vs code>>
vs code 조작하는게 어렵다. 처음에는 코랩으로 사용하다가: 사실 코랩도 익숙해지는데까지 진짜 오래걸렸다. 하지만 매번 마운트해야하고 불편하기도 하고 실제로 수준별 세션 할 때 vs code로 사용하기로 통일되어서 vs code로 갈아탔다. 어떤 화면은 코드를 추가해서 따로따로 실행해서 그 결과값을 볼 수 있는데 어떤 화면은 전체 코드가 실행되어서 도대체 어떻게 해야하는지 지금까지 다른 일하느라..? 못 물어보다가 이제서야 물어보게 되었다.
튜터님 says:이걸 아직까지도 모르면 안돼요🤨라고 단호하게 말씀하셔따. 많이 써보라고 하셨다. 안 써봐서 모르는거라고.. 많이 써보라고 하셔서 오늘 수업 때 주신 파일들 불러오기도 하고 왜 주황색이 되는지 깨닫기도 했다.
아니군데,, 괜히 튜터님께서 그렇게 말씀하시니까 또 자신감 하락,, 하,,
암튼 알게된 사실은: 코드 따로 작성하는 환경은 쥬피터 환경이다. 그래서 파일명에 .ipynb를 붙여주면 쥬피터노트북 환경으로 세팅이 된다.
그리고 어제 우리 지피티랑 했던 것-> 터미널 여는 방법은: ctrl+백틱(tab위에 있는 키) 누르면 터미널 환경이 켜진다. 만약에
ModuleNotFoundError: No module named 'yellowbrick' 같은 에러창이 뜨면 그 모듈이 설치되어있지 않다는 뜻이라서 직접 설치를 해주어야 한다. 여기서는 yellowbrick이라는 시각화 도구 라이브러리가 설치되지 않았다는 뜻이다. -> 터미널 연 후에 pip install yellowbrick 작성하고 엔터를 누르면 설치된다. 막 터미널에서 뭔 코드같은거,,? 영어들이 쫙 뜬다. 설치되는 과정임. 그거 다 끝나면 다시 실행을 누르면 됨.
맞다. 사실 그냥 지금까지는 어떻게 그냥 흘러가는대로 어떻게 하다보니 작동되어서 그냥 vscode 사용하고 그랬는데, 오늘 그래도 가서 물어보기를 잘했다..
엑셀파일을 불러오는것: 일단 그 파일탐색기에 저장되어있어야 하고, 원래 하던데로, pandas import한다음에 pd.read_csv(파일경로)로 불러오면 됨. 튜터님이 주신 엑셀파일도 csv로 읽어올 수 있었음.: csv파일은 주로 구조화된 텍스트 데이터를 다루는 데 사용되는 포맷이라서 텍스트 기반 파일이면 불러올 수 있음(엑셀파일 포함) 하지만 이미지, 비디오, 오디오, pdf 같은 파일들은 csv 형식으로 읽을 수가 없음. 기본적으로 텍스트 데이터, 숫자 데이터, 날짜 등의 구조화된 데이터를 다룰 때 사용한다. .csv,.txt파일,.xls,xlsx,sql 데이터 베이스 등
vs code는 저장 안 해놓으면 날라갈 수 있음. 부분적으로 자동저장되는 것도 있지만 해놓는게 확실함. 실제로 다른 파일 새로 열었을 때 이전에 했던 것들 다 날라가버림. 그전에는 프로그램 실행하면 다 열렸음. (전에 했던거 그대로) 저장하는 방법은:ctrl+S 그 다른 엑셀이나 다른 것들이랑 똑같음. 그리고 탭에 보면(제일 왼쪽에 파일들 볼 수 있는 곳) 거기에 그 똥그라미 검정색 붙어있으면 저장 안되어있는 거라고 함.
<라이브세션: 군집>
클러스터링=군집분석, 비지도 학습=> 우리가 모르는 우리 고객들의 특징을 찾는것임.
의미있는 패턴을 도출하기 위해서는 최소 3개월 이상의 데이터셋이 권장된다. 너무 길어도 안되고 너무 짧아도 안됨. 몇주간에 나올 수가 없음.(반복해야하기 때문에(실험을)) 그리고 너무 길어도(1년이상) 안됨.
<저번에 알았는데 또 까먹은 개념 정리>
-
시계열 데이터: 시간의 흐름에 따라 측정된 데이터를 의미한다. 시간에 따라 값이 변하는 데이터를 말함. 각 값이 특정 시간에 해당되며, 이 값들은 일정한 시간 간격을 두고 기록된다.
ex)주식 가격: 주식의 가격은 매일 , 매시간 혹은 매분씩 변화한다.
