오늘은 계속 팀 나눠서 대시보드 구상 및 태블로 시각화를 하였다.
✏️대시보드 구상 첫단계(전체 플랫폼용, 마케팅 용)
<전체 플랫폼>
대시보드 제목
kpi 지표: 수강생 수, 전체 강의 수, 수료율?
육하원칙
- 누가: 수강생들이
- 언제: 2012가을학기~2013봄학기
- 어디서: 인터넷강의 플랫폼 edx(?)
- 무엇을: 16개의 강의를
- 어떻게: 수료함/수료하지 x/수료증을 얻음/수료증을 얻지x/학점을 받음/학점을 받지x
- 왜: -
그렇다면 수강생들에 대한 지표를 표시해야될 것 같음->이게 데모그래픽스:
성별은,,, 포함시켜도 괜춘할 듯, 나이는 들어가야될 듯, 국적도 포함하면 괜찮을 듯,
학력,,,,,도 꼭 들어가야될...까 싶음.
강의에 대한 자료들도 표시->
수료에 대한 지표도 표시하기: 근데 이것을 수료에 대한 지표로 표시해야할지 아니면 grade를 기준으로
점수를 1점 이상으로 기준을 세워서 점수 받은 사람, 못받은사람(결측치랑 0점 포함) 해서 비율을 계산해야할지
고민.
참가율을 viewed로 봄
강의 관련 주제를 몇 개 정리해서 보여주는 것도 괜찮을 듯-> 이것 해볼까
: 범주화 해서 어떤 주제들이 있고 그것을 듣는 비율이런 것 조사
보는 사람: 강의 플랫폼 관계자들(전사 대상)
<마케팅 용>
마케팅: 유입하는게 목적
마케팅팀 대시보드
수료자-성공적인 수료자의 길 이런식으로 =?
