진짜 오랜만에 sql
https://school.programmers.co.kr/learn/courses/30/lessons/151138
요 문제에서 나의 첫번째 쿼리
-- 평균대요 기간이 7일 이상인 자동차만 출력
-- 평균 대여기간 컬럼 생성
SELECT car_id, round(avg(end_date - start_date +1), 1) as average_duration
from car_rental_company_rental_history
group by car_id
having average_duration >= 7
order by average_duration desc, car_id desc틀림. 답을 보면서 이게 맞아..? 싶음
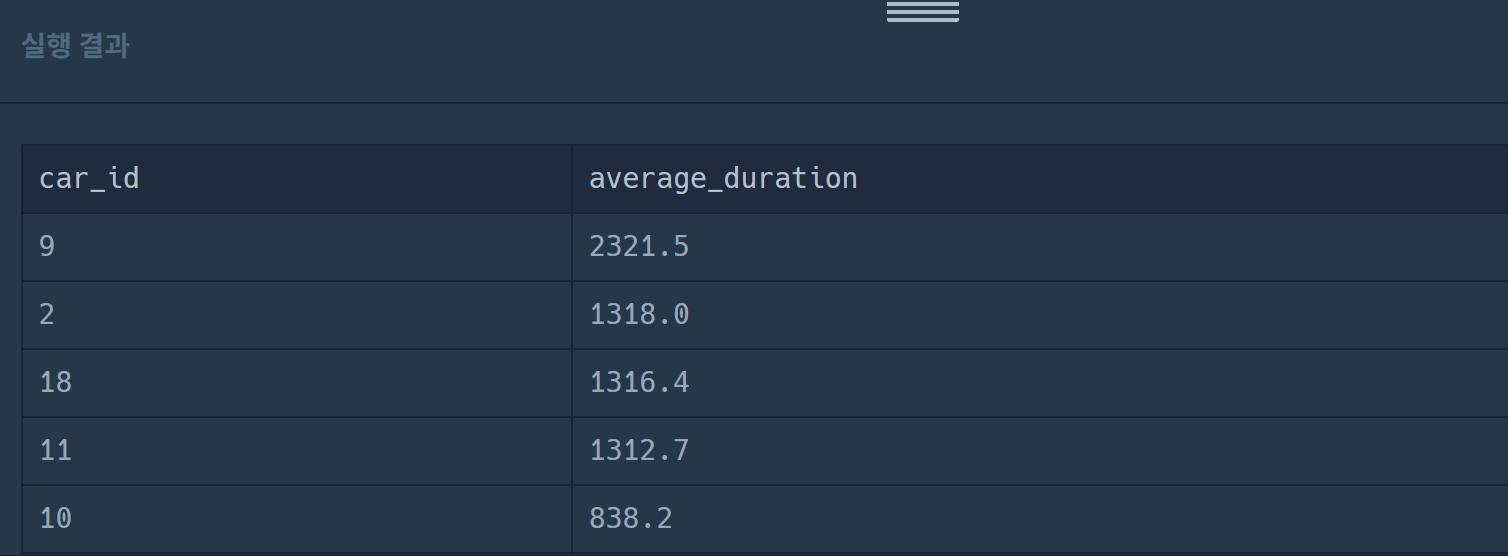
평균 빌린 기간이 저렇게 되기가 쉽지 않기 때문에,, 도대체 뭐가 잘못된거지 싶음..
흠...
datediff함수
mysql환경이랑 sqlserver환경이랑 다름. 구글링해서 찾아봤는데 그 블로그가 sql서버식으로 알려줬는데 계속 에러가 나서 지피티한테 물어봄.