기온: 하루 동안의 기온 변화, 오전 9시, 12시, 3시 등으로 측정한 기온 값들
판매 데이터: 어떤 제품의 일일, 월간, 연간 판매량
웹사이트 방문자 수: 하루 동안의 시간대별 방문자 수
-> 시간 순서: 데이터가 시간에 따라 정렬된다.
연속성: 시간 간격이 일정하거나 일정하지 않은 시점에 관측된다.
상관 관계: 시간에 딸느 변화와 그 변화 사이에 어떤 관계가 있을지 분석하는 것.
ex)주식 가격이 이전 날의 주식 가격과 상관관계가 있을 수 있음.-> 오늘의 주식 가격이 어제의 주식 가격과 비슷한 흐름을 보일 확률이 높다는 것(대부분은 그렇지만 튀거나 확 빠지는 경우도 있음)
-기온은 오늘 기온이 어제 기온과 비슷하거나 특정 패턴을 따라갈 가능성이 있다는 것임.
-온도와 에어컨 사용량이 시간에 따라 어떻게 변화하는지 보고, 그 변화가 어떤 패턴을 보이는지 분석. -
Isolation Forest: 주로 이상탐지에 사용되는 머신러닝 알고리즘 중 하나. 비지도 학습. 대규모 데이터셋에서 이상 데이터를 빠르게 식별할 수 있도록 설계되어 있음.
-> 데이터를 격리 하는 방식으로 이상치를 탐지한다.
이상치는 다른 데이터와 다르게 특이한 패턴을 가지므로, 일반적인 데이터보다 적은 수의 분할로 쉽게 격리될 수 있다는 점을 이용한다. tree처럼 데이터를 분할하는 과정을 여러 번 반복하면서, 데이터 중 특이한 데이터를 빠르게 격리할 수 있는 방식으로 작동한다.
=> 격리가 적은 데이터는 이상치로 판단하는 이유: 이상치는 다른 데이터들보다 빨리 격리될 것이다. 라는 가정에 기반해 작동한다. 이상치는 정상적인 데이터들과 비교할 때 구조적으로 다르기 때문에, 더 적은 분할로 격리될 수 있다. - 이상치는 트리에서 몇 번만 분할하면 다른 데이터들과는 전혀 다른 특성을 가지기 때문에 바로 격리될 수 있다. 다른 데이터들과 거리가 멀기 때문에 적은 분할만으로 쉽게 구분이 가능하다.-> 그 특성이 다르기 때문에 분할 시에 이진(두개)로 나누면서 분할한다면: 결국 쉽게 분할된다는 소리이다. 결국 고립이 된다는 소리이다. -
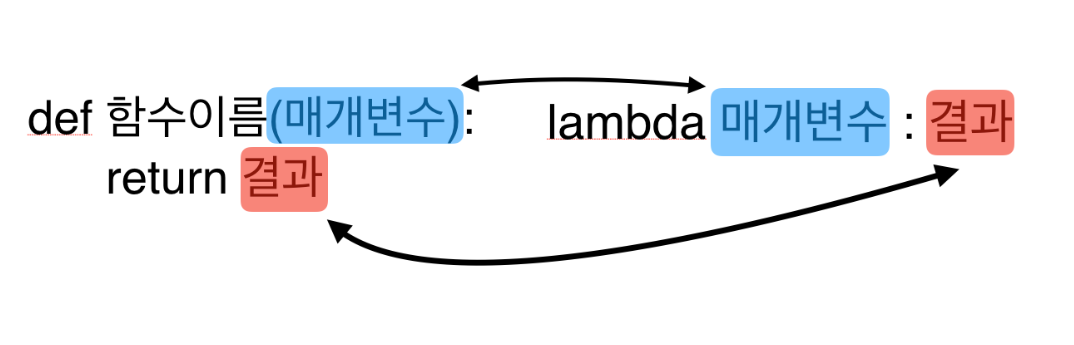
lambda함수: 익명함수(이름이 없는 함수)로, 일반적으로 함수를 한번만 사용하거나 함수를 인자로 전달해야 하는 경우에 매우 유용하게 사용된다.
-> lambda 인자 : 표현식
ex) add = lambda x,y: x+y
ex)(lambda x,y: x+y)(10,20) >>> 30
def키워드를 사용하여 함수를 정의하는 것보다 간결하고 간편한 방식으로 함수를 정의할 수 있다.
