Scalable Diffusion Models with Transformers를 읽고 DiT를 짚어보다.
1. 연구 배경
Diffusion Model은 최근 이미지 생성 분야의 새로운 표준으로 자리 잡았지만, 대부분 U-Net 구조를 backbone으로 사용해 왔습니다.
- U-Net은 convolution 기반의 inductive bias가 강하며, ResNet block + skip connection 중심 구조.
- 반면 Transformer는 NLP와 Vision 분야에서 scaling law를 증명하며, 모델 크기를 키울수록 성능이 향상되는 보편적 구조임이 밝혀졌습니다.
아래의 질문으로 시작된 논문이라고 볼 수 있습니다.
Diffusion Model에서도 U-Net이 필수적(inductive bias)인가? Transformer로 대체 가능할까?
2. 주요 기여
-
DiT (Diffusion Transformer) 제안
- Vision Transformer(ViT) 기반의 backbone을 diffusion에 적용.
- Latent Diffusion Framework (VAE latent 공간)에서 patchify → Transformer block 처리.
-
Transformer 적용을 위한 다양한 Design Pattern 정의
- In-context conditioning
- Cross-attention
- Adaptive LayerNorm (adaLN)
- adaLN-Zero (최종 최적 선택)
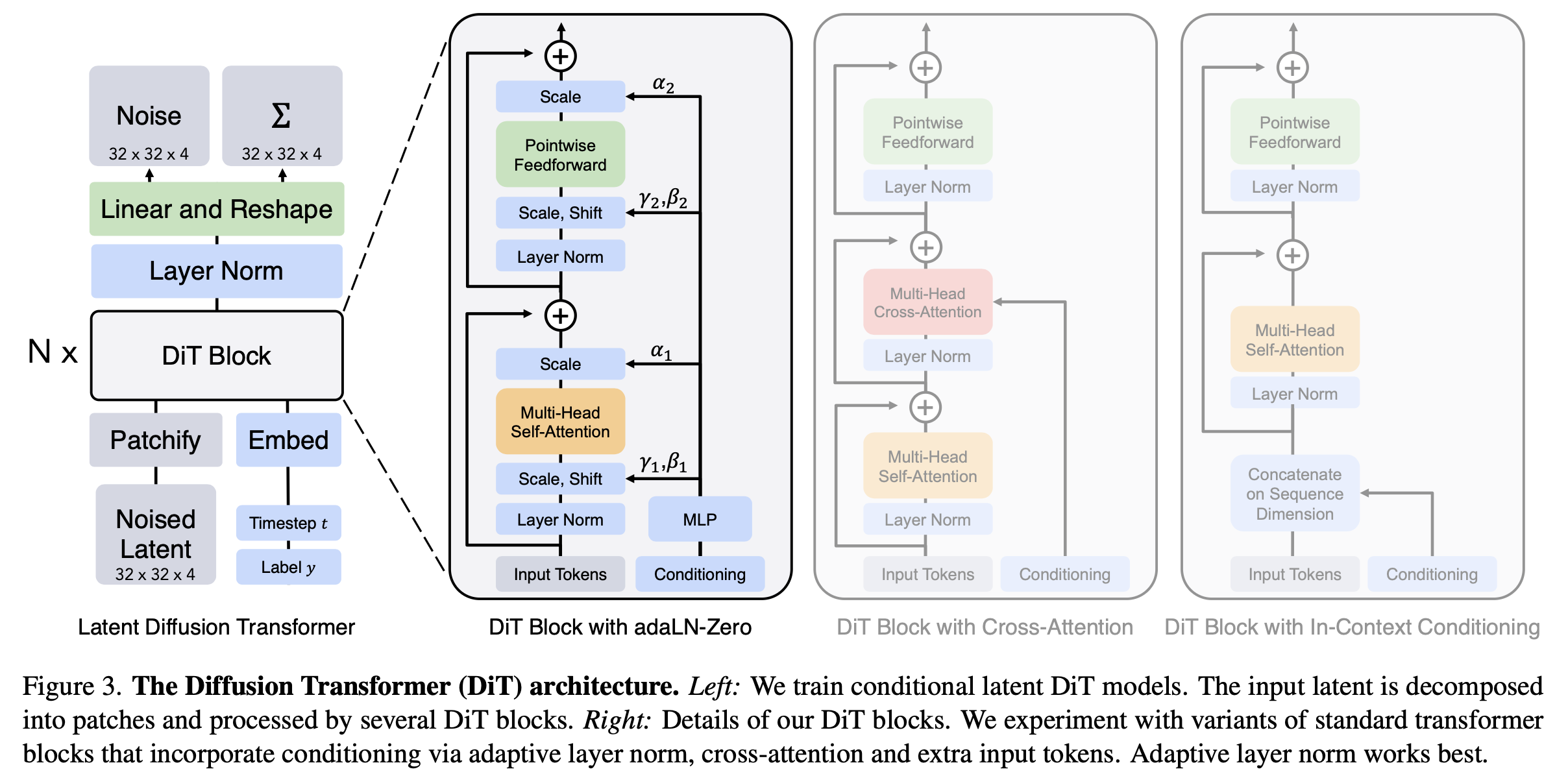
In-context conditioning은 가장 단순한 방법입니다. 조건 벡터(예: timestep, class label) 를 별도의 특별한 처리 없이 그냥 추가 토큰으로 붙입니다.
- 마치 ViT의
[CLS]토큰처럼 취급. - 입력 latent patch 시퀀스 뒤에 조건 토큰을 덧붙이고 Transformer block이 이를 자연스럽게 attention으로 활용하도록 둡니다.
- 장점: 단순하고 추가 연산량이 거의 없음.