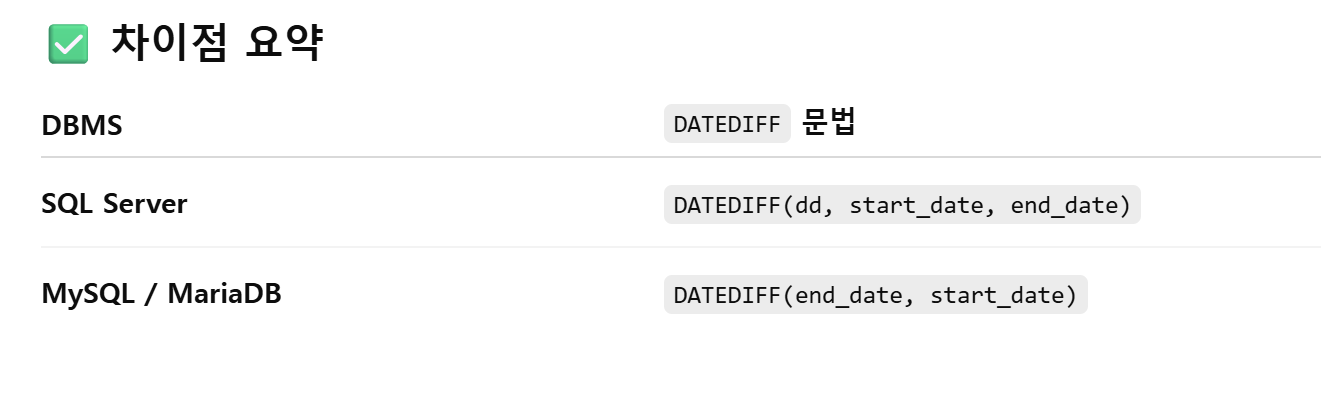
내가 쓰고있는 환경은 mysql임 .그래서 쓸 때 저절로 end_date를 먼저 앞으로 오게함
그 코드카타 보면 밑에 질문하기 가 있음. 거기를 눌러서 제목만 봤는데 어떤 사람이 datediff함수를 써놨길래, datediff함수를 써서 풀어봄.
-- 평균대요 기간이 7일 이상인 자동차만 출력
-- 평균 대여기간 컬럼 생성
SELECT car_id, round(avg(datediff(end_date, start_date)+1.0) , 1) as average_duration
from car_rental_company_rental_history
group by car_id
having average_duration >= 7
order by average_duration desc, car_id desc이렇게 푸니까 맞음. 정답도 괜찮게 나옴.
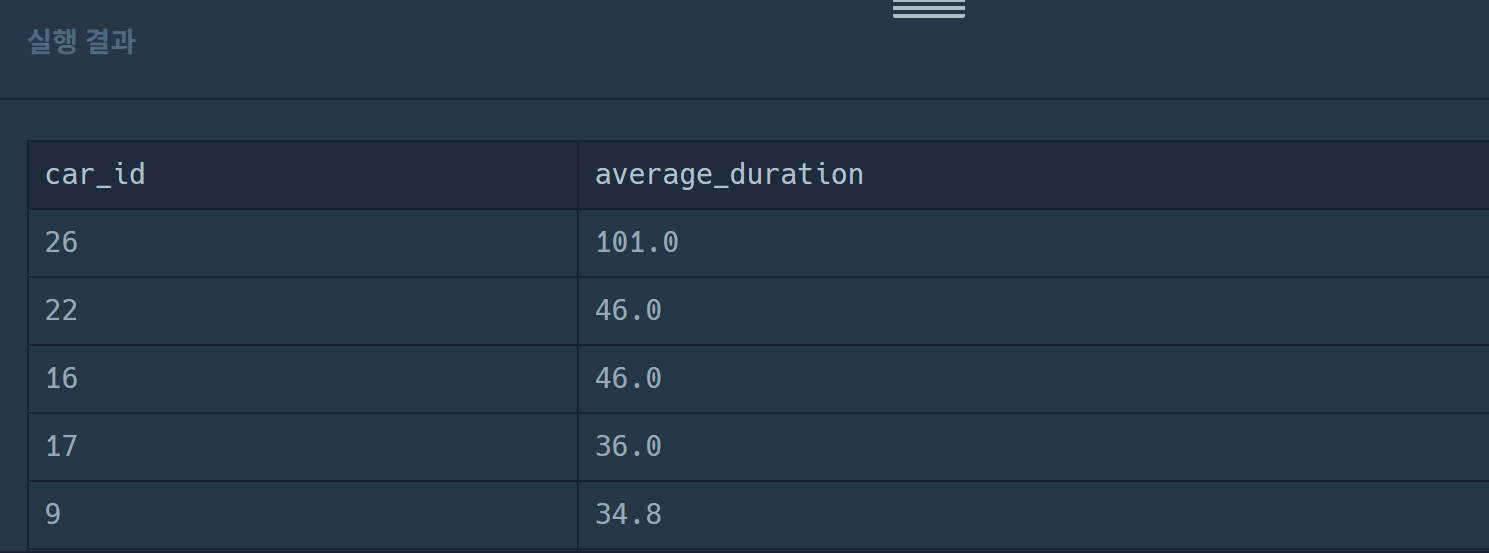
왜 처음 방식으로 풀면 틀리는거지...? 날짜 차이 계산할때는 꼭 datediff를 쓰기로 합시다.
