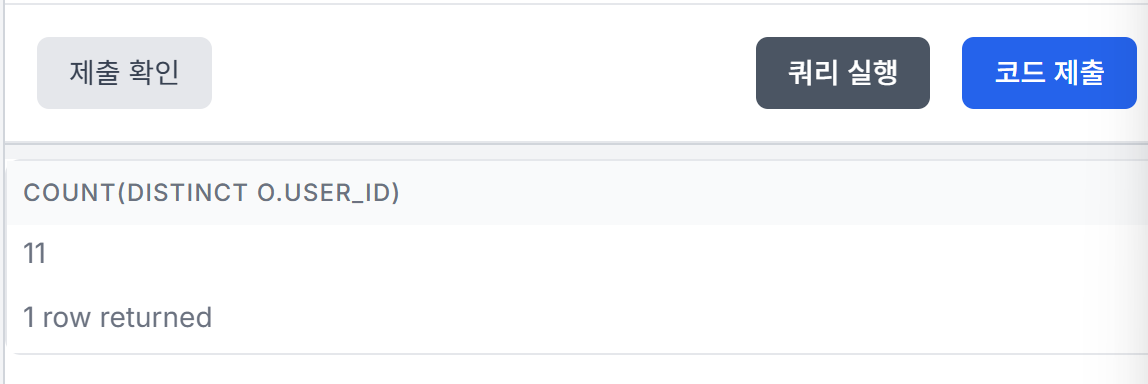
만약 distinct를 쓰지 않으면 실행 값이 25로 나온다. 마찬가지로 user_id로 구하지 않고 count()로 모든 행을 셌을 때도 동일한 값이 나온다. -> count()를 사용한 것이 오답임.
💡 내가 생각하지 못했던 부분:
1. 모든 행을 다 센 것-> 사람 수를 구해야 하는것 인지 하였지만, 한 사람이 여러번 주문한 것의 경우의 수를 생각하지 못했음. 이런 구매 테이블에서는 사람 수 구할 때는 여러번의 결제를 할 경우를 생각해서 distinct를 해주어야 한다는 것을 깨달았다.
2. left join 시 오른쪽에 조인했던 부분은 당연히 null값이 있을 수 있고, 왼쪽의 기준이 되는 테이블에는 null값이 없을 수가 없다는 것. 그래서 null값 찾아줄 때는 오른쪽에 조인하는 테이블의 null값만 찾아주면 된다는 것.
3. 조건절:where절에는 집계함수를 사용할 수 없으니,집계 함수를 사용해서 조건을 구해야 한다면 아예 그것으로 테이블을 하나 만들 수 있다는 것.은 솔직히 생각해내기 어려운 부분이었다. 보니까 with구문을 많이 사용하셔서 일단은 with구문을 어떻게 작성하는것까지는 공부해놓았는데, 실제로 사용할 시에 테이블로 join하는 부분에 대해서 알 수 있었다. 실제 예제를 많이 풀어보면서 with를 어떻게 사용하는지 다시 복습하고 풀어보아야겠다는 생각을 한다.
요즘에 특히 이번주가 집중이 특히나 안된다. 공부도 잘 안되고.. 내일은 카페가서 공부를 해볼까 고민된다. 하.. 제발.. 정신차려이친구야ㅏㅏㅏㅏㅏ