- 단점: 조건 정보가 직접적으로 활용되기 어렵고 성능이 떨어짐.
Cross-attention은 조건 벡터들을 별도의 시퀀스(예: label, timestep 임베딩) 로 두고, Transformer block 내에 cross-attention 모듈을 삽입합니다.
- 즉, 이미지 latent 토큰들(2-tokens 체제)이 조건 토큰 시퀀스를 key, value로 하여 cross-attention을 수행.
- 이는 LDM(Latent Diffusion)이나 텍스트 조건부 diffusion에서 자주 쓰이는 방식.
- 장점: 조건이 직접적으로 각 토큰에 주입됨 → 성능이 좋음.
- 단점: cross-attention 레이어가 추가되므로 연산량이 증가(약 15% overhead).
Adaptive LayerNorm (adaLN)은 기존 LayerNorm을 조건부 형태로 바꾼 방식입니다.
- 보통 LayerNorm은 각 채널에 대해 scale(γ), shift(β) 파라미터를 학습합니다.
- adaLN에서는 이 γ, β를 조건 임베딩(예: label, timestep)으로부터 회귀(regress)해서 생성합니다.
- 따라서 모델은 입력마다 다른 normalization을 수행할 수 있어 조건 정보를 효과적으로 반영.
- 장점: 추가 연산이 거의 없고, 효율적.
- 단점: 모든 토큰에 동일한 γ, β가 적용되므로 세밀한 제어는 어렵습니다.
adaLN-Zero의 경우 adaLN을 개선한 버전으로, Residual block을 처음에는 identity function으로 초기화하는 전략을 결합합니다.
- 즉, 조건 기반 γ, β 외에 추가로 scaling 계수 α를 회귀하여 residual connection 앞에 곱해줌.
- 초기에는 α=0으로 설정해 각 block이 단순히 입력을 그대로 전달(identity)하도록 두고, 학습을 통해 점진적으로 조건 효과가 켜지도록 설계.
- 장점: 안정적 학습, 빠른 수렴, 성능 최고.
- 실제 DiT 논문에서는 이 방식이 FID를 가장 낮게 달성하며 최종적으로 채택.