지피티에게 물어보니,

그렇다고 한다.
앞으로 날짜 계산할 때는 datediff함수 꼭 사용하기!! 습관 들이기!!
두번째 문제 : https://school.programmers.co.kr/learn/courses/30/lessons/77487#qna
내 첫번째 쿼리
-- 공간을 둘 이상 등록한 사람이 헤비 유저
-- 아이디 순으로 정렬
SELECT host_id, count(id) from places
group by host_id
having count(id) >= 2
order by count(id) desc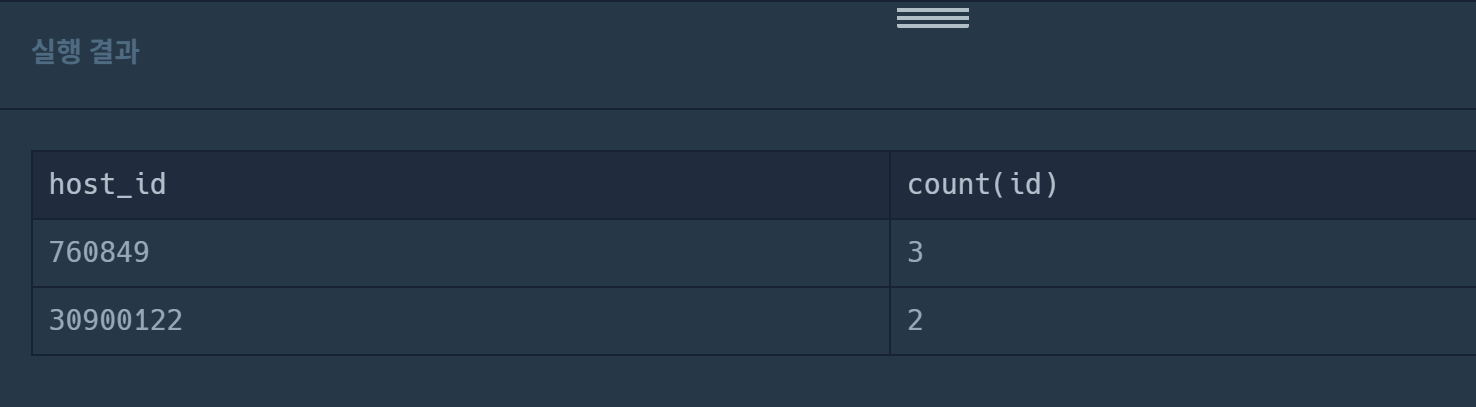
헤비유저의 아이디는 알겠는데 이걸 어케 풀어야 할지 모르겠음
질문하기를 봄
정답 쿼리
-- 공간을 둘 이상 등록한 사람이 헤비 유저
-- 아이디 순으로 정렬
select *
from places
where host_id in (
SELECT host_id from places
group by host_id
having count(id) >= 2
)
order by id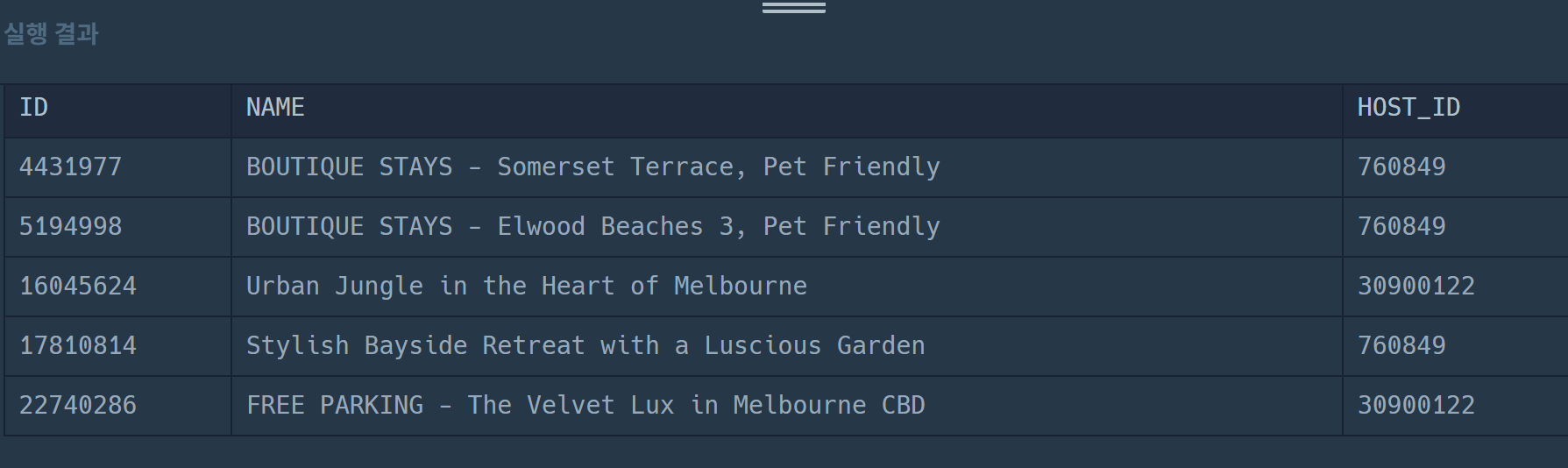
오랜만에 서브쿼리를 쓴다. 조건절에 저렇게 주어서 뽑아내는 방식.
- 💡having절은 굳이 select에 집계함수 쓰지 않아도 거기서 자체로 집계함수 사용이 가능
- 💡group by도 마찬가지로 select절에 굳이 집계함수 쓰지 않아도 group by가 가능함. 출력문제임.
in함수
in함수는 in뒤에 오는 값들 중 해당하는 값이 있으면 모두 가져오는 함수이다. =는 한개만 충족이 가능한데 in함수를 쓰게 되면 여러가지 값에 해당하는 것을 가져올 수 있다.
세번째 문제:https://school.programmers.co.kr/learn/courses/30/lessons/62284#qna
정답쿼리
-- 우유와 요거트를 동시에 구입한 장바구니의 아이디(cart_id)
-- 장바구니의 아이디 순으로 정렬
SELECT cart_id from cart_products
where name in ('milk', 'yogurt')
group by cart_id
having count(distinct name) = 2🧱문제의 blocker: in까지는 해냈는데, 거기서 어떻게 골라내야할지가 모호했다. 골라낸 후 그룹바이 해서 해빙으로 카운트 디스팅트 네임까지는 생각해내지 못함.. 도대체 이걸 생각해내려면 어떻게 해야하는거지...?
네번째 문제: https://school.programmers.co.kr/learn/courses/30/lessons/164671#qna
나의 쿼리
-- board_id가 공동키임.