<데이터 전처리&시각화>강의:저번에 다 수강 못한것 이번에 수강 및 실습 진행
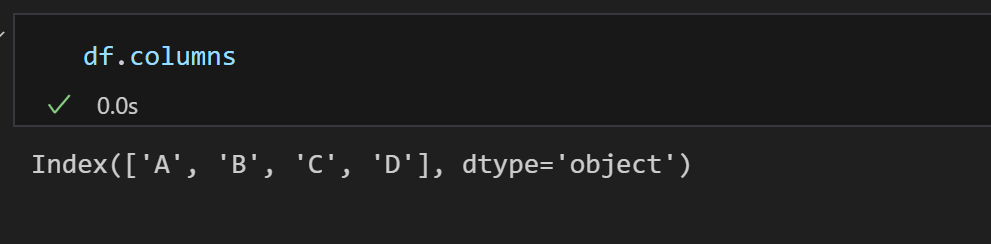
요기서 object는 '문자열' 을 의미한다.
아니 근데 이제서야 이걸하고있는 내가..ㅠㅠㅠ내일부터 프로젝트 시작인데,, 젠쟝,,으악 bloody hell이다정말로,


오늘은 그 강의를 듣기 전에 요 강의 선생님께서 pandas 링크보고 따라서 타이핑 해보고 오라고 해서 오후시간 내내(아티클 시간 제외) 이거 타이핑하면서 코드 익히고 이해하면서 시간을 보냈다. 확실히 계속 타이핑하면서 연습하니까 코드가 이해가 되면서 코드정리가 조금 되는 것 같다. 어젠가 튜터님 강의때도 그렇고 코드를 따라서 다 따라치는 것을 말씀하셔서 확실히 쳐봐야 느는 것 같다. 지금까지는 조금,, 그 이론중심으로 공부를 했던 것 같다..
오늘은 카페가서 공부를 했다. 정말 밀도있게 집중해서 공부를 했다. 역시 집을 벗어나야 하는것인가,,, 암튼 진짜 감사하다.
사실 오늘 계획한 것은 QCC4회차 2번문제 오답노트랑 이거 강의 다 듣는게 목표였지만,, 하루종일 판다스 코드 타이핑을 하여따,, 왜 이제서야 이걸 한 것일까,, 오늘이라도 해서 다행인가,,
아티클 전에 팀원들이랑 프로젝트 관련해서 이야기를 나눠봤다. 기법은 회귀, 주제는 이커머스나 고객분석 쪽 을 하기로 했다. 지금이 3번째 팀인데 처음으로 프로젝트 전에 이야기 해봐서 은근 좋았다.
고생했다.. 오늘 오전에 사실 진짜로,, 그,, 그때 이 수업을 드롭하고 그다음 기수로 넘어가지 않은 것을 엄청 후회하면서,, 프로젝트가 무슨 의미가 있을까 라고 생각했는데,, 시간 지나니까 또 멘탈이 괜찮아졌다.. 정말 쉽지않다.. 혼자서 북치고 장구치고 했지만,, 내일부터 시작되는 프로젝트도 화이팅이다!! 나자신에게: 고생했어. 잘하고 있어,, 야,, 기죽지말고,, 하자,, 화이팅이야
그리고 저녁에 약간 폭식할 뻔 했는데 참았다. 요즘에 특히 저녁에 폭식 또는 과식 절제하고 있다. 진짜 감사하고, 나도 절제할 수 있는 사람이라는 생각이, 성공경험이 쌓이고 있다. 아주 좋다 잘하구 있어!!ㅠㅠㅠ스트레스 받지말기!!
10 minutes to pandas: In[66]까지 했다. 여기서부터 다시 시작하기! (참고로 In[141]까지 있음.)
loc[]=>이름 기준으로 데이터 뽑아내는 것. .loc[행 이름(특정 행, 리스트 인덱스 가능), 열 이름]
iloc[]=>숫자 기준. ex).iloc[0,1]:첫번째 행,두번째 열에 있는 데이터
at[]을 쓰면 이름 기준으로 loc보다 더 빠르게 뽑아올 수 있다. 근데 한가지 데이터만 추출 가능. 빠르게 한 데이터만 확인할 때 사용하기 좋음. iloc도 빨리 뽑아올 수 있는 버전 있음.
<마지막 베이직 세션>
.copy-> 원본 데이터 훼손하지 않기 위해서 사용한다.
df.isnull()->결측치 확인, df.isnull().sum()->각 컬럼별로 결측값 몇 개 있는지 세줌.
패키지 설치할 때 pip install ~ 인데 나는 항상 터미널 열어서 했는데, 튜터님은 그냥 코드 작성하는 칸에서 바로 실행하셨다. 꼭 터미널에서 안해도 괜찮나보다..?(나중에 해봐야지)
fillna()->결측값 채우기
