Review: Learning to Perform Local Rewriting for Combinatorial Optimization (NeurIPS, 2019)

입사하고 더 바빠졌습니다~
한편, 연구실에서는 transformer와 RL을 활용해서 TSP 문제를 해결하는 것에 관심이 많은데요. 그중에서 combinatorial optimization 문제에 범용적으로 적용가능한 framework인 "Learning to Perform Local Rewriting for Combinatorial Optimization"에 관련된 내용을 리뷰하도록하겠습니다. 내용 구성은 논문에서 필요한 강화학습으로 시작해 논문에서 제시한 NeuRewriter를 학습하고 추론하는 방법, 그리고 실험결과에 대해서 살펴보겠습니다.
0. 강화학습 배경지식
a. Actor-Only, Critic-Only, Actor-Critic
Actor-Only, Critic-Only, Actor-Critic는 강화학습을 분류하는 큰 기준 중 하나입니다.
Actor-Only RL는 policy(π)를 직접적으로 향상시켜 더 나은 행동을 선택하도록 합니다. unbias estimator로 학습하기 때문에 high variance gradient를 가지는 것이 특징입니다.(bias-variance tradeoff) 또, Episode가 완전히 끝날때까지 기다려야(no bootstrapping) 학습을 진행할 수 있습니다.
Critic-Only RL은 value function(v, Q)을 학습하는 데 초점 두고 있습니다. 정책을 직접적으로 나태내는 function은 없지만 어떤 상태가 얼마나 좋은지에 대한 정보를 얻을 수 있습니다. 이들을 학습할때는 bias estimator를 활용하기 때문에 low variance gradient를 가지는 것이 특징입니다. 이들은 부트스트래핑이 가능하기 때문에 real-time update(train)을 할 수 있습니다. 정책 최적화를 위해서는 별도의 알고리즘이 필요합니다.
