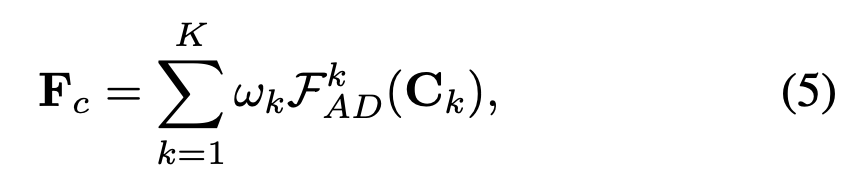Review on "T2I-Adapter"
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
를 읽고 짤막한 후기를 남깁니다.
1. 연구 배경
최근 대규모 Text-to-Image (T2I) Diffusion 모델 (예: Stable Diffusion, Imagen 등)은 풍부한 텍스처와 구조적 일관성을 갖춘 이미지를 생성할 수 있습니다. 그러나 텍스트 프롬프트만으로는 세밀한 제어(예: 색상, 구조)가 어렵고, 결과가 불안정하거나 사용자의 의도를 충실히 반영하지 못하는 한계가 있습니다.

2. 연구 목적
저자들은 T2I 모델이 이미 내재적으로 학습한 지식(색상, 구조, 의미)을 “끌어내어(dig out)” 활용하면, 별도의 모델 학습 없이도 세밀한 제어와 편집이 가능하다고 보았습니다. 