강의 top5/ bottom5
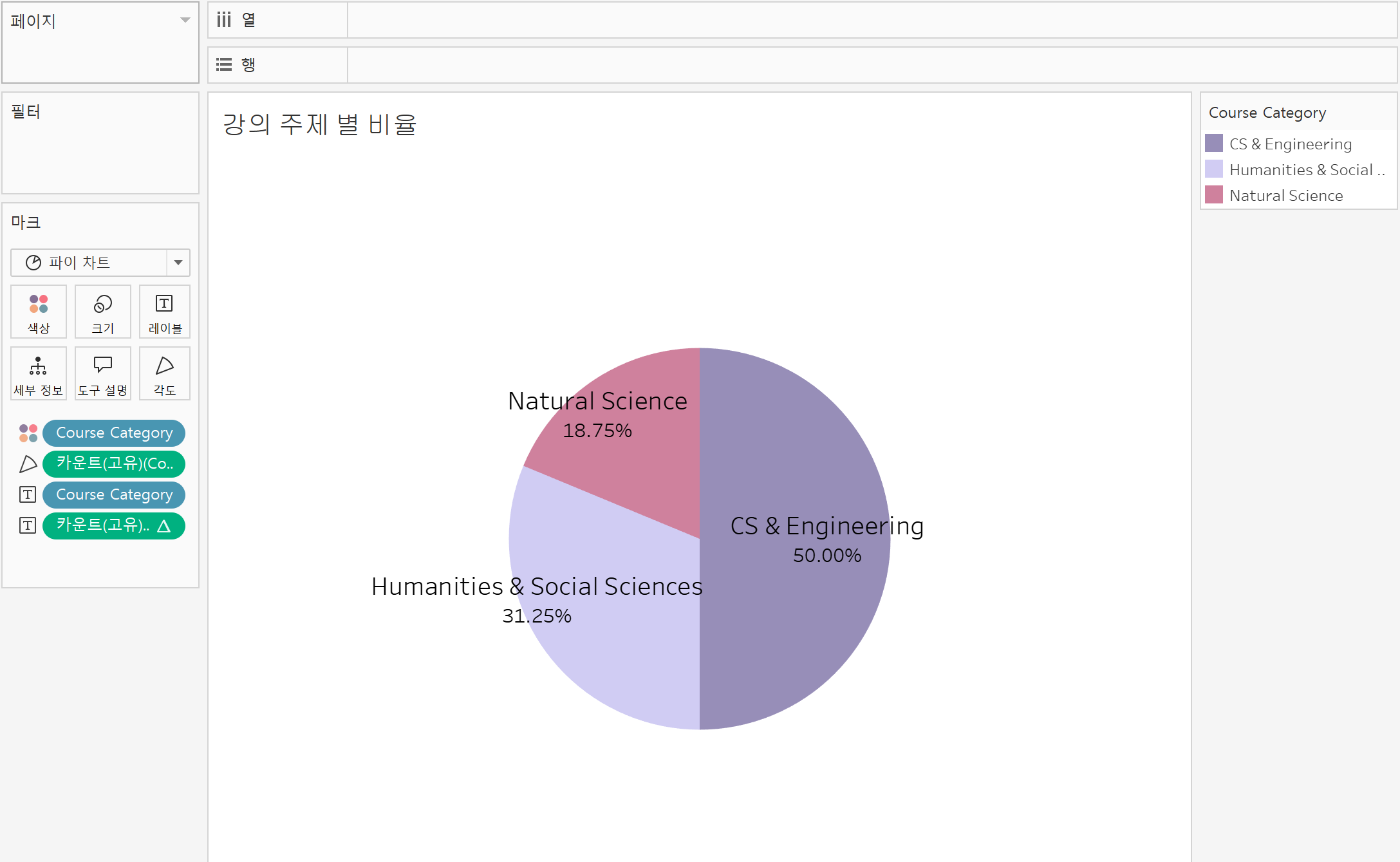
강의별 주제를 범주화 시키기-> cs/ not cs(다른 주제는 너무 많아서 범주화시키기 어려움.)
하버드/MIT
성별/연령대
nevents
학생이 수강하는 동안 수업에 참여한 action 수 (Integer)
ndays_act
학생이 수업에 참여한 일수 (Integer)
nchapters
학생이 수강하는 동안 action을 한 챕터의 수 (Integer)
nforum_posts
학생이 수업의 forum에 글을 남긴 횟수 (Integer)
나는 여기서 nforum_posts를 봤다.
# 히스토그램 그리기
df['nforum_posts'].hist(bins=range(0, 8), edgecolor='black', align='left')
plt.xlabel('Number of Forum Posts')
plt.ylabel('Count')
plt.title('Distribution of Forum Posts')
plt.xticks(range(0, 7)) # x축 눈금을 0~6으로 설정
plt.show()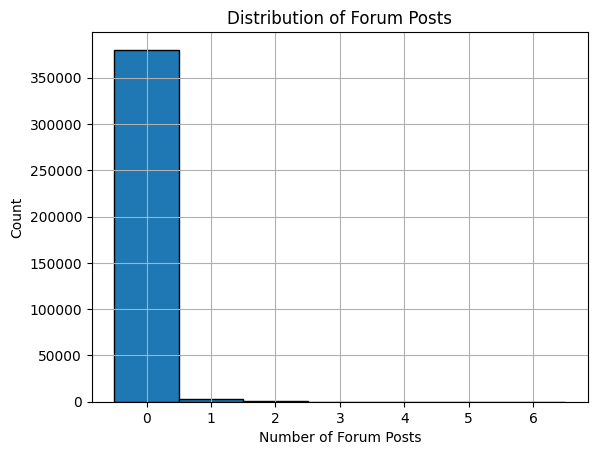
근데 진짜 어떤 지표를 보던 0이 너무 많음.. 그 뒤에는 아예 안보여서 아예 0을 빼고 보았다.