Actor-Critic RL은 Actor와 Critic를 결합한 방법으로 이들의 장점을 모두 취할 수 있습니다. Actor는 policy을 개선하고, Critic는 value function를 평가합니다. 설계 구현이 상대적으로 복잡하지만, Actor가 Critic의 피드백을 통해 빠르게 학습하고, Critic는 Actor를 안정적으로 평가하여 학습 안정성을 높일 수 있습니다.
b. Deep Q-Network(DQN)
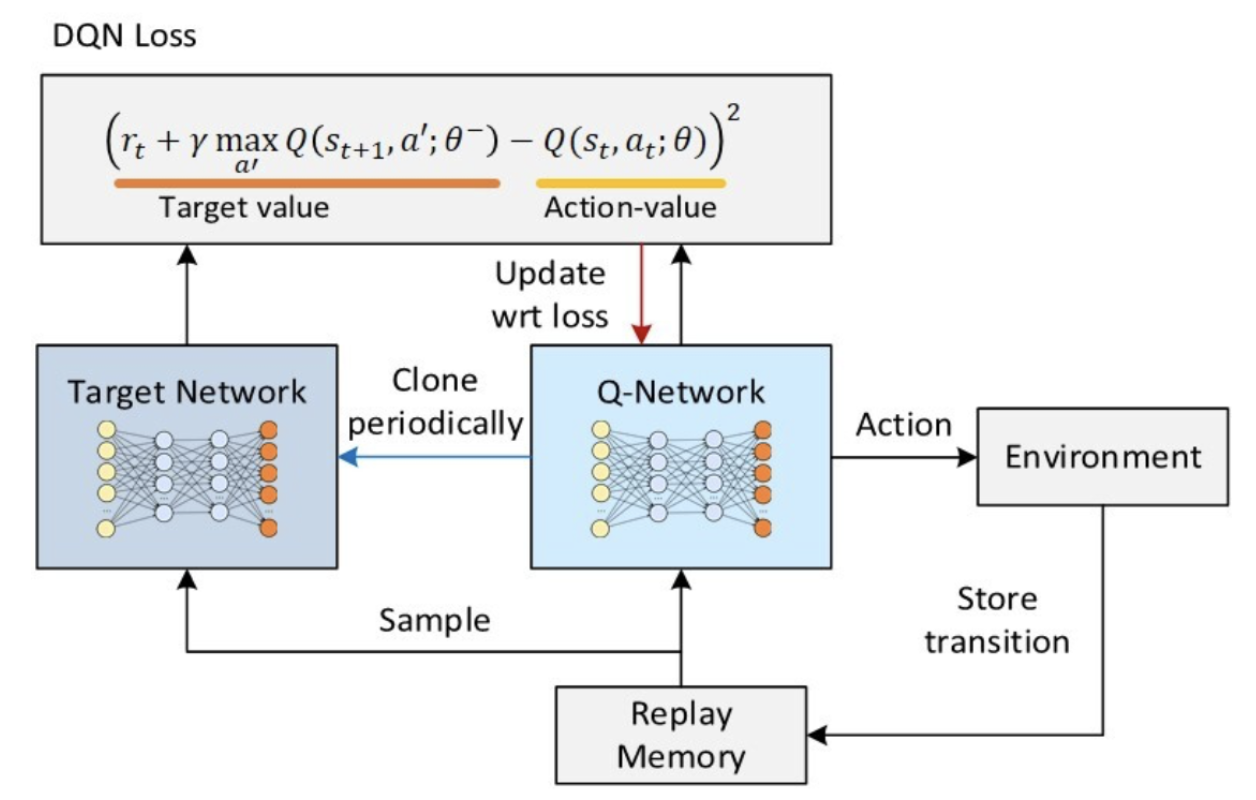
출처: https://ai-com.tistory.com/entry/RL-강화학습-알고리즘-1-DQN-Deep-Q-Network
DQN은 Deep Neural Network를 사용하여 Q-function을 근사화하는 방식으로 작동합니다. DQN은 Bellman 최적 방정식을 사용하여 Q-값을 업데이트합니다. 이 방정식은 현재 상태와 행동의 Q-값을 최적으로 업데이트하는데 사용됩니다. DQN은 online network, target network 두 개의 네트워크를 사용합니다. target network는 online network의 파라미터를 일정한 주기로 업데이트합니다. 이것은 학습 중에 target network의 Q-값을 안정적으로 추적하는 데 도움이 됩니다. 이들은 Experience Replay을 사용하여 학습 데이터를 관리합니다. 에이전트는 상태, 행동, 보상, 다음 상태 등의 정보를 저장하고, 이 경험을 무작위로 추출하여 네트워크를 학습합니다. 이렇게 함으로써 데이터의 독립성을 보장할 수도 있습니다.
c. Advantage Actor-Critic (A2C)
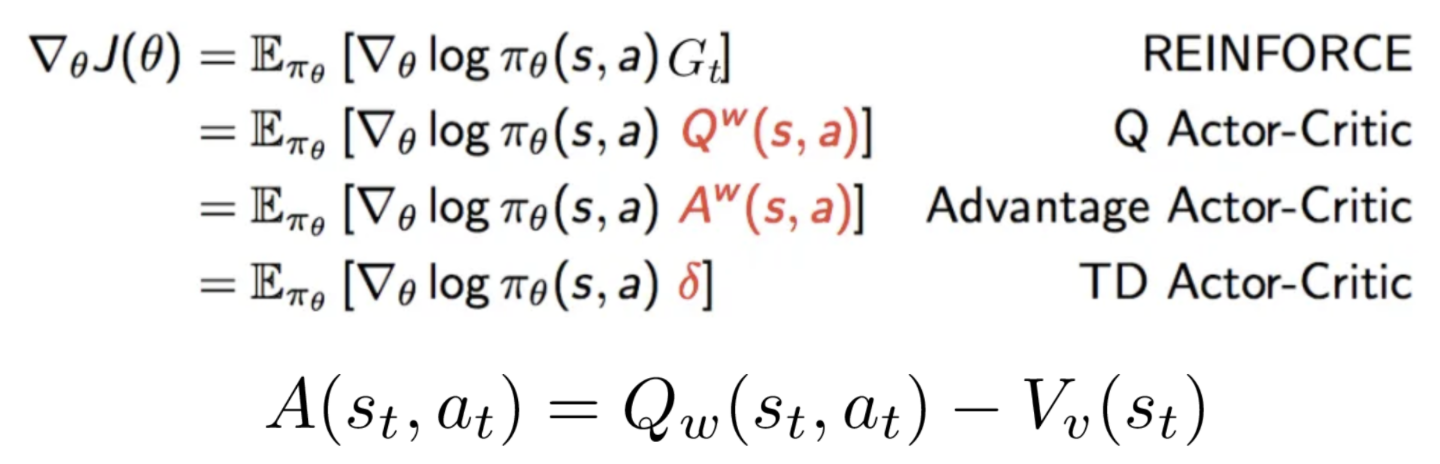
출처:https://medium.com/@thechrisyoon/deriving-policy-gradients-and-implementing-reinforce-f887949bd63
Advantage Actor-Critic는 강화 학습 알고리즘 중 하나로, Policy Gradient Methods와 Value Estimation을 결합한 방식입니다. 이 알고리즘은 정책(Actor)과 가치 평가(Critic)를 번갈아가며 업데이트 합니다.
