머신러닝에서의 편향과 분산
원래 내가 알고 있던 의미

하지만 머신러닝에서의 의미


✅ 한 줄 정리
“분산이 크다”는 건 모델이 너무 민감해서 예측이 불안정하다는 뜻,
“편향이 크다”는 건 모델이 정답에서 일관되게 멀리 벗어난다는 뜻.
다운캐스트
이거 오늘 프로젝트하면서 알게된건데, 메모리랑 속도때문에 그 타입 숫자를 낮추는게 있다.
원래는 데이터타입이 int64, float64이렇게 되는데 이거를 이런식으로 바꿔준다.
# 정수형 컬럼 다운캐스트
df_reviews['Unnamed: 0'] = df_reviews['Unnamed: 0'].astype('int32')
df_reviews['rating'] = df_reviews['rating'].astype('int8')
df_reviews['total_feedback_count'] = df_reviews['total_feedback_count'].astype('int16')
df_reviews['total_neg_feedback_count'] = df_reviews['total_neg_feedback_count'].astype('int16')
df_reviews['total_pos_feedback_count'] = df_reviews['total_pos_feedback_count'].astype('int16')프로젝트
오늘은 다같이 전처리 진행하고, 그 후에 각자 EDA해보았다.
처음 이디에이 하기 전에 일단 목표를 세우고 이디에이를 해보았다.
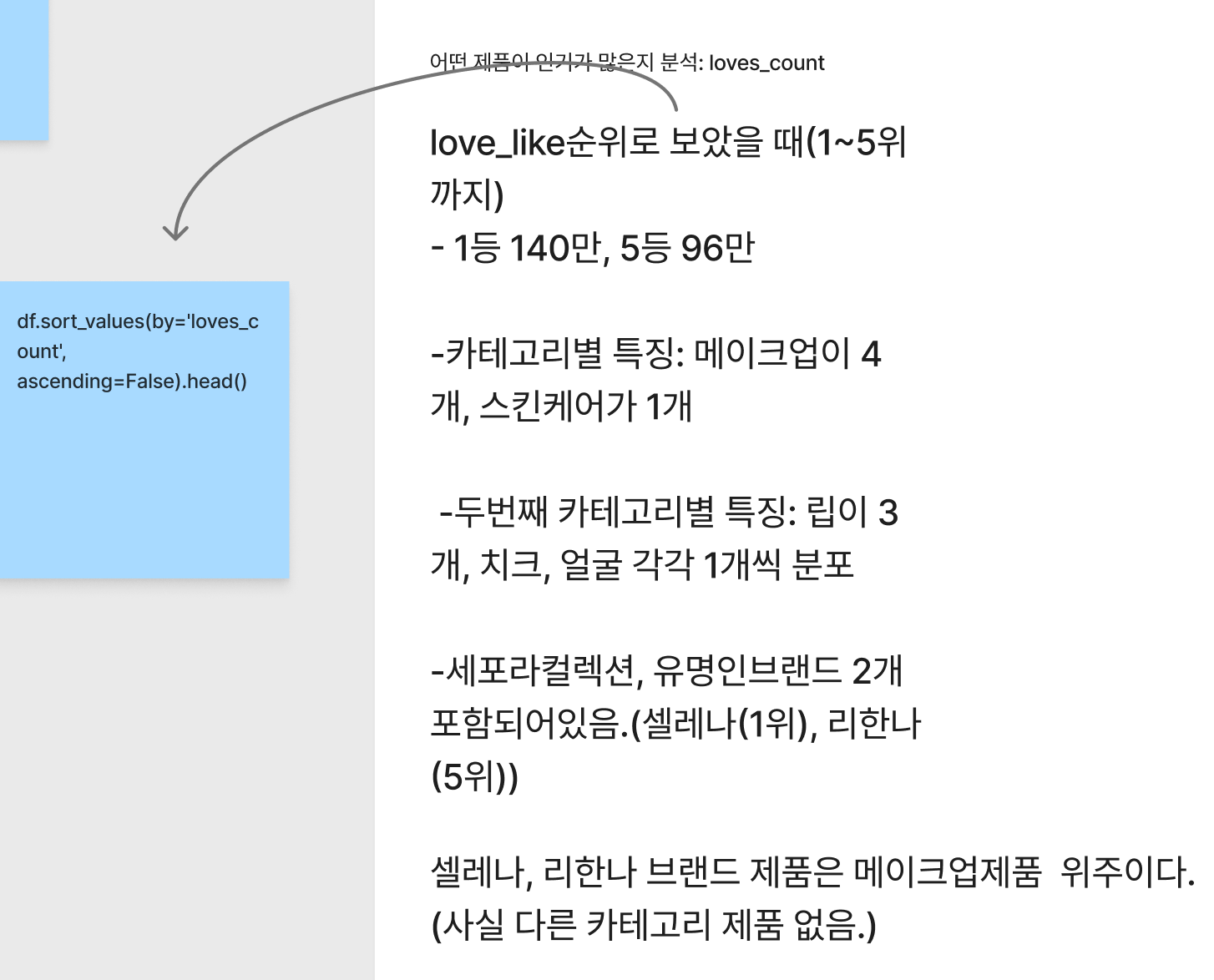
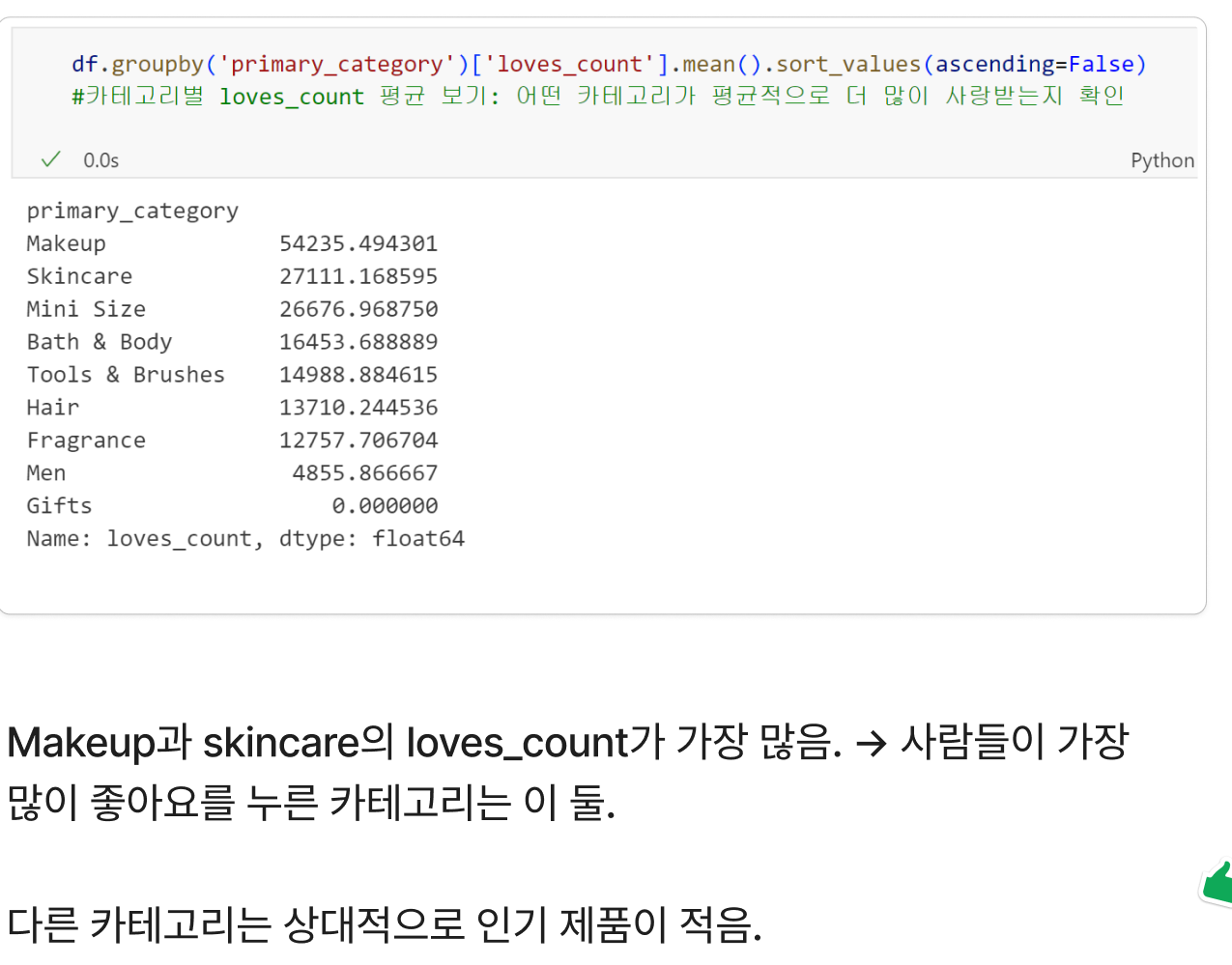
목표: 어떤 제품이 인기가 많은지 분석: loves_count를 중심으로 해보았다.



청지기