-
Scaling Law 분석
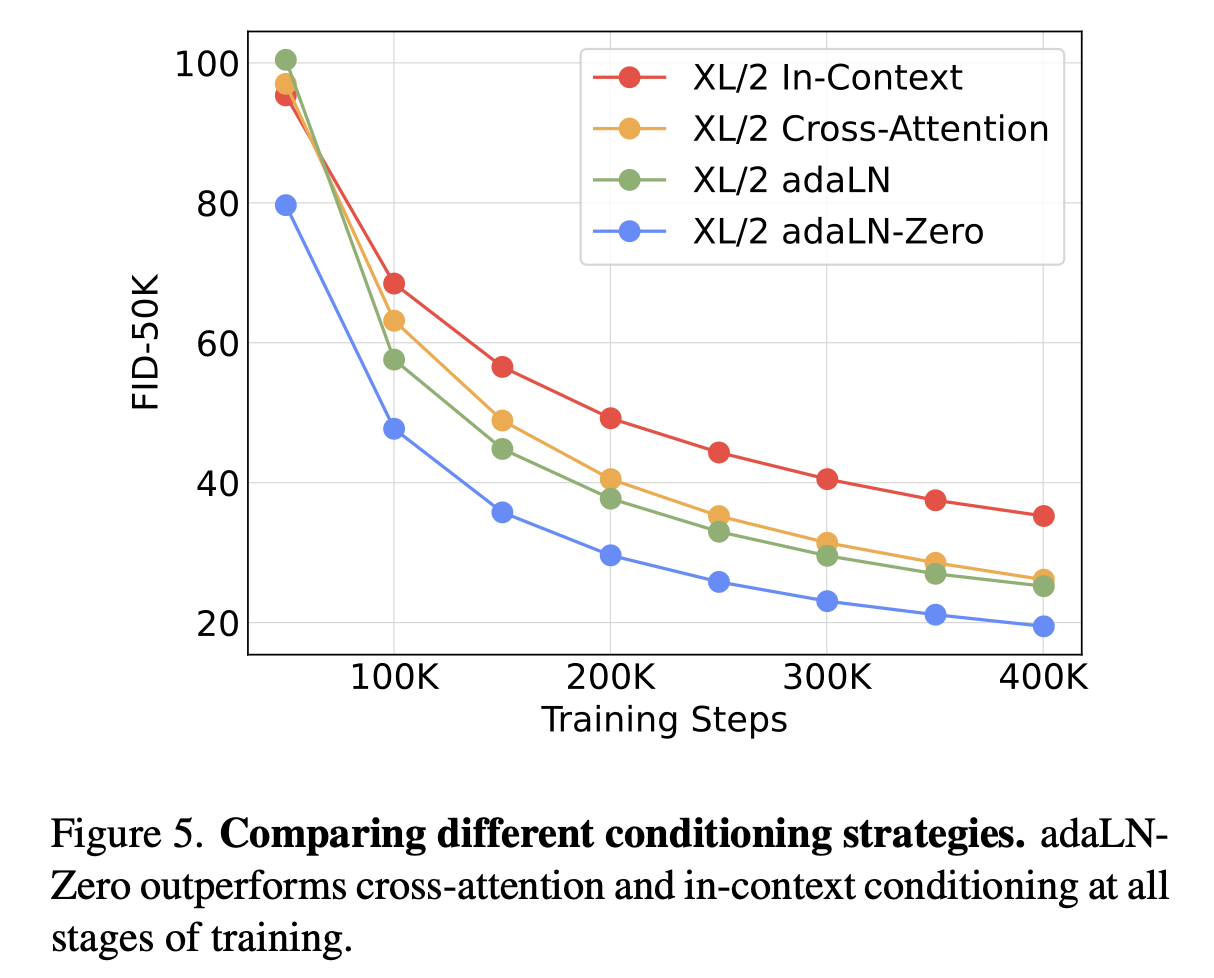
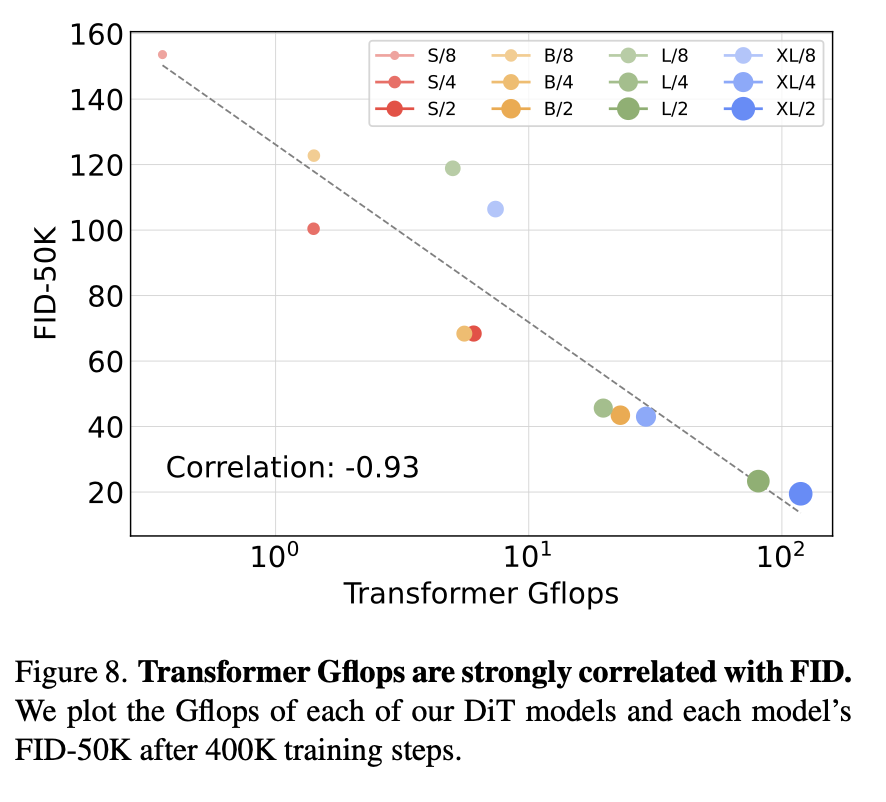
- FLOPs 증가 ↔ FID 감소 (-0.93 상관관계)
- 파라미터 수보다는 연산량(Gflops)이 성능을 결정한다는 점을 강조.
-
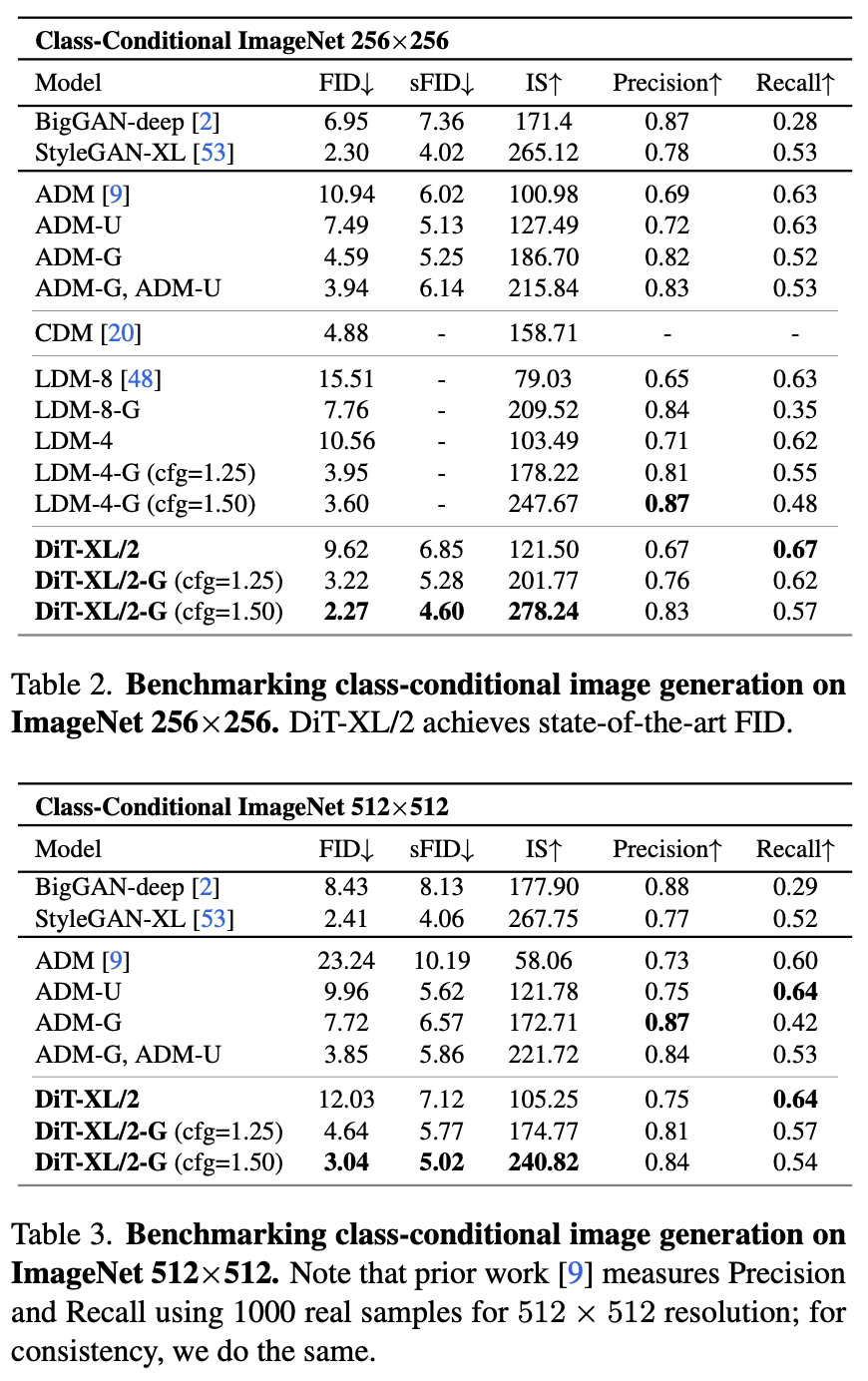
최신 SOTA 달성