Actor (정책 업데이트): Actor는 policy(π)을 관리하고 업데이트합니다. 정책은 에이전트의 행동을 결정하는데도 활용합니다. Actor는 환경과 상호작용하여 얻은 경험을 토대로 정책을 업데이트하고, 이를 통해 높은 보상을 얻도록 노력합니다. 업데이트 방향은 Critic의 추천에 따라 이루어집니다.
Critic (가치 평가 업데이트): Critic은 에이전트의 행동에 따른 상태 가치 함수나 Q-값 함수를 추정합니다. Critic은 에이전트의 정책 업데이트를 조언하는데 사용되며, 보상을 얼마나 잘 예측하고 평가하는지에 따라서 학습이 진행됩니다.
A2C에서 "Advantage"는 에이전트가 특정 상태에서 어떤 행동을 취하는 것이 얼마나 좋은지를 나타내는 값입니다. 이것은 현재 행동의 가치(Q-값)와 상태 가치(V-값)의 차이로 계산됩니다. A2C는 안정적으로 학습(lower variance)할 수 있고 메모리 요구량(experience replay에 비해)이 낮다는 장점이 있습니다.
1. NeuRewriter = region-picking + rule-picking
Continuous solution spaces는 주로 gradient descent을 활용해서 반복적인 개선을 진행하지만, C.O.와 같은 Discrete solution spaces에서 해결하기 위한 방법론이 없는 점을 착안해 NeuRewriter 가 고안되었습니다. NeuRewriter는 반복적으로 local part를 선별하고 재작성(rewriting)하며 수렴전까지 개선을 반복합니다. 이들은 end-to-end network이며 region-picking policy, rule-picking policy 두개의 정책을 활용합니다. 이들은 아래 3개의 도메인에서 outperformance를 보입니다.
(1) key domains expression simplification(Z3)
(2) online job scheduling (DeepRM, Google OR-tools)
(3) vehicle routing problems (Google OR-tools)
괄호 안의 프레임워크는 해당 도메인을 해결하기 위한 표준적인 툴입니다. 본 논문에서는 이들에 대한 outperformance를 증명했습니다.
NeuRewriter를 활용하기 위한 조건은 아래와 같습니다.
(1) feasible solution을 쉽게 찾을 수 있다. (초기값 설정)
(2) search space가 단계적으로 solution을 개선시킬 수 있는 local structures를 가지고 있음(rewriting 용이)
2. Problem Setup
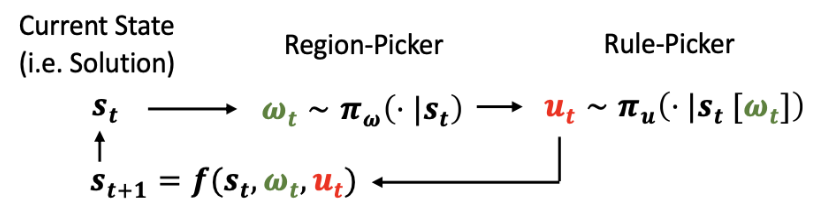
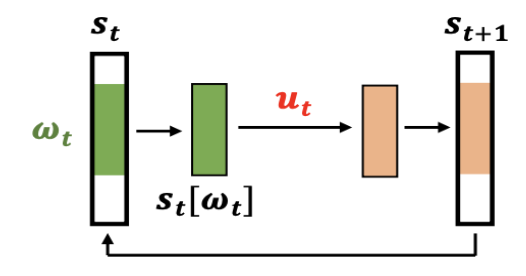
state과 action을 아래와 같이 notation, formulation을 정의합니다.