따라서 본 논문은 T2I-Adapter라는 경량 어댑터 모듈을 제안하여, 대규모 모델은 고정한 채 외부 제어 조건과 내부 표현을 정렬(alignment)하는 방식을 제시합니다.
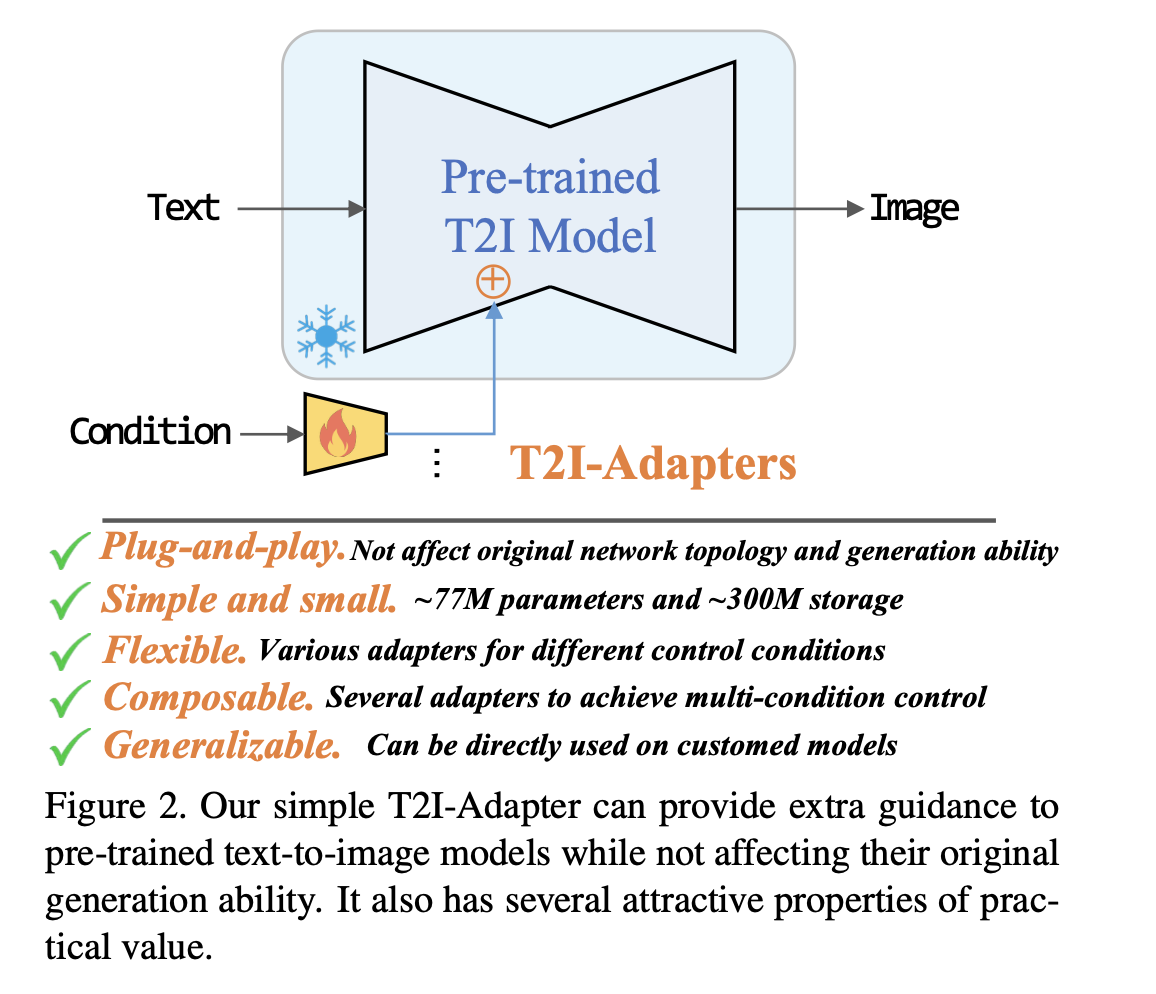
3. 방법론
(1) 아키텍처
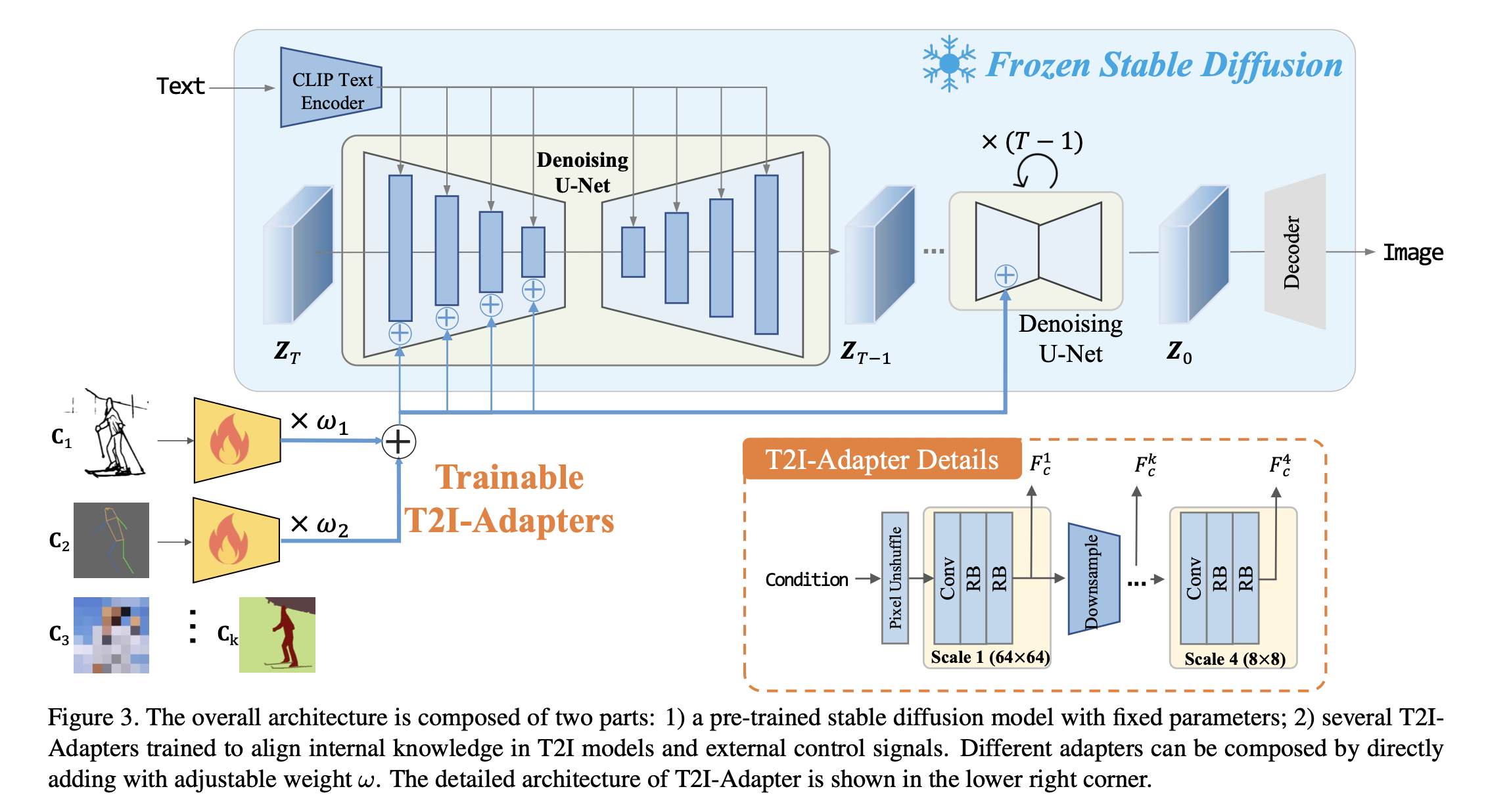
- Stable Diffusion을 기반으로, U-Net 인코더의 중간 feature와 condition feature를 결합.
- Condition 입력(스케치, 색상 팔레트, 키포즈, 세그멘테이션, 깊이맵 등)을 다단계 feature extractor로 처리 후 U-Net encoder feature에 더하는 방식.