- ImageNet 256×256: FID 2.27 (LDM 3.60, StyleGAN-XL 2.30보다 우수)
- ImageNet 512×512: FID 3.04로 ADM-G/U 대비 우월한 성능 달성.
3. 실험적 관찰
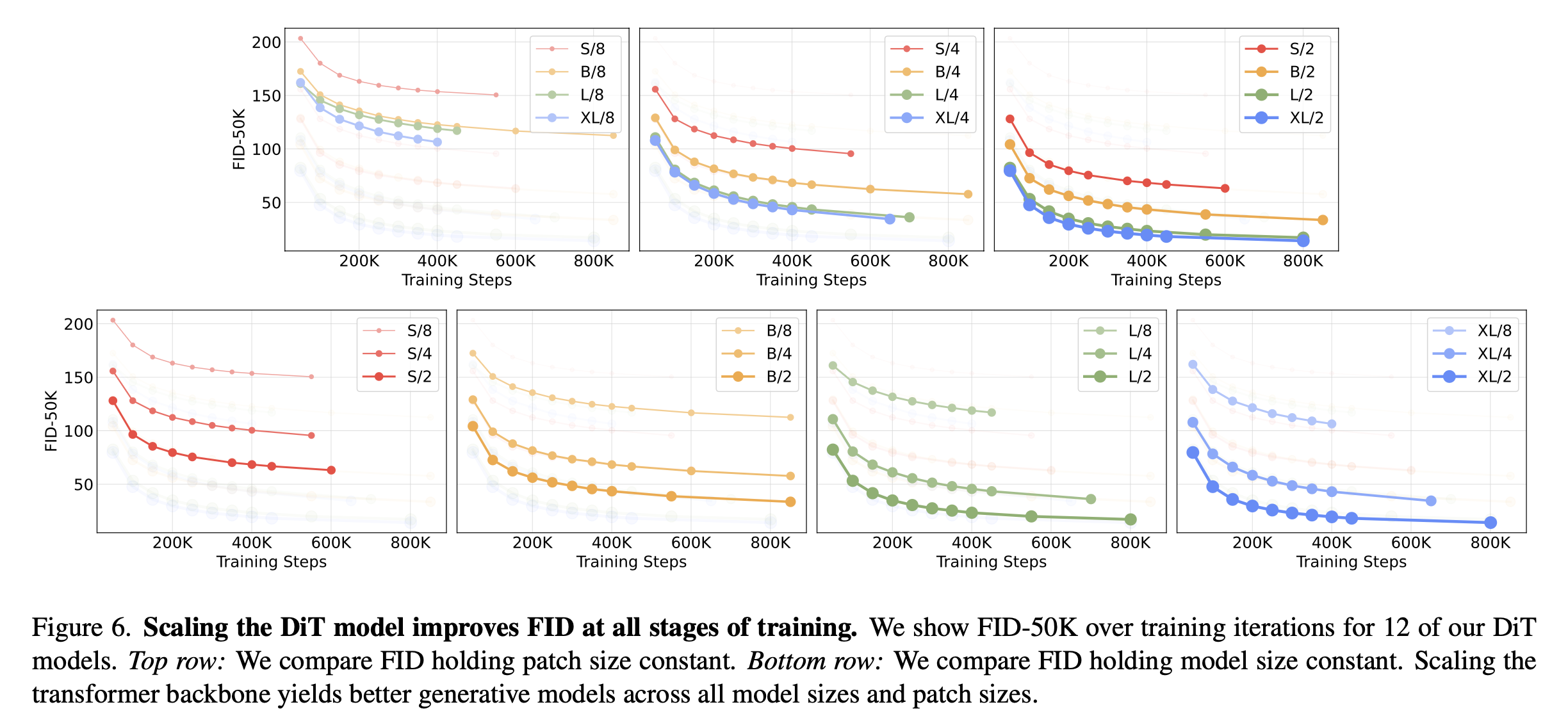
1. Scaling Model Size and Patch Size
논문에서는 총 12개의 DiT 변형(S, B, L, XL × patch size 8/4/2)을 학습시키며 스케일링 효과를 정량적으로 분석했습니다.

-
모델 크기 증가 (depth/width 확대)
- Transformer block 수와 hidden dimension, head 수를 늘리면 FID가 꾸준히 감소.
- 즉, 더 깊고 넓은 모델일수록 generative 성능이 향상됨.
-
패치 크기 축소 (patchify granularity 증가)
- patch size p를 줄이면 입력 시퀀스 토큰 수가 늘어나면서 Gflops 증가.
- 같은 모델 크기에서도 더 많은 토큰을 처리 → 더 세밀한 표현 학습 → 성능 개선.
-
핵심 관찰
- 파라미터 수(Params)만 늘려서는 충분하지 않음.
- 오히려 연산량(Gflops) 이 성능과 직접적으로 강한 음의 상관(-0.93)을 가짐.
- 예: DiT-S/2와 DiT-B/4는 파라미터 수가 다르지만, Gflops가 비슷하면 성능도 유사.
"Scaling FLOPs, not just parameters, is the key to improving diffusion transformers."