state s[t]: solution
action (ω[t], u[t]): local region ω[t] + rewriting rule u[t]
초기 상태 s[0]이 주어진 경우, 최종 비용 c(s[T])가 최소화되도록 (s[0], (ω[0], u[0])), (s[1], (ω[1], u[1])), ..., (s[T−1], (ω[T−1], u[T−1])), s[T]와 같은 다시 쓰기 sequence를 찾는 것이 목표입니다.
다음과 같은 iteration 과정을 거치며 solution이 계선됩니다.
(1) region-picking rule π[ ω[t] | S[t] ]을 활용하여 region ω[t]를 선택합니다.
(2) rewriting rule u[t]은 아래와 같이 구할 수 있습니다.
- 선택 정책 π[ u[t] | St ]를 활용하여 영역 ω[t]에 적용 가능한 규칙(u[t])으로 선택합니다.
- St는 s[t]의 부분 집합.
(3) u[t]를 St에 적용하고 다음 상태 s[t+1] = f(s[t], ω[t], u[t])를 얻음.
3. Model Overview - Neural Rewriter
Score predictor
- 모든 ω[t] ∈ Ω(s[t])에 대해 스코어 Q(s[t],ω[t])를 계산합니다.
- st를 재작성할때의 이점을 측정합니다.
- 높은 스코어일 수록 st을 재작성하는 것이 바람직합니다.
- 영역 집합 Ω(s[t])은 각 도메인 별로 다릅니다.
- Expression simplification => 표현 파싱 트리의 모든 하위 트리
- Job scheduling => 일정 잡기를 위한 모든 작업 노드 포함
- Vehicle routing => 경로의 모든 노드
Rule selector
- 규칙 선택 정책은 st에 대한 전체 규칙 집합 U에 대한 확률 분포 π(st)를 예측하고, 이에 따라 적용할 규칙 u[t] ∈ U를 선택합니다.
- 규칙 집합 U
- Expression simplification => 수동 설계 (유효성에 영향을 주지 않음)
- Job scheduling => 두 개의 노드 변경
- Vehicle routing => 두 개의 노드 변경
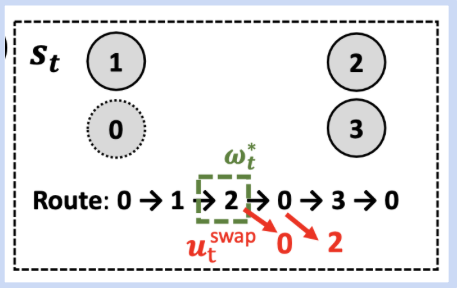
4. Training Details

에피소드는 일련의 단계를 나타내며, 각 단계에서 상태 s[t]가 주어집니다. 그 상태에서 취해질 행동 u[t]를 선택하고, 그에 대한 보상 r(s[t], (ω[t], u[t]))가 정의됩니다. 보상은 작업에 따라 비용 함수 c(s[t])와 다음 상태 c(s[t+1]) 간의 차이로 정의됩니다.
전체 손실 함수 L은 두 부분으로 구성됩니다. 하나는 규칙 선택 정책을 개선하기 위한 Lu이고, 다른 하나는 영역 선택 정책을 개선하기 위한 Lω입니다. 영역 선택 정책 π_ω는 현재 상태 s[t]에 대한 최적의 영역 ω[t]을 선택하는 데 사용됩니다. 규칙 선택 정책 π_u는 현재 상태 s[t]와 선택된 영역 ω[t]에 대해 최적의 규칙 u[t]를 선택하는 데 사용됩니다. 이 모든 것은 어드밴티지 A2C 알고리즘의 일부로 작동합니다.

에피소드 생성과정은 다음과 같습니다:
- 영역 선택 (Region-picking): Score가 특정 임계값 (엡실론) 미만인 경우, 다시 샘플링합니다.