# 0을 제외한 데이터만 선택
filtered = df[df['nforum_posts'] != 0]
# 히스토그램 그리기
filtered['nforum_posts'].hist(bins=range(1, 8), edgecolor='black', align='left')
plt.xlabel('Number of Forum Posts (excluding 0)')
plt.ylabel('Count')
plt.title('Distribution of Forum Posts (0 excluded)')
plt.xticks(range(1, 7)) # x축 눈금을 1~6으로 설정
plt.show()
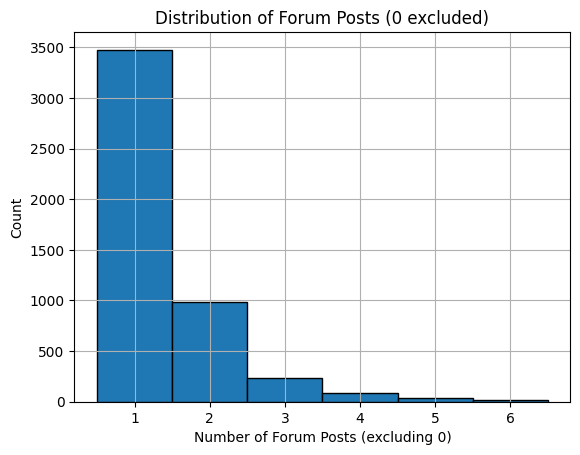
# 0,1 을 제외한 데이터만 선택
filtered = df[~df['nforum_posts'].isin([0, 1])]
# 히스토그램 그리기
filtered['nforum_posts'].hist(bins=range(1, 8), edgecolor='black', align='left')
plt.xlabel('Number of Forum Posts (excluding 0,1)')
plt.ylabel('Count')
plt.title('Distribution of Forum Posts (0,1 excluded)')