2. Larger DiT Models Use Large Compute More Efficiently
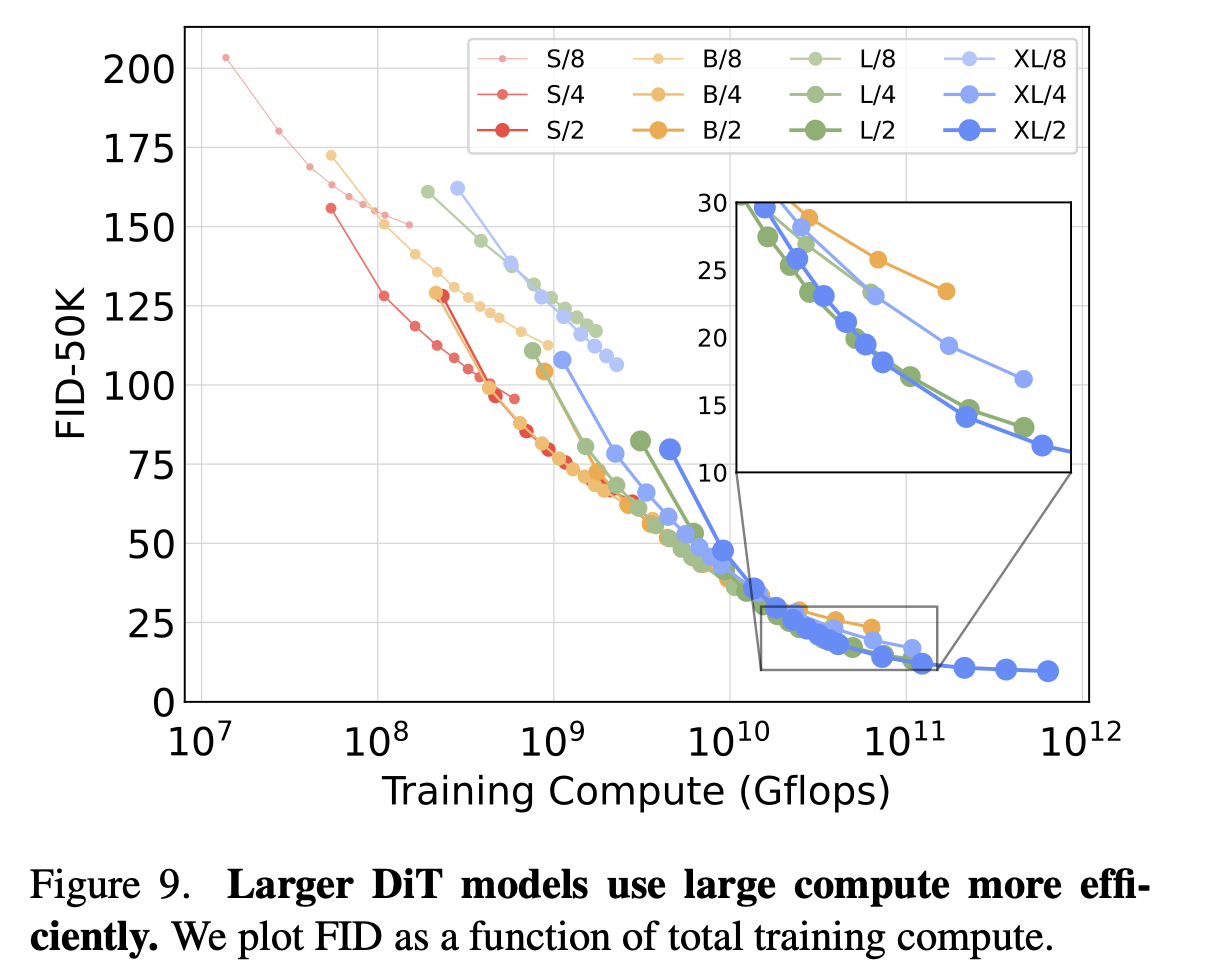
연산량이 늘어난다고 항상 좋은 건 아닙니다. 중요한 건 compute efficiency 입니다.
- 작은 모델(S, B) 은 학습을 오래 시켜도 일정 시점 이후에는 성능이 포화.