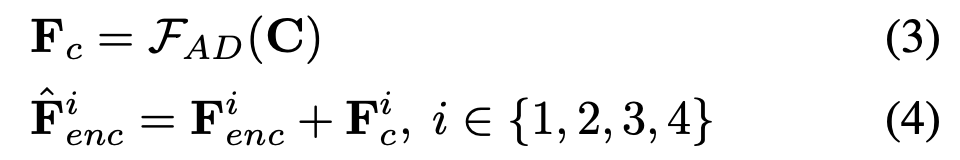
- Pixel unshuffle/downsampling을 이용해 다양한 해상도에서 feature를 추출하여 멀티스케일 정렬 수행.
(2) 최적화
- Stable Diffusion은 고정(frozen) 상태, Adapter만 학습.
- 학습 데이터: 이미지, 조건 맵, 텍스트 삼중쌍.
- Cubic sampling 전략으로 초기 denoising 단계의 학습 비중을 높여 제어 능력을 강화.
(3) 주요 특성
- Plug-and-play: 기존 T2I 구조를 바꾸지 않음.
- Lightweight: 약 77M 파라미터, ∼300MB 스토리지.
- Composable: 여러 Adapter를 조합해 다중 조건 제어 가능.
- Generalizable: SD v1.4에서 학습 후 SD v1.5나 커스텀 모델(Anything-v4.0 등)에 그대로 적용 가능.
4. 실험 및 결과
-
비교 대상: SPADE, OASIS, PITI, SD.
-
평가 지표: FID, CLIP Score.
-
결과: T2I-Adapter는 FID 및 CLIP Score 모두에서 기존 방법보다 우수하며, 특히 구조적 제어에서 높은 성능 달성.
-
응용 사례:
- 단일 Adapter 제어: 스케치 → 구조 제어, 팔레트 → 색상 제어.
- 조합 제어: 스케치+색상, 깊이+포즈 등.
- 부분 편집(Inpainting): 로컬 영역만 교체 가능.
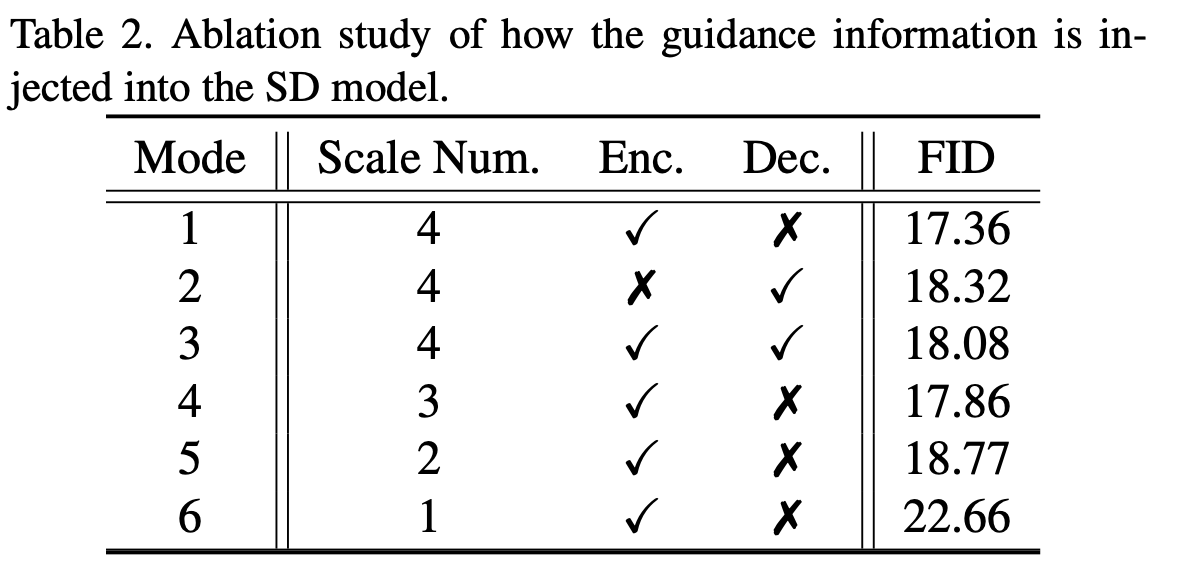
5. Ablation Study
- Injection 위치: Encoder에 삽입하는 것이 가장 효과적.
- 모델 크기: Base(77M), Small(18M), Tiny(5M) 모두 제어 능력 보유. Tiny 모델도 스케치 제어에서는 성능 유지.
- 다만, 다중 Adapter 조합 시 가중치 조절이 수동적이라는 한계가 존재.
6. 결론 및 의의
-
T2I-Adapter는 저비용·고효율의 경량 제어 모듈로, Stable Diffusion의 본래 생성 능력을 유지하면서 구조적·색채적 제어를 가능하게 합니다.
-
확장성: 다양한 조건 제어, 다중 조건 조합, 커스텀 모델 적용 가능.
-
한계: Multi-adapter 조합 시 가중치 튜닝 필요 → 향후 연구에서는 적응적 융합(adaptive fusion) 연구 필요.