plt.xticks(range(2, 7)) # x축 눈금을 2~6으로 설정
plt.show()
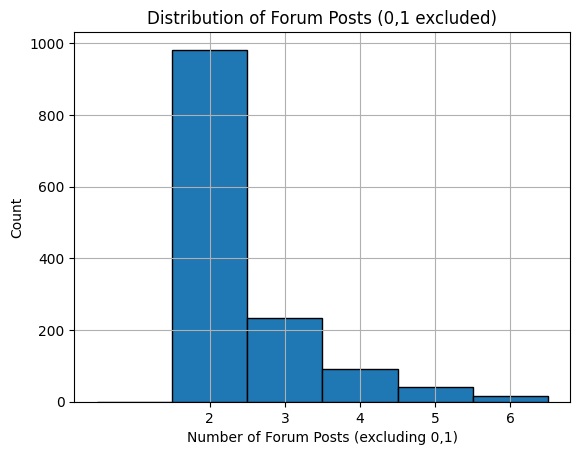
import seaborn as sns
# 상관관계 계산
corr = df.corr(numeric_only=True)
# 히트맵 시각화
plt.figure(figsize=(10, 8))
sns.heatmap(corr, annot=True, cmap='coolwarm', fmt=".2f", linewidths=0.5)
plt.title("Correlation Matrix")
plt.show()
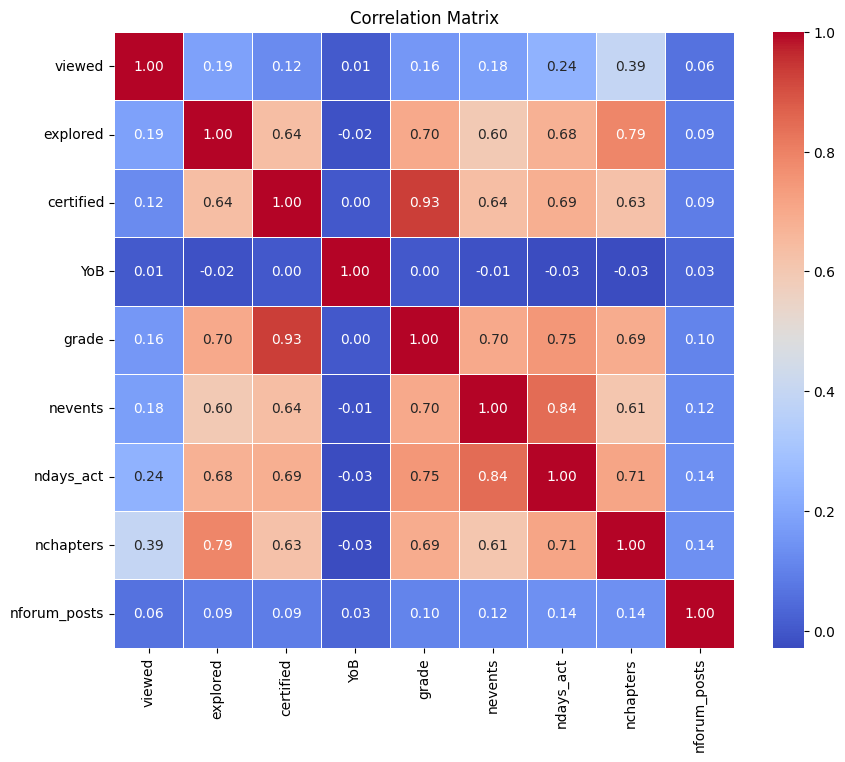
아쉬운게 마케팅팀은 보니까 시계열 데이터별로 분석을 하거나 매출관련된 데이터들을 다루는것들이 많았다. 하지만 이번 교육 데이터셋에는 이런것들을 알 수 있는 데이터가 없었다. 그리고 이 강의 자체가 돈내고 듣는 사람들이 소수이기도 하고, 무료로 그리고 여러가지의 목적으로 듣는 사람들이 많아서 마케팅을 하기가 쉽지가 않았다.
📊시각화
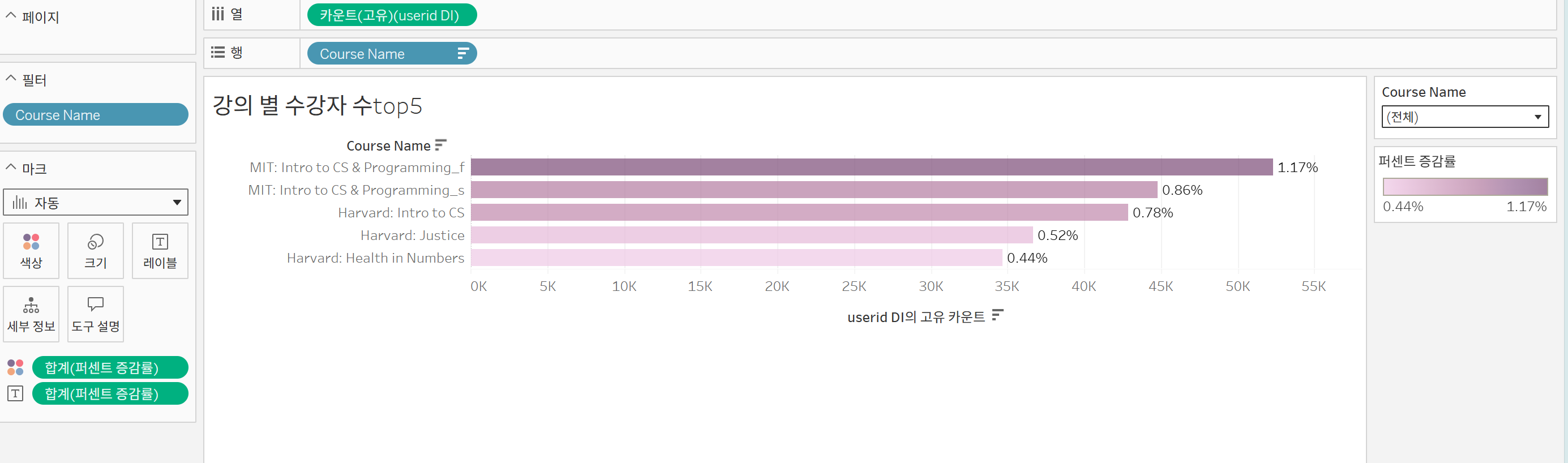
이거 탑5랑 바텀5다 구했는데 저 퍼센테이지 구하는 계산식 만드는게 좀 힘들었다...