- 큰 모델(L, XL) 은 동일한 총 compute budget[Gflops·batch size·training steps·3](예: 10¹⁰ Gflops) 내에서 더 낮은 FID를 달성.
- 즉, 큰 모델일수록 같은 계산 자원을 더 효율적으로 사용합니다.
이는 언어 모델의 scaling law (Kaplan et al., 2020)와 유사한 패턴을 보여주며, diffusion에서도 "큰 모델이 효율적"임을 입증합니다.
3. Scaling Model vs. Scaling Sampling Compute
Diffusion은 inference 시 sampling step 수를 늘리면 추가적인 compute를 투입할 수 있습니다. 그렇다면 작은 모델 + 많은 sampling step이 큰 모델 + 적은 step을 따라잡을 수 있을까요?
- 실험 결과:
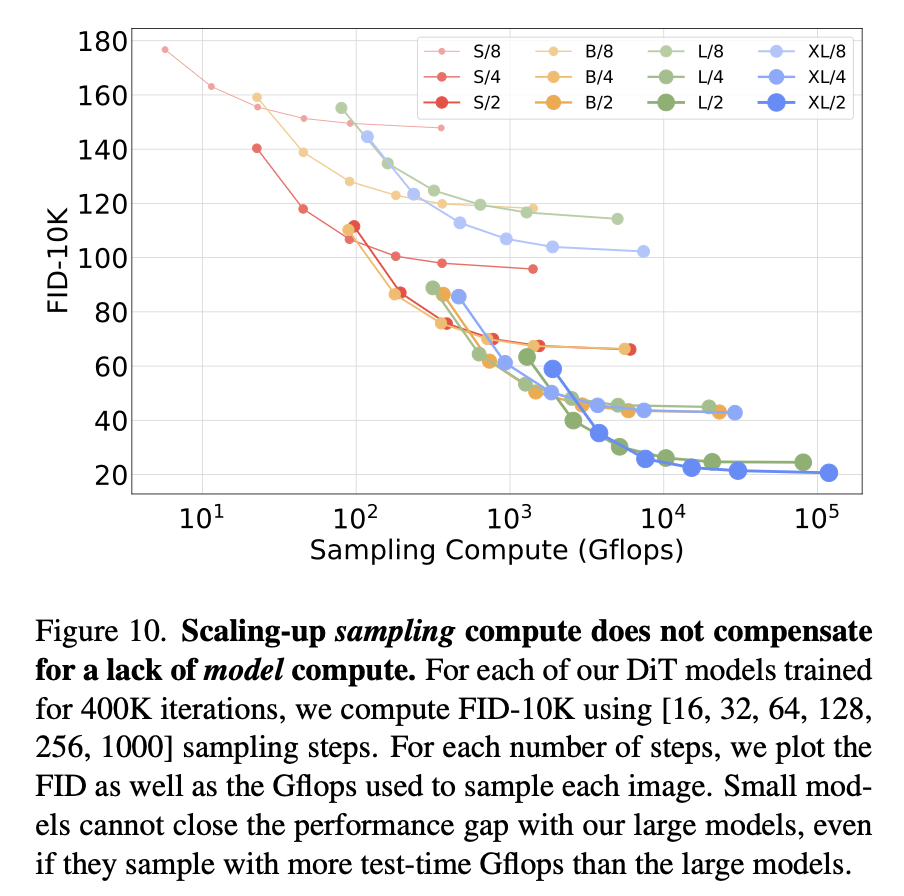
-
DiT-L/2, 1000 sampling step (80.7 TFlops)
-
DiT-XL/2, 128 step (15.2 TFlops)
-
→ XL/2가 5배 적은 compute를 쓰면서도 더 좋은 FID (23.7 vs 25.9)
-
결론:
- sampling step을 늘려서 얻는 이득은 제한적
- 모델 자체의 compute capacity (Gflops)가 성능을 결정
Takeaway: "추가적인 sampling compute는 모델 compute 부족을 대체할 수 없다."
--