select concat('/home/grep/src/', a.board_id,'/', a.file_id,a.file_name,a.file_ext) as file_path
from (
SELECT b.board_id, f.file_id, f.file_name, f.file_ext
from used_goods_board b inner join used_goods_file f on b.board_id = f.board_id
order by b.views desc
limit 2
) a
order by a.file_id desc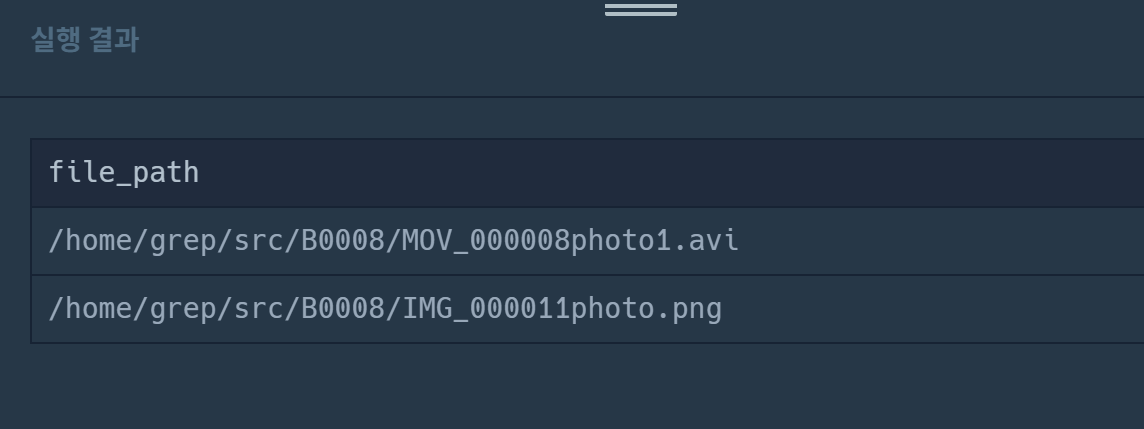
실행결과 잘 나왔다고 생각했는데 채점했더니 틀렸댄다... 도대체 왜죠...?
🧱문제의 blocker:그리고 저 쿼리에서 계속 실수했던 것: from절에 서브쿼리 만들 때 별칭 해주는거랑, 바깥 쿼리에서 select절에 컬럼 가져올 때, a.으로 표시해야하는 점. 안에서 b.또는 f.으로 가져왔는데, 어쨌든 그거를 하나의 테이블로 만들었으니까 밖에서 가져올 때는 a.로 표시해야한다.
다른사람들의 작성 쿼리를 보고 다시 작성해본 정답 쿼리
select concat('/home/grep/src/', b.board_id,'/', f.file_id, f.file_name, f.file_ext) as file_path
from used_goods_board b inner join used_goods_file f on b.board_id=f.board_id
where b.views = (select max(views) from used_goods_board)
order by f.file_id desc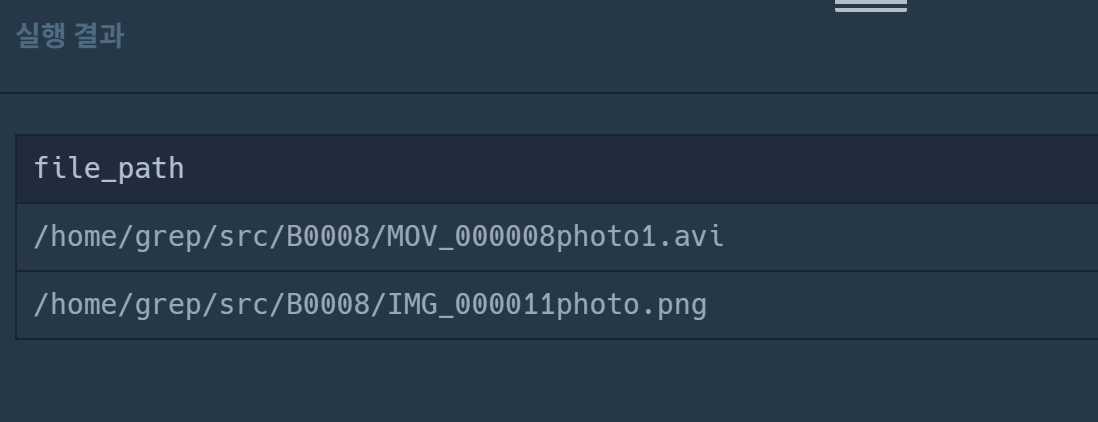
아니 내가 작성한 정답쿼리랑 똑같은데 이 쿼리는 채점해보니 정답이다. 뭐죵...?⁉️🤨
지피티는 이게 정렬 기준이 서브쿼리 내에서 적용되어서 올바른 파일 정렬이 되지 않을 수도 있다고 함. 더 정확하고 직관적인 방식으로 아예 where절로 가장 조회수 높은 게시글을 필터링한 뒤 그 게시글에 속한 파일들을 정렬하는게 좋다고 함.
암튼 이문제에서 기억할 것은: 가장 높은 조회수 필터링 할 때 max를 떠올릴 것!!