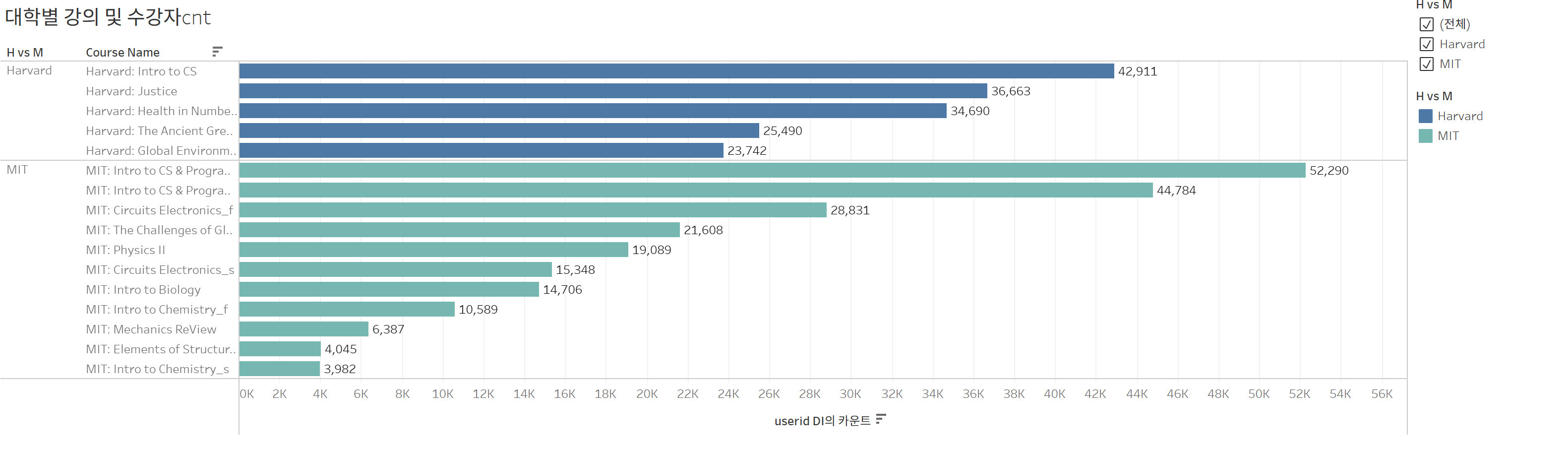
다는 못올리고 요정도. 강의명별로 범주화하는 코드
# 범주화 함수 정의
def categorize(course):
course = course.lower() # 대소문자 무시
if 'cs' in course or 'circuits' in course or 'structures' in course:
return 'CS & Engineering'
elif 'biology' in course or 'chemistry' in course or 'physics' in course or 'mechanics' in course:
return 'Natural Science'
else:
return 'Humanities & Social Sciences'
# 새 컬럼 'course_category'에 저장
df['course_category'] = df['course name'].apply(categorize)
✔️태블로
태블로에서 항상 고민이었던 부분이: 시각화를 해야하는데, 많은 케이스로 열과 행에 오는 컬럼?이 둘 다 범주형이었다. 그래서 시각화를 항상 측정값으로 바꿔서 했었는데 이부분을 도대체 어떻게 해야할지 고민이 되어서 튜터님께 가서 여쭤보았다.->범주형은 어쨌든 범주이기 때문에 count로 바꿔도 된다. 오늘 내가 했던 파이차트 를 예시로 들어보자면 하나를 count로 바꿔서 계산하였음. 그리고 그 비율을 보고 싶었는데 그거는 완전 꿀팁인게->퀵계산차트?인가 그거 누르면 되는 거였음.
+그리고 그 zep에서 화면공유를 태블로 화면으로 해버리면 그 오른쪽커서 눌렀을 때 나오는 그 메뉴들이 안보여서 무조건 전체화면 공유로 해야함. 오늘 그것땜에 시간 좀 많이 끌었다.
내일은 대시보드 프레임 완전히 아 단어가 기억이 안난다.. 암튼 완전히 정하고 본격적으로 시각화 배치하고 디벨롭 할 예정, 주제별 강의수강생 수 파이차트 만들기