- 규칙 선택 (Rule-picking policy): 현재 규칙 u[t]가 st를 대체할 수 있는지 확인한 후, 적합한 규칙을 선택하여 s[t+1]을 업데이트합니다.
5. Application Details - Vehicle Routing Problem
노드 임베딩: 각 노드를 7차원 벡터 ej로 변환합니다.
- 처음 3차원은 xj, yj 및 δj/Cap입니다. (δj는 자원 요구량)
- 다음 3차원은 이전 단계에서 방문한 노드의 좌표 및 vj와 이전 노드 간의 유클리드 거리입니다.
- 마지막 차원은 현재 단계에서 차량이 운반하는 남은 자원 양이며, 차량 용량으로 정규화되어 있습니다.
스코어 예측 모델: 각 노드를 인코딩하기 위해 양방향 LSTM을 사용했습니다.
규칙 선택자: vj -> vj′ vj′를 선택하기 위해 유사한 디자인을 가진 포인터 네트워크와 유사한 구조의 어텐션 모듈을 훈련시킵니다.
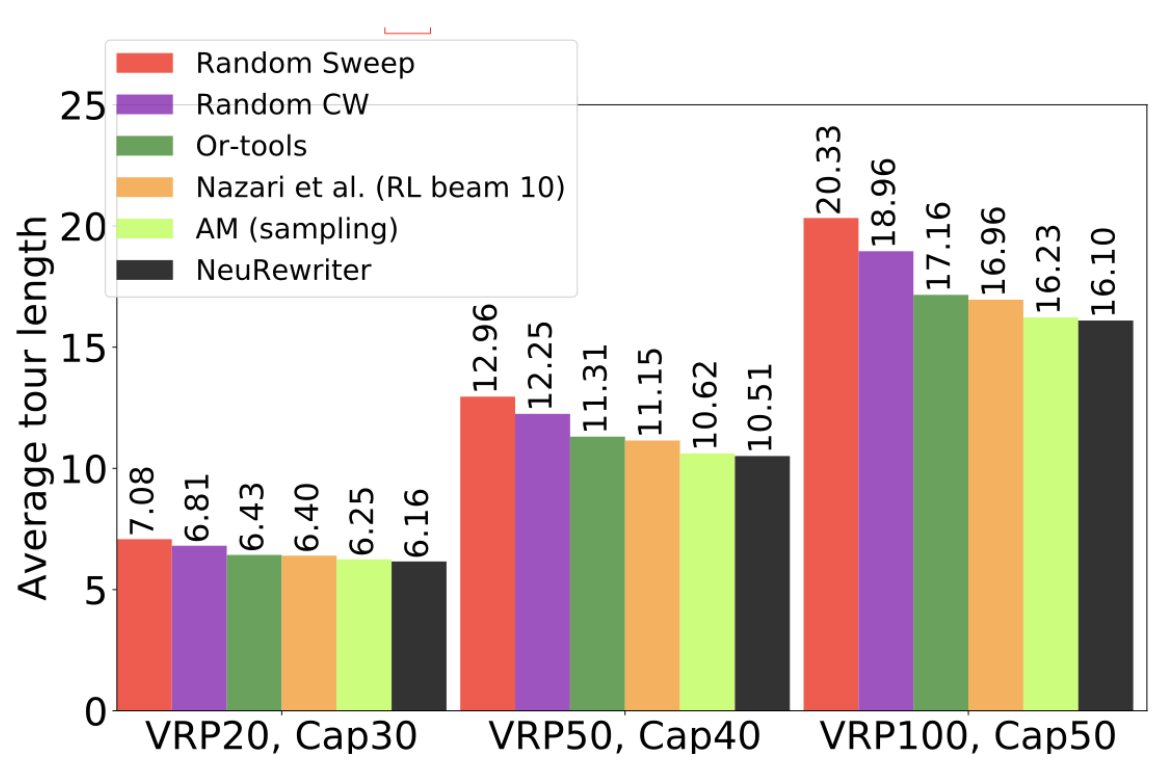
실험 결과는 아래와 같습니다. 다른 대조군보다 NeuRewriter가 더 성능이 좋음을 알 수 있습니다.